 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Latent Feature Modeling for Data Exploration Tasks
Jul 26, 2017



This paper introduces a general Bayesian non- parametric latent feature model suitable to per- form automatic exploratory analysis of heterogeneous datasets, where the attributes describing each object can be either discrete, continuous or mixed variables. The proposed model presents several important properties. First, it accounts for heterogeneous data while can be inferred in linear time with respect to the number of objects and attributes. Second, its Bayesian nonparametric nature allows us to automatically infer the model complexity from the data, i.e., the number of features necessary to capture the latent structure in the data. Third, the latent features in the model are binary-valued variables, easing the interpretability of the obtained latent features in data exploration tasks.
Improving Output Uncertainty Estimation and Generalization in Deep Learning via Neural Network Gaussian Processes
Jul 19, 2017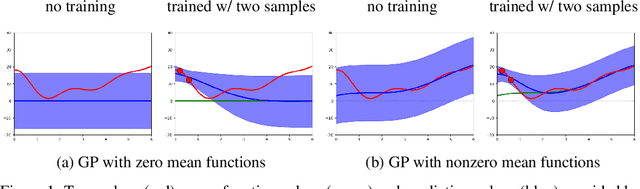
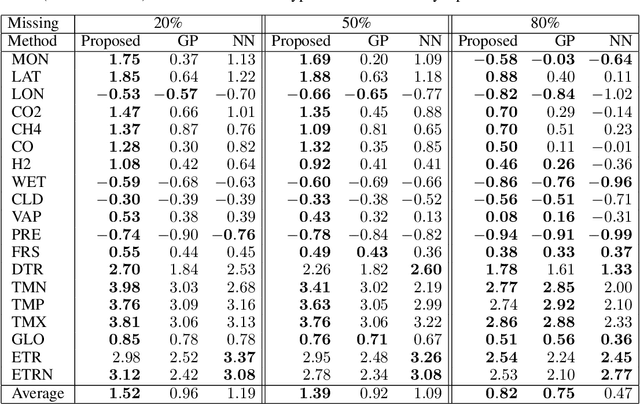
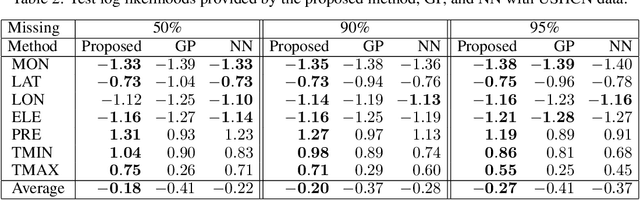
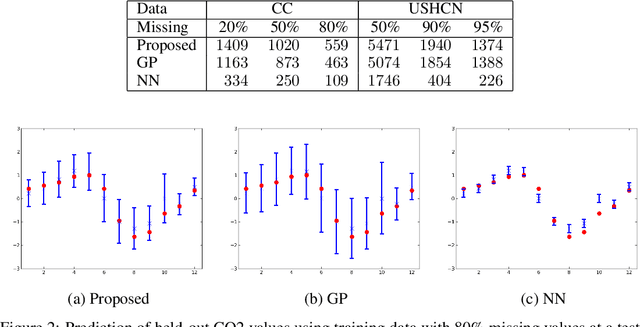
We propose a simple method that combines neural networks and Gaussian processes. The proposed method can estimate the uncertainty of outputs and flexibly adjust target functions where training data exist, which are advantages of Gaussian processes. The proposed method can also achieve high generalization performance for unseen input configurations, which is an advantage of neural networks. With the proposed method, neural networks are used for the mean functions of Gaussian processes. We present a scalable stochastic inference procedure, where sparse Gaussian processes are inferred by stochastic variational inference, and the parameters of neural networks and kernels are estimated by stochastic gradient descent methods, simultaneously. We use two real-world spatio-temporal data sets to demonstrate experimentally that the proposed method achieves better uncertainty estimation and generalization performance than neural networks and Gaussian processes.
