 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Need for a Lexicon? Evaluating the Value of the Pronunciation Lexica in End-to-End Models
Paper and Code
Dec 05, 2017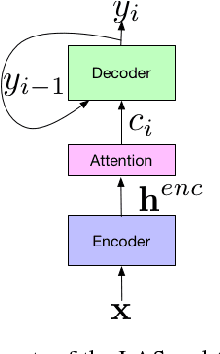


For decades, context-dependent phonemes have been the dominant sub-word unit for conventional acoustic modeling systems. This status quo has begun to be challenged recently by end-to-end models which seek to combine acoustic, pronunciation, and language model components into a single neural network. Such systems, which typically predict graphemes or words, simplify the recognition process since they remove the need for a separate expert-curated pronunciation lexicon to map from phoneme-based units to words. However, there has been little previous work comparing phoneme-based versus grapheme-based sub-word units in the end-to-end modeling framework, to determine whether the gains from such approaches are primarily due to the new probabilistic model, or from the joint learning of the various components with grapheme-based units. In this work, we conduct detailed experiments which are aimed at quantifying the value of phoneme-based pronunciation lexica in the context of end-to-end models. We examine phoneme-based end-to-end models, which are contrasted against grapheme-based ones on a large vocabulary English Voice-search task, where we find that graphemes do indeed outperform phonemes. We also compare grapheme and phoneme-based approaches on a multi-dialect English task, which once again confirm the superiority of graphemes, greatly simplifying the system for recognizing multiple dialects.