 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-based Sign Language Recognition without Temporal Segmentation
Paper and Code
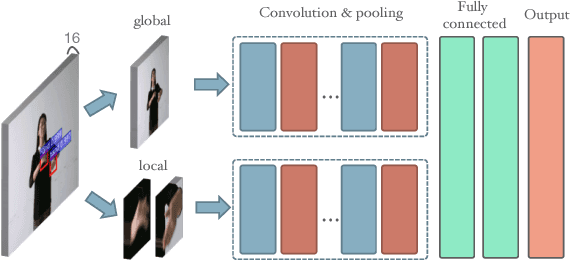
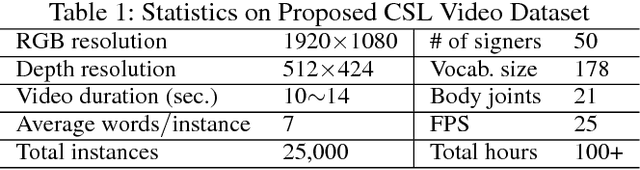
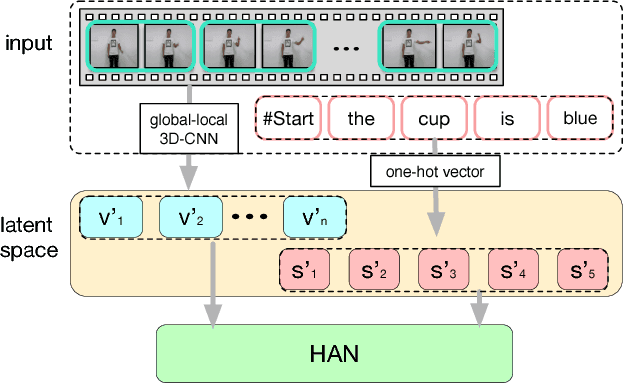
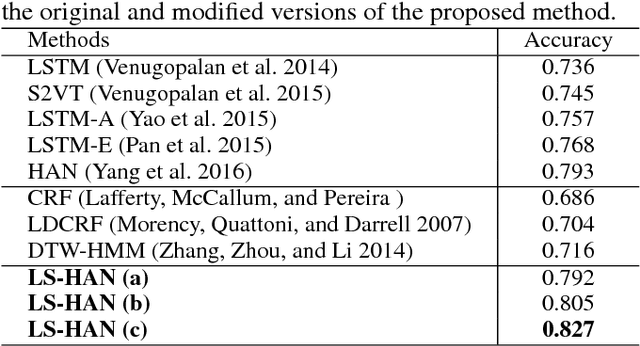
Millions of hearing impaired people around the world routinely use some variants of sign languages to communicate, thus the automatic translation of a sign language is meaningful and important. Currently, there are two sub-problems in Sign Language Recognition (SLR), i.e., isolated SLR that recognizes word by word and continuous SLR that translates entire sentences. Existing continuous SLR methods typically utilize isolated SLRs as building blocks, with an extra layer of preprocessing (temporal segmentation) and another layer of post-processing (sentence synthesis). Unfortunately, temporal segmentation itself is non-trivial and inevitably propagates errors into subsequent steps. Worse still, isolated SLR methods typically require strenuous labeling of each word separately in a sentence, severely limiting the amount of attainable training data. To address these challenges, we propose a novel continuous sign recognition framework, the Hierarchical Attention Network with Latent Space (LS-HAN), which eliminates the preprocessing of temporal segmentation. The proposed LS-HAN consists of three components: a two-stream Convolutional Neural Network (CNN) for video feature representation generation, a Latent Space (LS) for semantic gap bridging, and a Hierarchical Attention Network (HAN) for latent space based recognition. Experiments are carried out on two large scale datasets. Experimental results demonstrate the effectiveness of the proposed framework.