 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStNet: Local and Global Spatial-Temporal Modeling for Action Recognition
Paper and Code

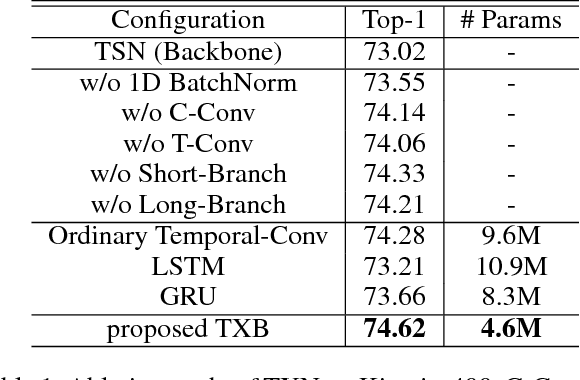
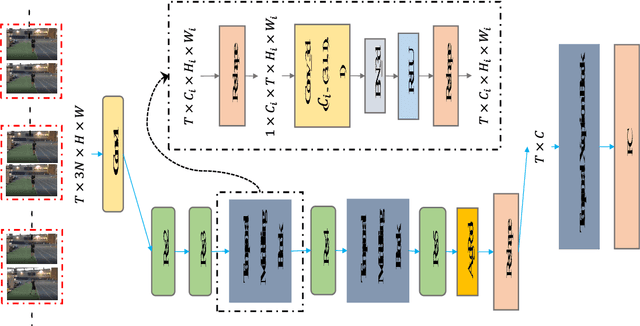
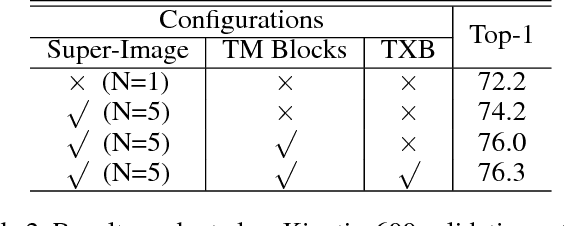
Despite the success of deep learning for static image understanding, it remains unclear what are the most effective network architectures for the spatial-temporal modeling in videos. In this paper, in contrast to the existing CNN+RNN or pure 3D convolution based approaches, we explore a novel spatial temporal network (StNet) architecture for both local and global spatial-temporal modeling in videos. Particularly, StNet stacks N successive video frames into a \emph{super-image} which has 3N channels and applies 2D convolution on super-images to capture local spatial-temporal relationship. To model global spatial-temporal relationship, we apply temporal convolution on the local spatial-temporal feature maps. Specifically, a novel temporal Xception block is proposed in StNet. It employs a separate channel-wise and temporal-wise convolution over the feature sequence of video. Extensive experiments on the Kinetics dataset demonstrate that our framework outperforms several state-of-the-art approaches in action recognition and can strike a satisfying trade-off between recognition accuracy and model complexity. We further demonstrate the generalization performance of the leaned video representations on the UCF101 dataset.