 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human Activity Recognition with Reconfigurable Convolutional Neural Networks
Paper and Code
Feb 01, 2015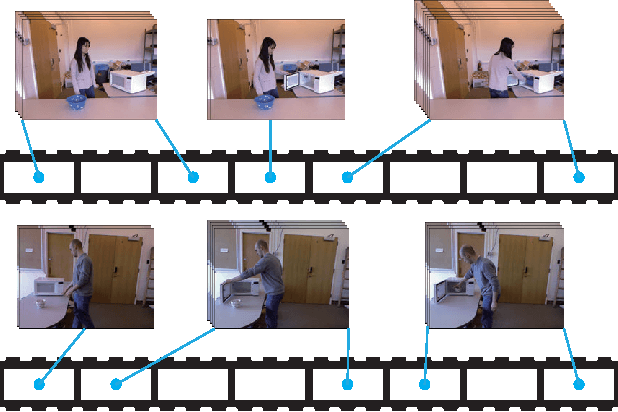
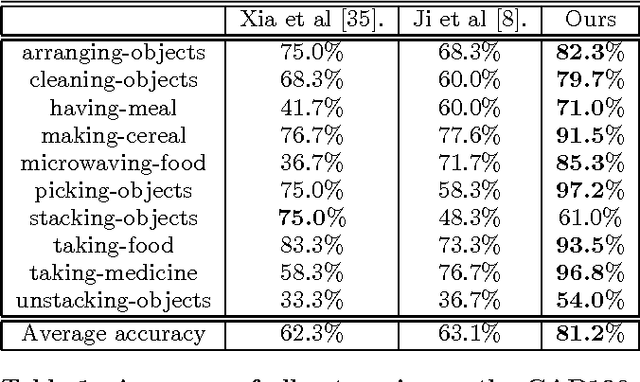
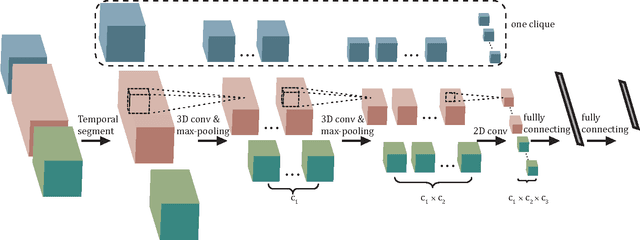
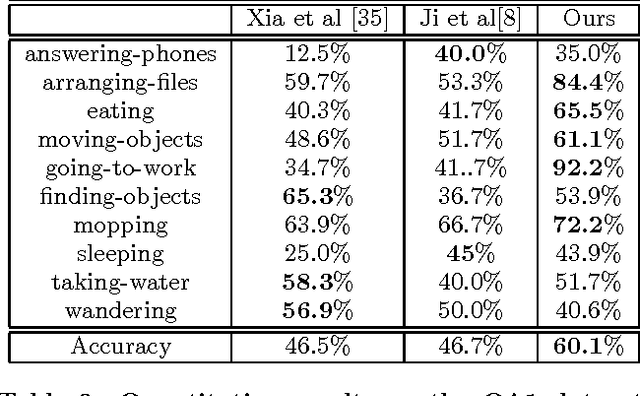
Human activity understanding with 3D/depth sensors has received increasing attention in multimedia processing and interactions. This work targets on developing a novel deep model for automatic activity recognition from RGB-D videos. We represent each human activity as an ensemble of cubic-like video segments, and learn to discover the temporal structures for a category of activities, i.e. how the activities to be decomposed in terms of classification. Our model can be regarded as a structured deep architecture, as it extends the convolutional neural networks (CNNs) by incorporating structure alternatives. Specifically, we build the network consisting of 3D convolutions and max-pooling operators over the video segments, and introduce the latent variables in each convolutional layer manipulating the activation of neurons. Our model thus advances existing approaches in two aspects: (i) it acts directly on the raw inputs (grayscale-depth data) to conduct recognition instead of relying on hand-crafted features, and (ii) the model structure can be dynamically adjusted accounting for the temporal variations of human activities, i.e. the network configuration is allowed to be partially activated during inference. For model training, we propose an EM-type optimization method that iteratively (i) discovers the latent structure by determining the decomposed actions for each training example, and (ii) learns the network parameters by using the back-propagation algorithm. Our approach is validated in challenging scenarios, and outperforms state-of-the-art methods. A large human activity database of RGB-D videos is presented in addition.