 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Continuous Treatment Policy and Bipartite Embeddings for Matching with Heterogeneous Causal Effects
Apr 21, 2020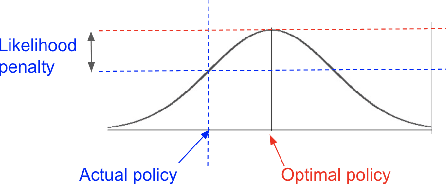
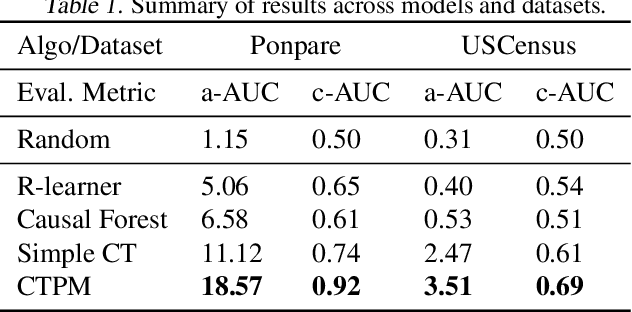
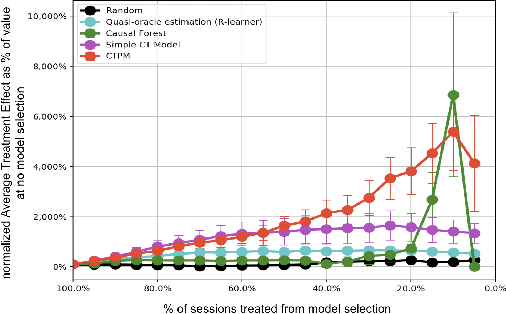
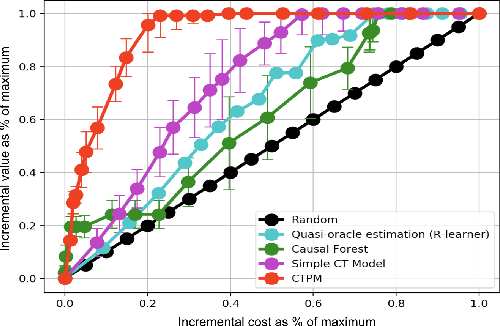
Causal inference methods are widely applied in the fields of medicine, policy, and economics. Central to these applications is the estimation of treatment effects to make decisions. Current methods make binary yes-or-no decisions based on the treatment effect of a single outcome dimension. These methods are unable to capture continuous space treatment policies with a measure of intensity. They also lack the capacity to consider the complexity of treatment such as matching candidate treatments with the subject. We propose to formulate the effectiveness of treatment as a parametrizable model, expanding to a multitude of treatment intensities and complexities through the continuous policy treatment function, and the likelihood of matching. Our proposal to decompose treatment effect functions into effectiveness factors presents a framework to model a rich space of actions using causal inference. We utilize deep learning to optimize the desired holistic metric space instead of predicting single-dimensional treatment counterfactual. This approach employs a population-wide effectiveness measure and significantly improves the overall effectiveness of the model. The performance of our algorithms is. demonstrated with experiments. When using generic continuous space treatments and matching architecture, we observe a 41% improvement upon prior art with cost-effectiveness and 68% improvement upon a similar method in the average treatment effect. The algorithms capture subtle variations in treatment space, structures the efficient optimizations techniques, and opens up the arena for many applications.
