 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAM-ADMM: A Unified, Systematic Framework of Structured Weight Pruning for DNNs
Paper and Code
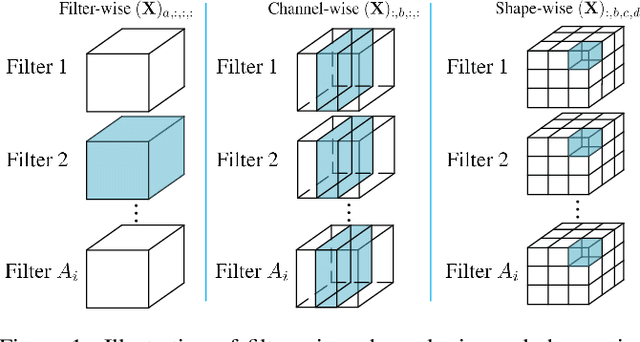

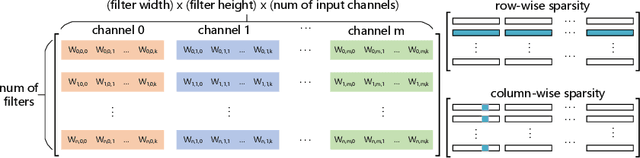
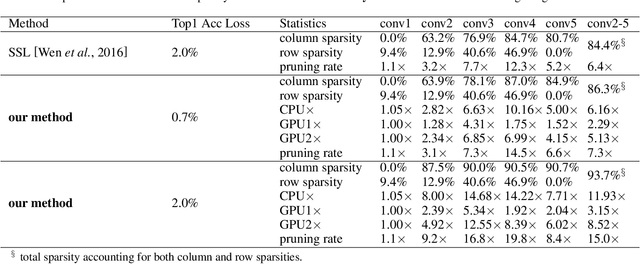
Weight pruning methods of deep neural networks (DNNs) have been demonstrated to achieve a good model pruning ratio without loss of accuracy, thereby alleviating the significant computation/storage requirements of large-scale DNNs. Structured weight pruning methods have been proposed to overcome the limitation of irregular network structure and demonstrated actual GPU acceleration. However, the pruning ratio (degree of sparsity) and GPU acceleration are limited (to less than 50%) when accuracy needs to be maintained. In this work, we overcome pruning ratio and GPU acceleration limitations by proposing a unified, systematic framework of structured weight pruning for DNNs, named ADAM-ADMM (Adaptive Moment Estimation-Alternating Direction Method of Multipliers). It is a framework that can be used to induce different types of structured sparsity, such as filter-wise, channel-wise, and shape-wise sparsity, as well non-structured sparsity. The proposed framework incorporates stochastic gradient descent with ADMM, and can be understood as a dynamic regularization method in which the regularization target is analytically updated in each iteration. A significant improvement in weight pruning ratio is achieved without loss of accuracy, along with fast convergence rate. With a small sparsity degree of 33% on the convolutional layers, we achieve 1.64% accuracy enhancement for the AlexNet (CaffeNet) model. This is obtained by mitigation of overfitting. Without loss of accuracy on the AlexNet model, we achieve 2.6 times and 3.65 times average measured speedup on two GPUs, clearly outperforming the prior work. The average speedups reach 2.77 times and 7.5 times when allowing a moderate accuracy loss of 2%. In this case the model compression for convolutional layers is 13.2 times, corresponding to 10.5 times CPU speedup. Our models and codes are released at https://github.com/KaiqiZhang/ADAM-ADMM