 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Fine-grained Quantization for Deep Neural Network Compression
Paper and Code
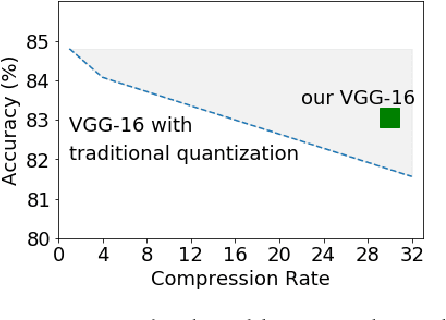
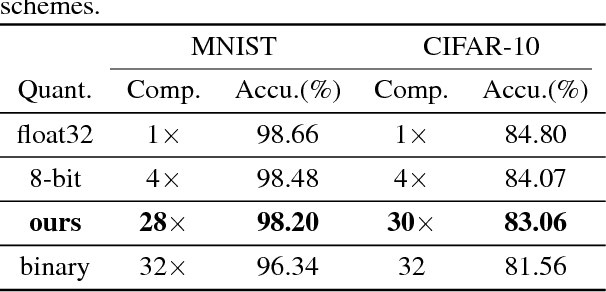

Neural networks have shown great performance in cognitive tasks. When deploying network models on mobile devices with limited resources, weight quantization has been widely adopted. Binary quantization obtains the highest compression but usually results in big accuracy drop. In practice, 8-bit or 16-bit quantization is often used aiming at maintaining the same accuracy as the original 32-bit precision. We observe different layers have different accuracy sensitivity of quantization. Thus judiciously selecting different precision for different layers/structures can potentially produce more efficient models compared to traditional quantization methods by striking a better balance between accuracy and compression rate. In this work, we propose a fine-grained quantization approach for deep neural network compression by relaxing the search space of quantization bitwidth from discrete to a continuous domain. The proposed approach applies gradient descend based optimization to generate a mixed-precision quantization scheme that outperforms the accuracy of traditional quantization methods under the same compression rate.