Einsum Networks: Fast and Scalable Learning of Tractable Probabilistic Circuits
Apr 13, 2020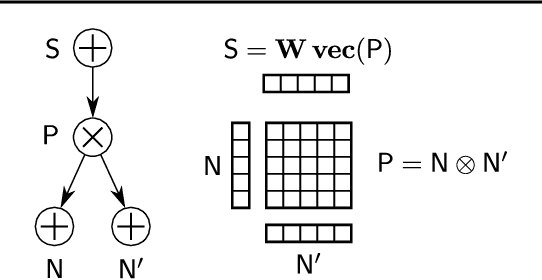

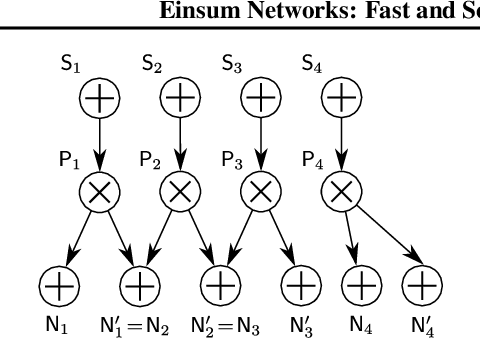
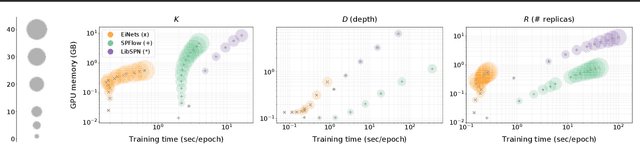
Probabilistic circuits (PCs) are a promising avenue for probabilistic modeling, as they permit a wide range of exact and efficient inference routines. Recent ``deep-learning-style'' implementations of PCs strive for a better scalability, but are still difficult to train on real-world data, due to their sparsely connected computational graphs. In this paper, we propose Einsum Networks (EiNets), a novel implementation design for PCs, improving prior art in several regards. At their core, EiNets combine a large number of arithmetic operations in a single monolithic einsum-operation, leading to speedups and memory savings of up to two orders of magnitude, in comparison to previous implementations. As an algorithmic contribution, we show that the implementation of Expectation-Maximization (EM) can be simplified for PCs, by leveraging automatic differentiation. Furthermore, we demonstrate that EiNets scale well to datasets which were previously out of reach, such as SVHN and CelebA, and that they can be used as faithful generative image models.
DynamicPPL: Stan-like Speed for Dynamic Probabilistic Models
Feb 07, 2020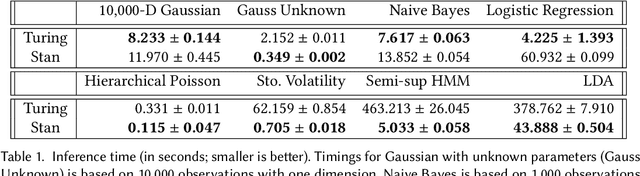
We present the preliminary high-level design and features of DynamicPPL.jl, a modular library providing a lightning-fast infrastructure for probabilistic programming. Besides a computational performance that is often close to or better than Stan, DynamicPPL provides an intuitive DSL that allows the rapid development of complex dynamic probabilistic programs. Being entirely written in Julia, a high-level dynamic programming language for numerical computing, DynamicPPL inherits a rich set of features available through the Julia ecosystem. Since DynamicPPL is a modular, stand-alone library, any probabilistic programming system written in Julia, such as Turing.jl, can use DynamicPPL to specify models and trace their model parameters. The main features of DynamicPPL are: 1) a meta-programming based DSL for specifying dynamic models using an intuitive tilde-based notation; 2) a tracing data-structure for tracking RVs in dynamic probabilistic models; 3) a rich contextual dispatch system allowing tailored behaviour during model execution; and 4) a user-friendly syntax for probabilistic queries. Finally, we show in a variety of experiments that DynamicPPL, in combination with Turing.jl, achieves computational performance that is often close to or better than Stan.
