 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Higher Order LSTM Have Better Accuracy for Segmenting and Labeling Sequence Data?
Paper and Code
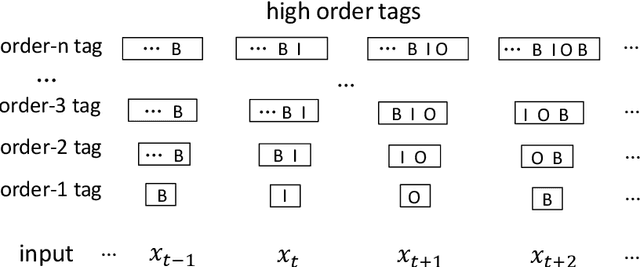
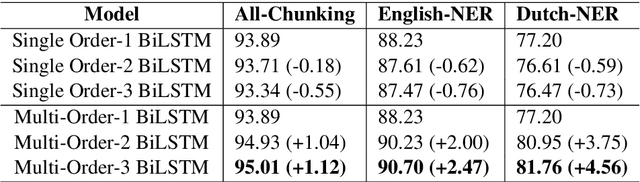

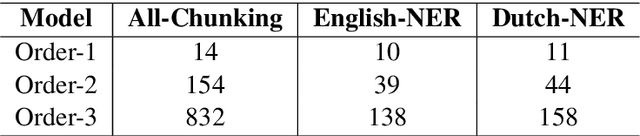
Existing neural models usually predict the tag of the current token independent of the neighboring tags. The popular LSTM-CRF model considers the tag dependencies between every two consecutive tags. However, it is hard for existing neural models to take longer distance dependencies of tags into consideration. The scalability is mainly limited by the complex model structures and the cost of dynamic programming during training. In our work, we first design a new model called "high order LSTM" to predict multiple tags for the current token which contains not only the current tag but also the previous several tags. We call the number of tags in one prediction as "order". Then we propose a new method called Multi-Order BiLSTM (MO-BiLSTM) which combines low order and high order LSTMs together. MO-BiLSTM keeps the scalability to high order models with a pruning technique. We evaluate MO-BiLSTM on all-phrase chunking and NER datasets. Experiment results show that MO-BiLSTM achieves the state-of-the-art result in chunking and highly competitive results in two NER datasets.