 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation with Pivot Languages
Paper and Code
Feb 21, 2017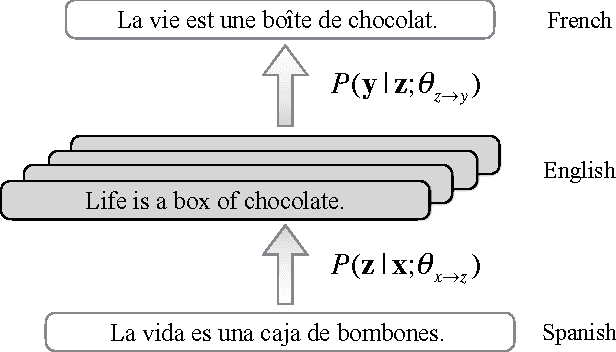
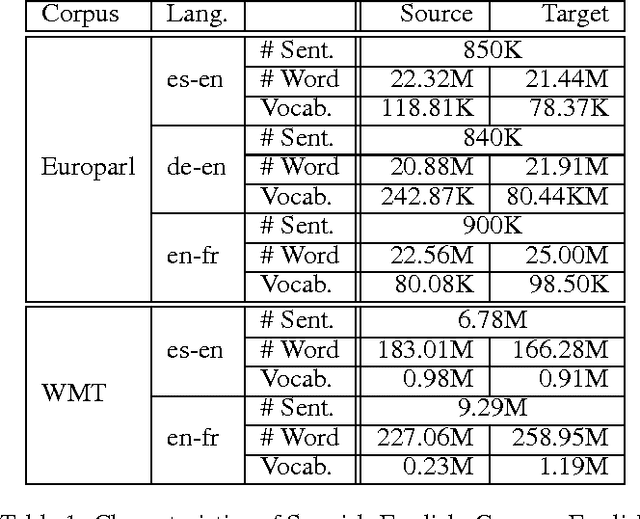
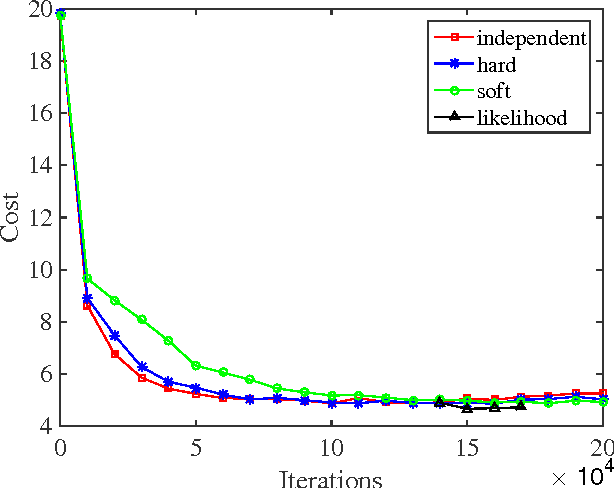
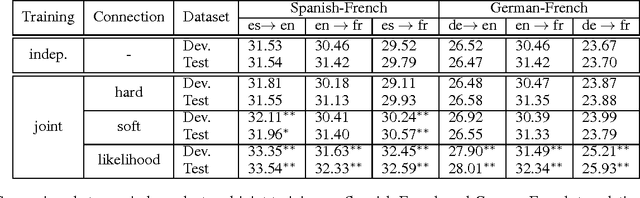
While recent neural machine translation approaches have delivered state-of-the-art performance for resource-rich language pairs, they suffer from the data scarcity problem for resource-scarce language pairs. Although this problem can be alleviated by exploiting a pivot language to bridge the source and target languages, the source-to-pivot and pivot-to-target translation models are usually independently trained. In this work, we introduce a joint training algorithm for pivot-based neural machine translation. We propose three methods to connect the two models and enable them to interact with each other during training. Experiments on Europarl and WMT corpora show that joint training of source-to-pivot and pivot-to-target models leads to significant improvements over independent training across various languages.