Resource-Efficient Neural Networks for Embedded Systems
Jan 07, 2020
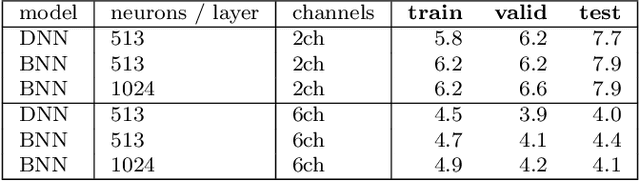
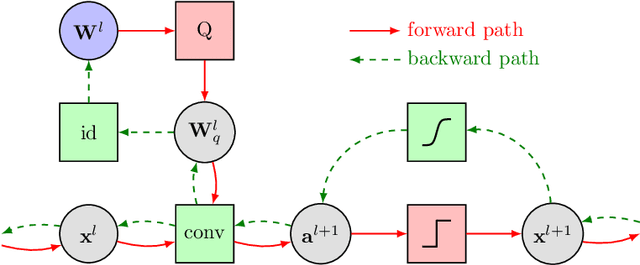
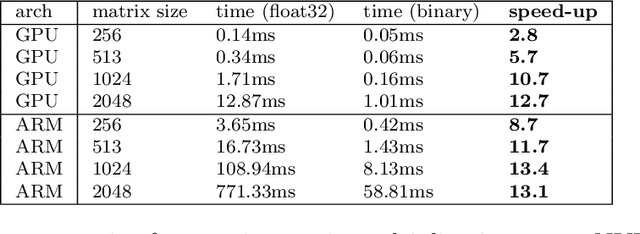
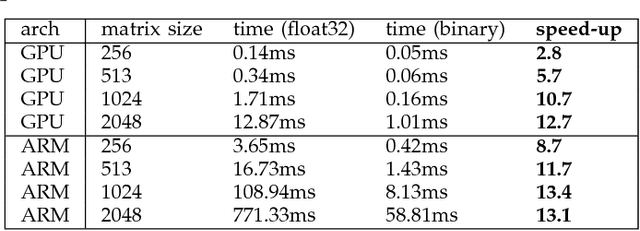
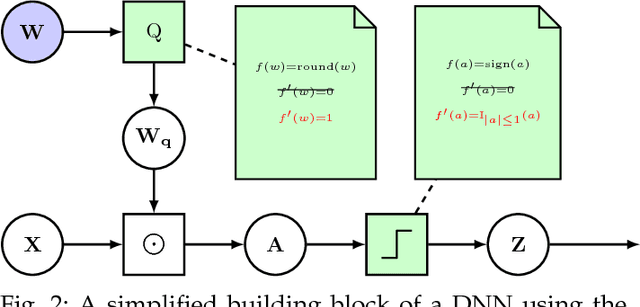
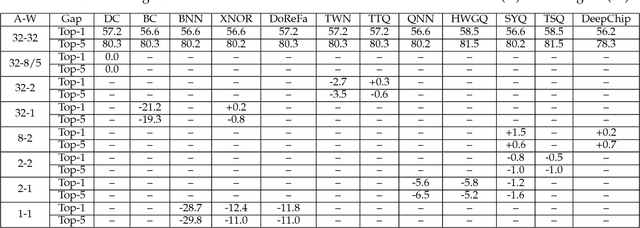
While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation, and the vision of the Internet of Things fuel the interest in resource-efficient approaches. These approaches aim for a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. The development of such approaches is among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology from a scientific environment with virtually unlimited computing resources into every day's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. In particular, we focus on deep neural networks (DNNs), the predominant machine learning models of the past decade. We give a comprehensive overview of the vast literature that can be mainly split into three non-mutually exclusive categories: (i) quantized neural networks, (ii) network pruning, and (iii) structural efficiency. These techniques can be applied during training or as post-processing, and they are widely used to reduce the computational demands in terms of memory footprint, inference speed, and energy efficiency. We substantiate our discussion with experiments on well-known benchmark data sets to showcase the difficulty of finding good trade-offs between resource-efficiency and predictive performance.
