 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modality Fusion based on Consensus-Voting and 3D Convolution for Isolated Gesture Recognition
Paper and Code
Nov 28, 2016
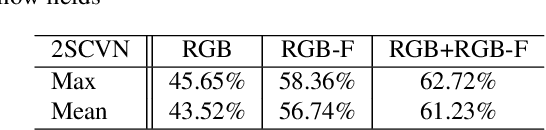
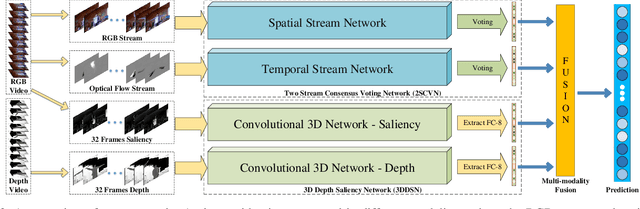
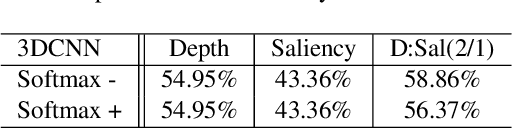
Recently, the popularity of depth-sensors such as Kinect has made depth videos easily available while its advantages have not been fully exploited. This paper investigates, for gesture recognition, to explore the spatial and temporal information complementarily embedded in RGB and depth sequences. We propose a convolutional twostream consensus voting network (2SCVN) which explicitly models both the short-term and long-term structure of the RGB sequences. To alleviate distractions from background, a 3d depth-saliency ConvNet stream (3DDSN) is aggregated in parallel to identify subtle motion characteristics. These two components in an unified framework significantly improve the recognition accuracy. On the challenging Chalearn IsoGD benchmark, our proposed method outperforms the first place on the leader-board by a large margin (10.29%) while also achieving the best result on RGBD-HuDaAct dataset (96.74%). Both quantitative experiments and qualitative analysis shows the effectiveness of our proposed framework and codes will be released to facilitate future research.