One-Shot Learning in Discriminative Neural Networks
Jul 18, 2017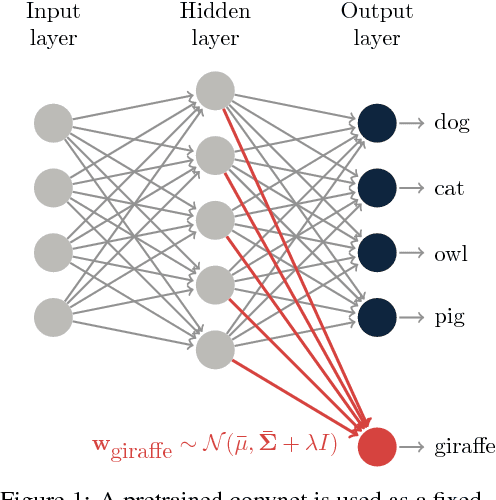
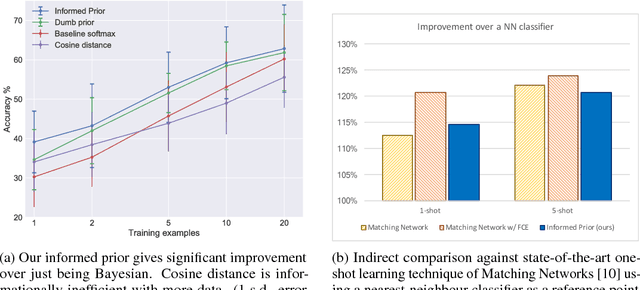
We consider the task of one-shot learning of visual categories. In this paper we explore a Bayesian procedure for updating a pretrained convnet to classify a novel image category for which data is limited. We decompose this convnet into a fixed feature extractor and softmax classifier. We assume that the target weights for the new task come from the same distribution as the pretrained softmax weights, which we model as a multivariate Gaussian. By using this as a prior for the new weights, we demonstrate competitive performance with state-of-the-art methods whilst also being consistent with 'normal' methods for training deep networks on large data.
Adversarial Examples, Uncertainty, and Transfer Testing Robustness in Gaussian Process Hybrid Deep Networks
Jul 08, 2017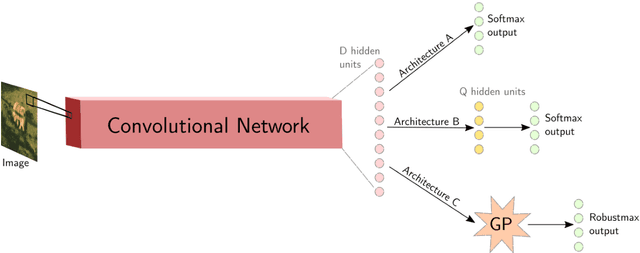
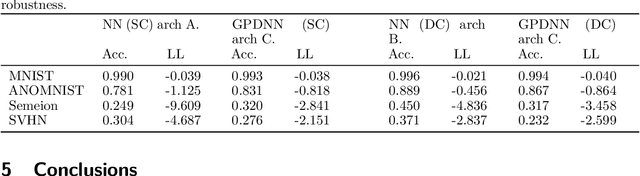
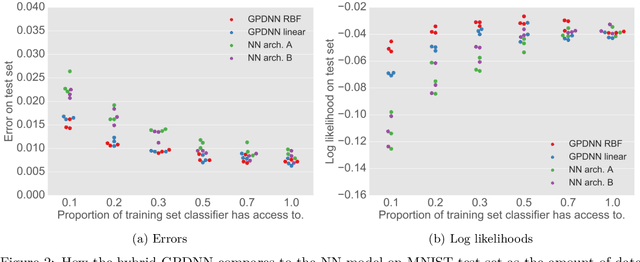
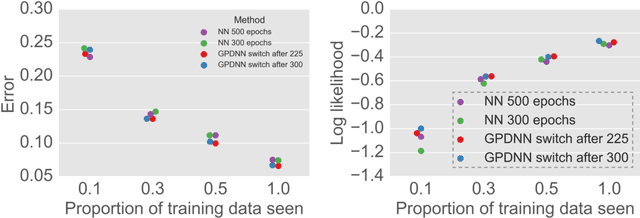
Deep neural networks (DNNs) have excellent representative power and are state of the art classifiers on many tasks. However, they often do not capture their own uncertainties well making them less robust in the real world as they overconfidently extrapolate and do not notice domain shift. Gaussian processes (GPs) with RBF kernels on the other hand have better calibrated uncertainties and do not overconfidently extrapolate far from data in their training set. However, GPs have poor representational power and do not perform as well as DNNs on complex domains. In this paper we show that GP hybrid deep networks, GPDNNs, (GPs on top of DNNs and trained end-to-end) inherit the nice properties of both GPs and DNNs and are much more robust to adversarial examples. When extrapolating to adversarial examples and testing in domain shift settings, GPDNNs frequently output high entropy class probabilities corresponding to essentially "don't know". GPDNNs are therefore promising as deep architectures that know when they don't know.
