 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation Advised by Statistical Machine Translation
Paper and Code
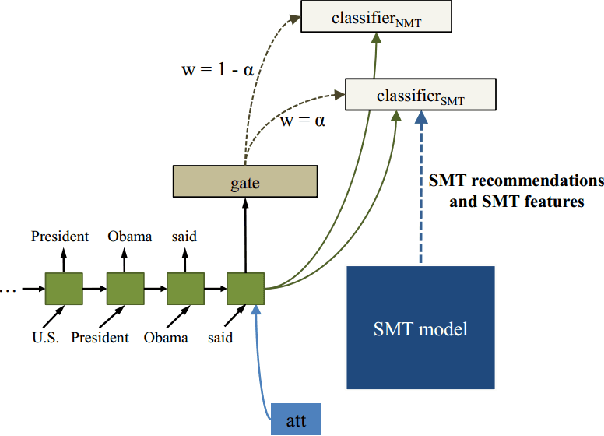
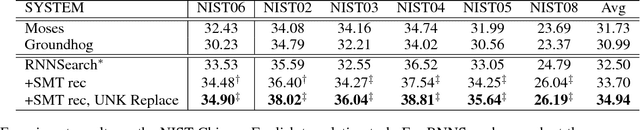
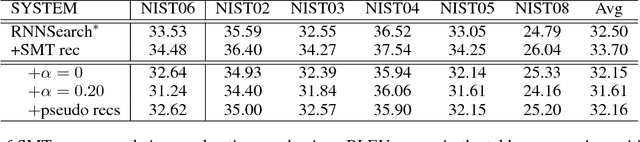
Neural Machine Translation (NMT) is a new approach to machine translation that has made great progress in recent years. However, recent studies show that NMT generally produces fluent but inadequate translations (Tu et al. 2016b; Tu et al. 2016a; He et al. 2016; Tu et al. 2017). This is in contrast to conventional Statistical Machine Translation (SMT), which usually yields adequate but non-fluent translations. It is natural, therefore, to leverage the advantages of both models for better translations, and in this work we propose to incorporate SMT model into NMT framework. More specifically, at each decoding step, SMT offers additional recommendations of generated words based on the decoding information from NMT (e.g., the generated partial translation and attention history). Then we employ an auxiliary classifier to score the SMT recommendations and a gating function to combine the SMT recommendations with NMT generations, both of which are jointly trained within the NMT architecture in an end-to-end manner. Experimental results on Chinese-English translation show that the proposed approach achieves significant and consistent improvements over state-of-the-art NMT and SMT systems on multiple NIST test sets.