 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit State Tracking with Semi-Supervision for Neural Dialogue Generation
Paper and Code

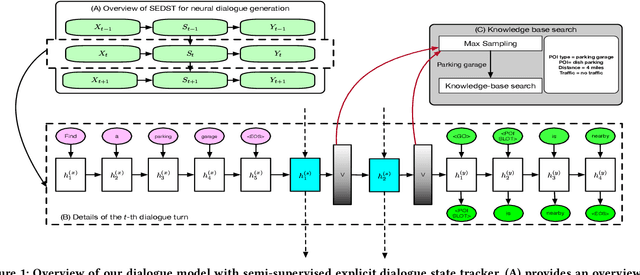
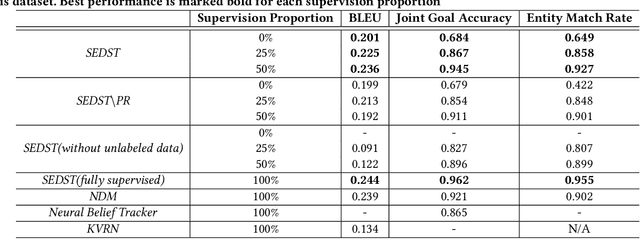
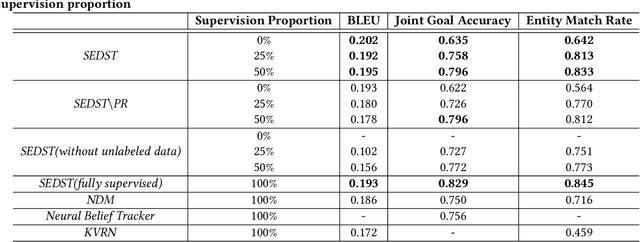
The task of dialogue generation aims to automatically provide responses given previous utterances. Tracking dialogue states is an important ingredient in dialogue generation for estimating users' intention. However, the \emph{expensive nature of state labeling} and the \emph{weak interpretability} make the dialogue state tracking a challenging problem for both task-oriented and non-task-oriented dialogue generation: For generating responses in task-oriented dialogues, state tracking is usually learned from manually annotated corpora, where the human annotation is expensive for training; for generating responses in non-task-oriented dialogues, most of existing work neglects the explicit state tracking due to the unlimited number of dialogue states. In this paper, we propose the \emph{semi-supervised explicit dialogue state tracker} (SEDST) for neural dialogue generation. To this end, our approach has two core ingredients: \emph{CopyFlowNet} and \emph{posterior regularization}. Specifically, we propose an encoder-decoder architecture, named \emph{CopyFlowNet}, to represent an explicit dialogue state with a probabilistic distribution over the vocabulary space. To optimize the training procedure, we apply a posterior regularization strategy to integrate indirect supervision. Extensive experiments conducted on both task-oriented and non-task-oriented dialogue corpora demonstrate the effectiveness of our proposed model. Moreover, we find that our proposed semi-supervised dialogue state tracker achieves a comparable performance as state-of-the-art supervised learning baselines in state tracking procedure.