Bayesian inference on random simple graphs with power law degree distributions
Jun 18, 2017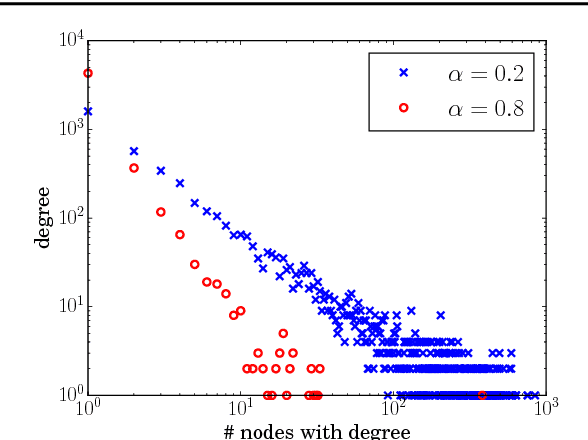

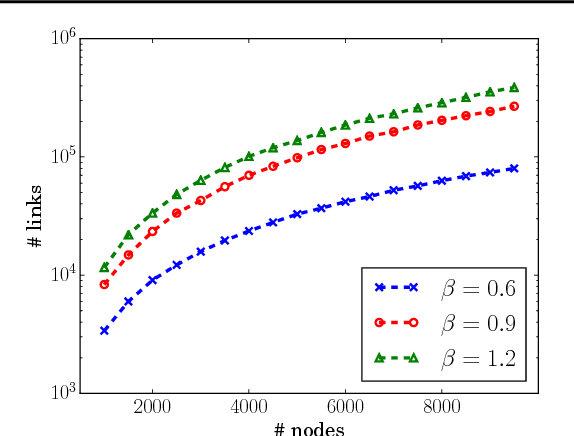
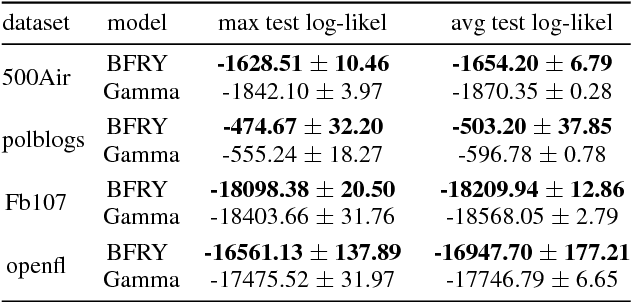
We present a model for random simple graphs with a degree distribution that obeys a power law (i.e., is heavy-tailed). To attain this behavior, the edge probabilities in the graph are constructed from Bertoin-Fujita-Roynette-Yor (BFRY) random variables, which have been recently utilized in Bayesian statistics for the construction of power law models in several applications. Our construction readily extends to capture the structure of latent factors, similarly to stochastic blockmodels, while maintaining its power law degree distribution. The BFRY random variables are well approximated by gamma random variables in a variational Bayesian inference routine, which we apply to several network datasets for which power law degree distributions are a natural assumption. By learning the parameters of the BFRY distribution via probabilistic inference, we are able to automatically select the appropriate power law behavior from the data. In order to further scale our inference procedure, we adopt stochastic gradient ascent routines where the gradients are computed on minibatches (i.e., subsets) of the edges in the graph.
Lost Relatives of the Gumbel Trick
Jun 13, 2017
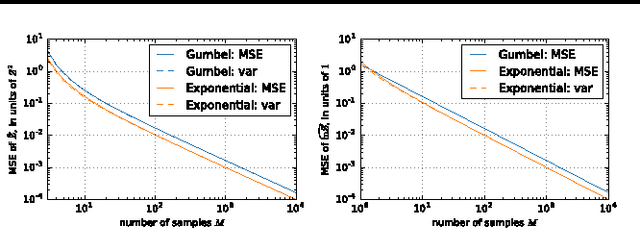
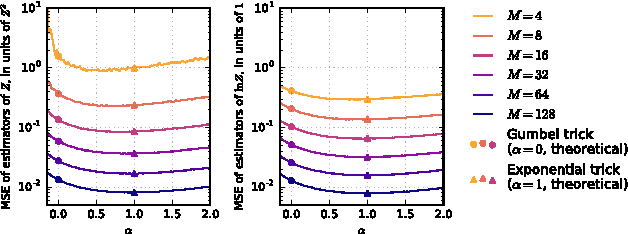
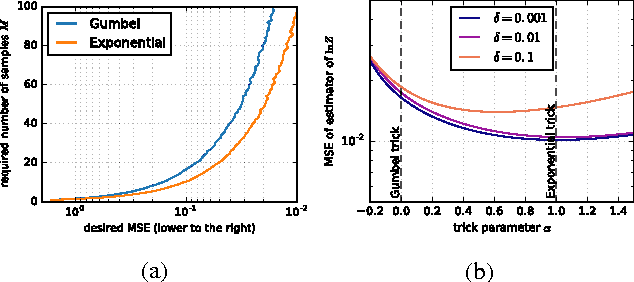
The Gumbel trick is a method to sample from a discrete probability distribution, or to estimate its normalizing partition function. The method relies on repeatedly applying a random perturbation to the distribution in a particular way, each time solving for the most likely configuration. We derive an entire family of related methods, of which the Gumbel trick is one member, and show that the new methods have superior properties in several settings with minimal additional computational cost. In particular, for the Gumbel trick to yield computational benefits for discrete graphical models, Gumbel perturbations on all configurations are typically replaced with so-called low-rank perturbations. We show how a subfamily of our new methods adapts to this setting, proving new upper and lower bounds on the log partition function and deriving a family of sequential samplers for the Gibbs distribution. Finally, we balance the discussion by showing how the simpler analytical form of the Gumbel trick enables additional theoretical results.