Bayesian Learning of Sum-Product Networks
May 26, 2019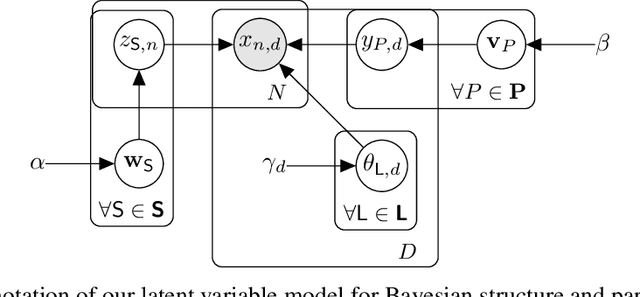
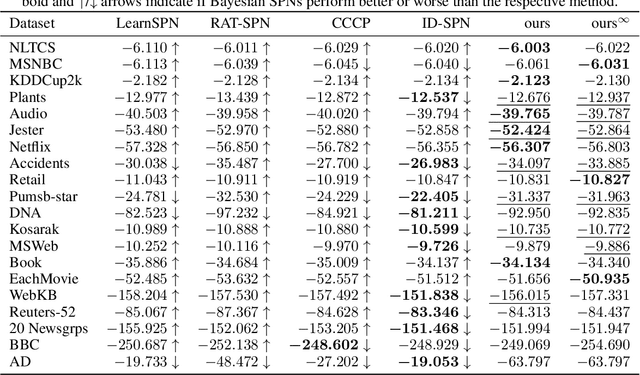
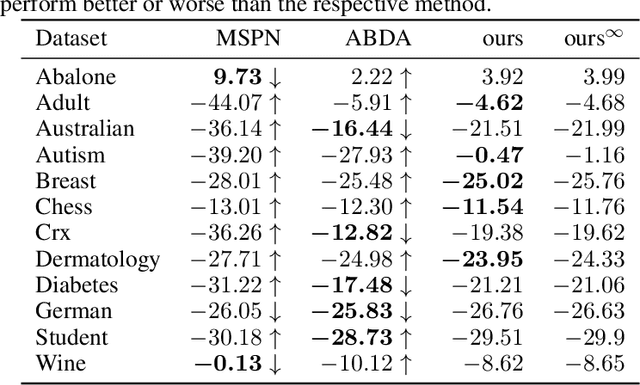
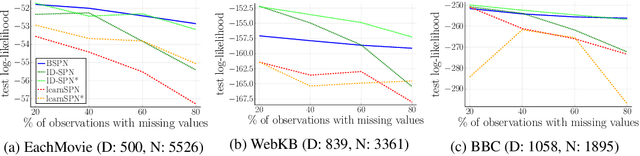
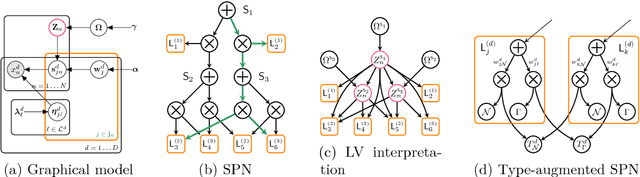
Sum-product networks (SPNs) are flexible density estimators and have received significant attention, due to their attractive inference properties. While parameter learning in SPNs is well developed, structure learning leaves something to be desired: Even though there is a plethora of SPN structure learners, most of them are somewhat ad-hoc, and based on intuition rather than a clear learning principle. In this paper, we introduce a well-principled Bayesian framework for SPN structure learning. First, we decompose the problem into i) laying out a basic computational graph, and ii) learning the so-called scope function over the graph. The first is rather unproblematic and akin to neural network architecture validation. The second characterises the effective structure of the SPN and needs to respect the usual structural constraints in SPN, i.e. completeness and decomposability. While representing and learning the scope function is rather involved in general, in this paper, we propose a natural parametrisation for an important and widely used special case of SPNs. These structural parameters are incorporated into a Bayesian model, such that simultaneous structure and parameter learning is cast into monolithic Bayesian posterior inference. In various experiments, our Bayesian SPNs often improve test likelihoods over greedy SPN learners. Further, since the Bayesian framework protects against overfitting, we are able to evaluate hyper-parameters directly on the Bayesian model score, waiving the need for a separate validation set, which is especially beneficial in low data regimes. Bayesian SPNs can be applied to heterogeneous domains and can easily be extended to nonparametric formulations. Moreover, our Bayesian approach is the first which consistently and robustly learns SPN structures under missing data.
