 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextNet: Irregular Text Reading from Images with an End-to-End Trainable Network
Paper and Code
Dec 24, 2018

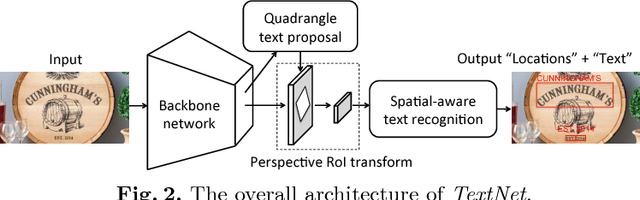
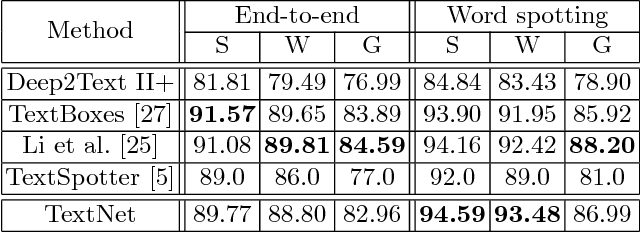
Reading text from images remains challenging due to multi-orientation, perspective distortion and especially the curved nature of irregular text. Most of existing approaches attempt to solve the problem in two or multiple stages, which is considered to be the bottleneck to optimize the overall performance. To address this issue, we propose an end-to-end trainable network architecture, named TextNet, which is able to simultaneously localize and recognize irregular text from images. Specifically, we develop a scale-aware attention mechanism to learn multi-scale image features as a backbone network, sharing fully convolutional features and computation for localization and recognition. In text detection branch, we directly generate text proposals in quadrangles, covering oriented, perspective and curved text regions. To preserve text features for recognition, we introduce a perspective RoI transform layer, which can align quadrangle proposals into small feature maps. Furthermore, in order to extract effective features for recognition, we propose to encode the aligned RoI features by RNN into context information, combining spatial attention mechanism to generate text sequences. This overall pipeline is capable of handling both regular and irregular cases. Finally, text localization and recognition tasks can be jointly trained in an end-to-end fashion with designed multi-task loss. Experiments on standard benchmarks show that the proposed TextNet can achieve state-of-the-art performance, and outperform existing approaches on irregular datasets by a large margin.