Interpolated Policy Gradient: Merging On-Policy and Off-Policy Gradient Estimation for Deep Reinforcement Learning
Jun 01, 2017
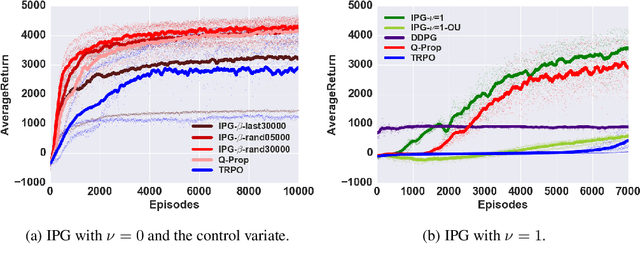
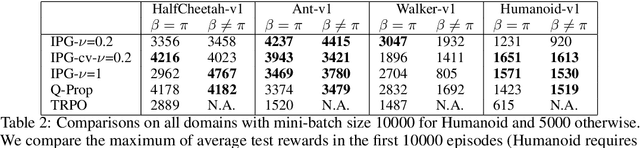
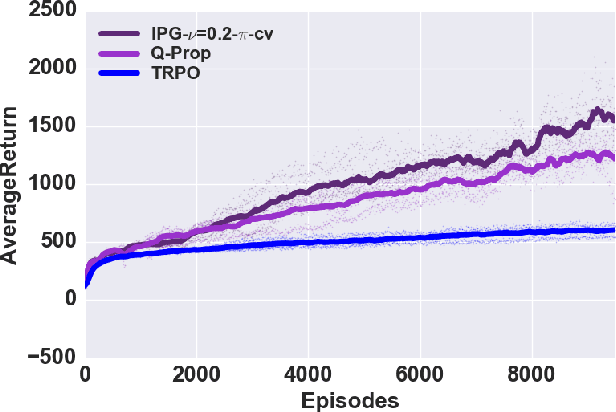
Off-policy model-free deep reinforcement learning methods using previously collected data can improve sample efficiency over on-policy policy gradient techniques. On the other hand, on-policy algorithms are often more stable and easier to use. This paper examines, both theoretically and empirically, approaches to merging on- and off-policy updates for deep reinforcement learning. Theoretical results show that off-policy updates with a value function estimator can be interpolated with on-policy policy gradient updates whilst still satisfying performance bounds. Our analysis uses control variate methods to produce a family of policy gradient algorithms, with several recently proposed algorithms being special cases of this family. We then provide an empirical comparison of these techniques with the remaining algorithmic details fixed, and show how different mixing of off-policy gradient estimates with on-policy samples contribute to improvements in empirical performance. The final algorithm provides a generalization and unification of existing deep policy gradient techniques, has theoretical guarantees on the bias introduced by off-policy updates, and improves on the state-of-the-art model-free deep RL methods on a number of OpenAI Gym continuous control benchmarks.