Efficient and Robust Machine Learning for Real-World Systems
Dec 05, 2018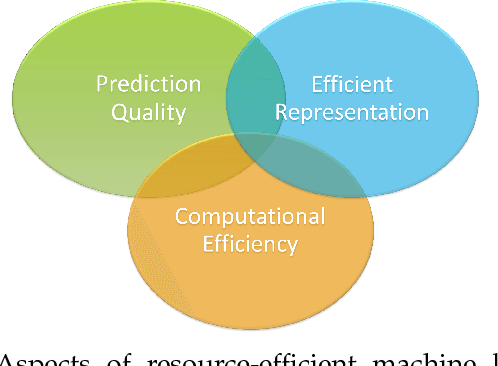
While machine learning is traditionally a resource intensive task, embedded systems, autonomous navigation and the vision of the Internet-of-Things fuel the interest in resource efficient approaches. These approaches require a carefully chosen trade-off between performance and resource consumption in terms of computation and energy. On top of this, it is crucial to treat uncertainty in a consistent manner in all but the simplest applications of machine learning systems. In particular, a desideratum for any real-world system is to be robust in the presence of outliers and corrupted data, as well as being `aware' of its limits, i.e.\ the system should maintain and provide an uncertainty estimate over its own predictions. These complex demands are among the major challenges in current machine learning research and key to ensure a smooth transition of machine learning technology into every day's applications. In this article, we provide an overview of the current state of the art of machine learning techniques facilitating these real-world requirements. First we provide a comprehensive review of resource-efficiency in deep neural networks with focus on techniques for model size reduction, compression and reduced precision. These techniques can be applied during training or as post-processing and are widely used to reduce both computational complexity and memory footprint. As most (practical) neural networks are limited in their ways to treat uncertainty, we contrast them with probabilistic graphical models, which readily serve these desiderata by means of probabilistic inference. In that way, we provide an extensive overview of the current state-of-the-art of robust and efficient machine learning for real-world systems.
Handling Incomplete Heterogeneous Data using VAEs
Oct 30, 2018
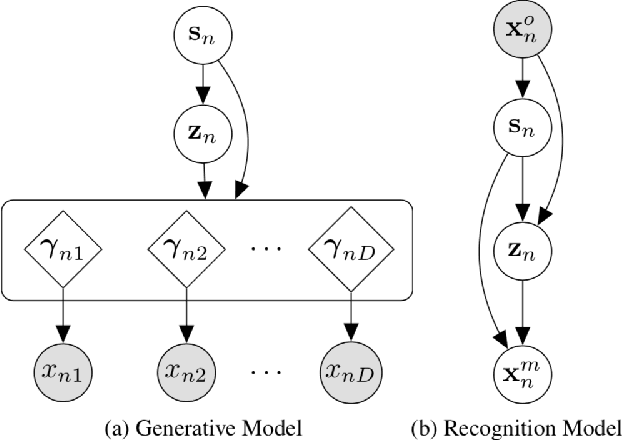

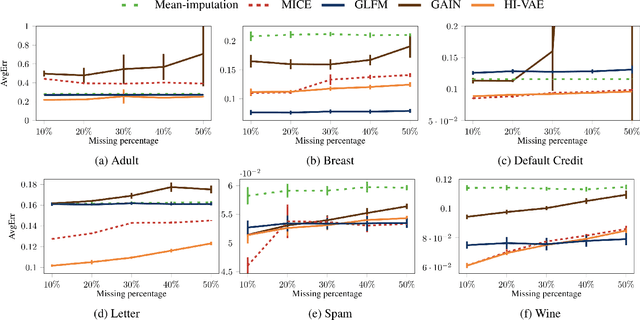
Variational autoencoders (VAEs), as well as other generative models, have been shown to be efficient and accurate to capture the latent structure of vast amounts of complex high-dimensional data. However, existing VAEs can still not directly handle data that are heterogenous (mixed continuous and discrete) or incomplete (with missing data at random), which is indeed common in real-world applications. In this paper, we propose a general framework to design VAEs, suitable for fitting incomplete heterogenous data. The proposed HI-VAE includes likelihood models for real-valued, positive real valued, interval, categorical, ordinal and count data, and allows to estimate (and potentially impute) missing data accurately. Furthermore, HI-VAE presents competitive predictive performance in supervised tasks, outperforming super- vised models when trained on incomplete data
