 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptionGAN: Learning Joint Reward-Policy Options using Generative Adversarial Inverse Reinforcement Learning
Paper and Code
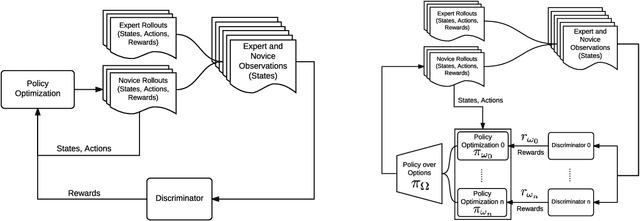

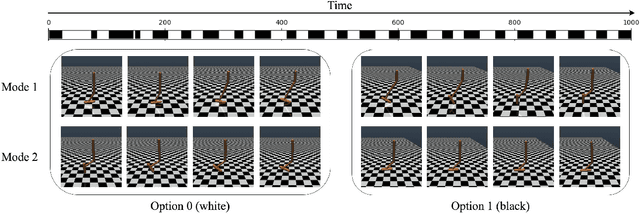
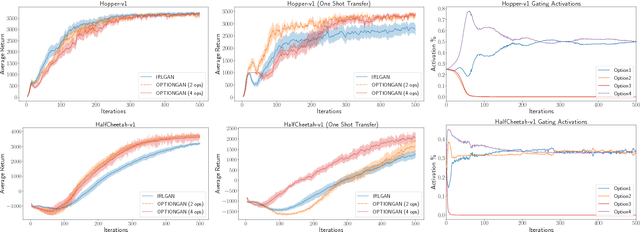
Reinforcement learning has shown promise in learning policies that can solve complex problems. However, manually specifying a good reward function can be difficult, especially for intricate tasks. Inverse reinforcement learning offers a useful paradigm to learn the underlying reward function directly from expert demonstrations. Yet in reality, the corpus of demonstrations may contain trajectories arising from a diverse set of underlying reward functions rather than a single one. Thus, in inverse reinforcement learning, it is useful to consider such a decomposition. The options framework in reinforcement learning is specifically designed to decompose policies in a similar light. We therefore extend the options framework and propose a method to simultaneously recover reward options in addition to policy options. We leverage adversarial methods to learn joint reward-policy options using only observed expert states. We show that this approach works well in both simple and complex continuous control tasks and shows significant performance increases in one-shot transfer learning.