Deep Bayesian Active Learning with Image Data
Mar 08, 2017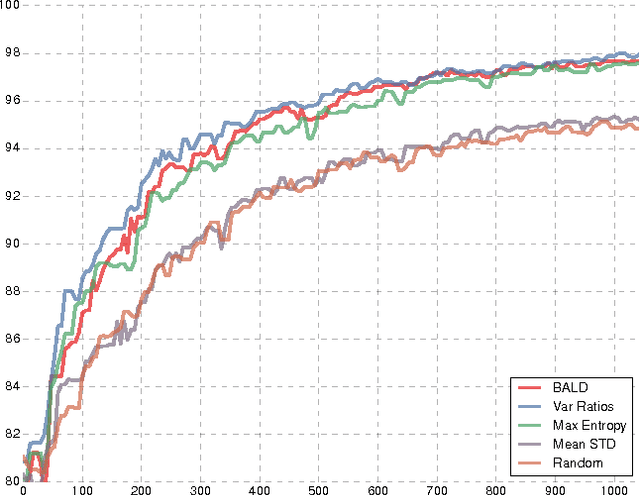


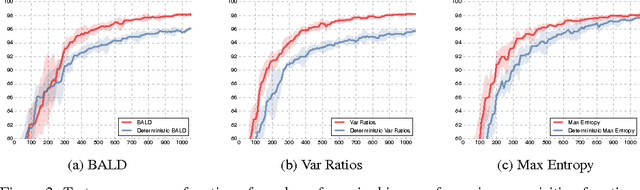
Even though active learning forms an important pillar of machine learning, deep learning tools are not prevalent within it. Deep learning poses several difficulties when used in an active learning setting. First, active learning (AL) methods generally rely on being able to learn and update models from small amounts of data. Recent advances in deep learning, on the other hand, are notorious for their dependence on large amounts of data. Second, many AL acquisition functions rely on model uncertainty, yet deep learning methods rarely represent such model uncertainty. In this paper we combine recent advances in Bayesian deep learning into the active learning framework in a practical way. We develop an active learning framework for high dimensional data, a task which has been extremely challenging so far, with very sparse existing literature. Taking advantage of specialised models such as Bayesian convolutional neural networks, we demonstrate our active learning techniques with image data, obtaining a significant improvement on existing active learning approaches. We demonstrate this on both the MNIST dataset, as well as for skin cancer diagnosis from lesion images (ISIC2016 task).
Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic
Feb 27, 2017
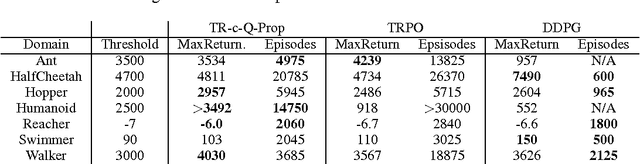
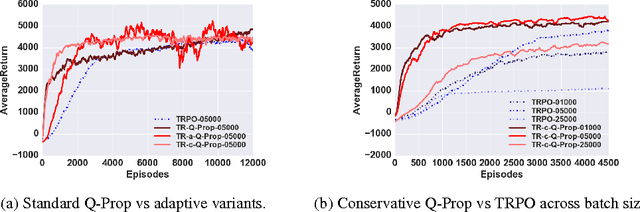

Model-free deep reinforcement learning (RL) methods have been successful in a wide variety of simulated domains. However, a major obstacle facing deep RL in the real world is their high sample complexity. Batch policy gradient methods offer stable learning, but at the cost of high variance, which often requires large batches. TD-style methods, such as off-policy actor-critic and Q-learning, are more sample-efficient but biased, and often require costly hyperparameter sweeps to stabilize. In this work, we aim to develop methods that combine the stability of policy gradients with the efficiency of off-policy RL. We present Q-Prop, a policy gradient method that uses a Taylor expansion of the off-policy critic as a control variate. Q-Prop is both sample efficient and stable, and effectively combines the benefits of on-policy and off-policy methods. We analyze the connection between Q-Prop and existing model-free algorithms, and use control variate theory to derive two variants of Q-Prop with conservative and aggressive adaptation. We show that conservative Q-Prop provides substantial gains in sample efficiency over trust region policy optimization (TRPO) with generalized advantage estimation (GAE), and improves stability over deep deterministic policy gradient (DDPG), the state-of-the-art on-policy and off-policy methods, on OpenAI Gym's MuJoCo continuous control environments.
GPflow: A Gaussian process library using TensorFlow
Oct 27, 2016
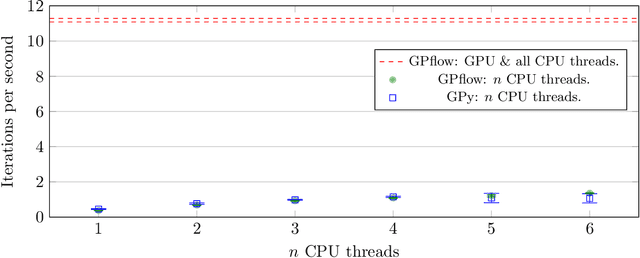

GPflow is a Gaussian process library that uses TensorFlow for its core computations and Python for its front end. The distinguishing features of GPflow are that it uses variational inference as the primary approximation method, provides concise code through the use of automatic differentiation, has been engineered with a particular emphasis on software testing and is able to exploit GPU hardware.