 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Approximation Framework for Deep Neural Networks
Paper and Code
Jul 27, 2018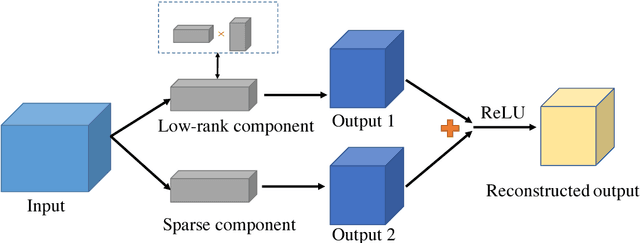
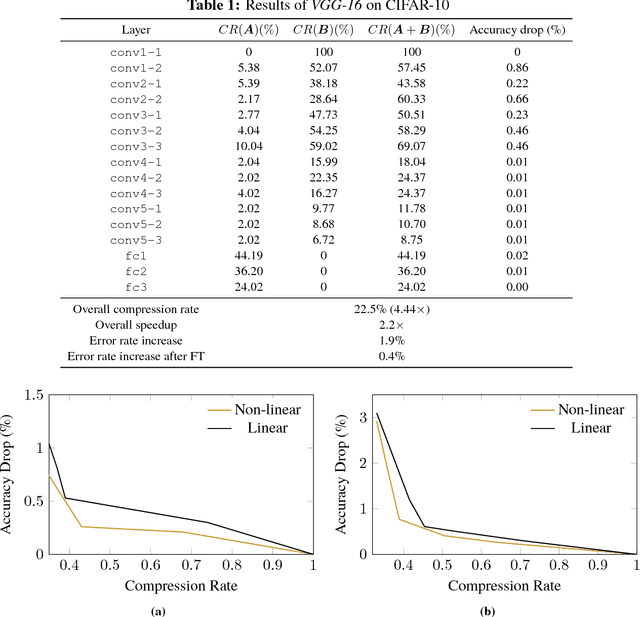
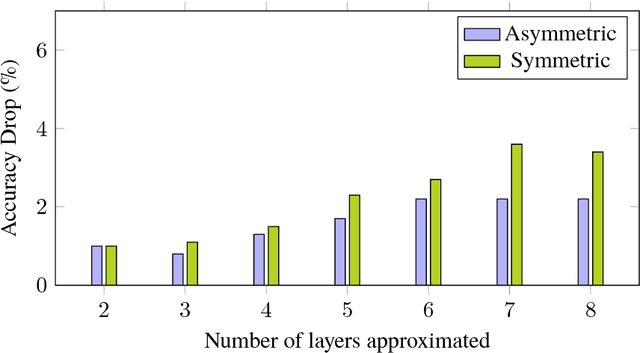
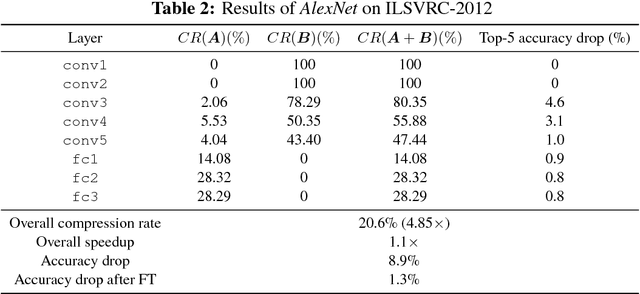
Deep neural networks (DNNs) have achieved significant success in a variety of real world applications. However, tons of parameters in the networks restrict the efficiency of neural networks due to the large model size and the intensive computation. To address this issue, various compression and acceleration techniques have been investigated, among which low-rank filters and sparse filters are heavily studied. In this paper we propose a unified framework to compress the convolutional neural networks by combining these two strategies, while taking the nonlinear activation into consideration. The filer of a layer is approximated by the sum of a sparse component and a low-rank component, both of which are in favor of model compression. Especially, we constrain the sparse component to be structured sparse which facilitates acceleration. The performance of the network is retained by minimizing the reconstruction error of the feature maps after activation of each layer, using the alternating direction method of multipliers (ADMM). The experimental results show that our proposed approach can compress VGG-16 and AlexNet by over 4X. In addition, 2.2X and 1.1X speedup are achieved on VGG-16 and AlexNet, respectively, at a cost of less increase on error rate.