Automatic Bayesian Density Analysis
Oct 03, 2018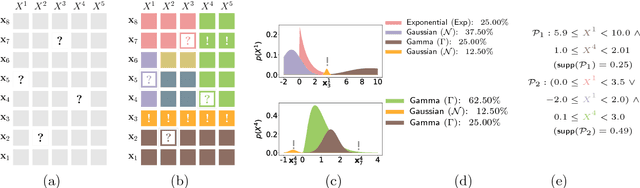
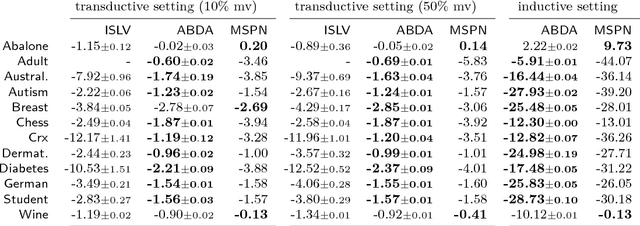

Making sense of a dataset in an automatic and unsupervised fashion is a challenging problem in statistics and AI. Classical approaches for density estimation are usually not flexible enough to deal with the uncertainty inherent to real-world data: they are often restricted to fixed latent interaction models and homogeneous likelihoods; they are sensitive to missing, corrupt and anomalous data; moreover, their expressiveness generally comes at the price of intractable inference. As a result, supervision from statisticians is usually needed to find the right model for the data. However, as domain experts do not necessarily have to be experts in statistics, we propose Automatic Bayesian Density Analysis (ABDA) to make density estimation accessible at large. ABDA automates the selection of adequate likelihood models from arbitrarily rich dictionaries while modeling their interactions via a deep latent structure adaptively learned from data as a sum-product network. ABDA casts uncertainty estimation at these local and global levels into a joint Bayesian inference problem, providing robust and yet tractable inference. Extensive empirical evidence shows that ABDA is a suitable tool for automatic exploratory analysis of heterogeneous tabular data, allowing for missing value estimation, statistical data type and likelihood discovery, anomaly detection and dependency structure mining, on top of providing accurate density estimation.
Probabilistic Meta-Representations Of Neural Networks
Oct 01, 2018



Existing Bayesian treatments of neural networks are typically characterized by weak prior and approximate posterior distributions according to which all the weights are drawn independently. Here, we consider a richer prior distribution in which units in the network are represented by latent variables, and the weights between units are drawn conditionally on the values of the collection of those variables. This allows rich correlations between related weights, and can be seen as realizing a function prior with a Bayesian complexity regularizer ensuring simple solutions. We illustrate the resulting meta-representations and representations, elucidating the power of this prior.
Gaussian Process Behaviour in Wide Deep Neural Networks
Aug 16, 2018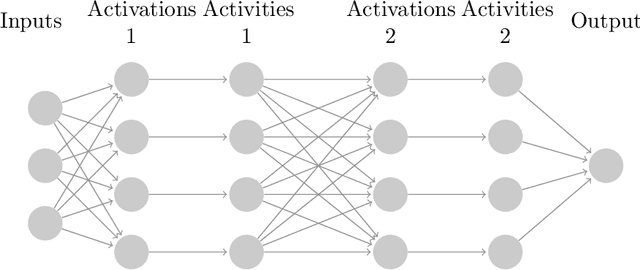
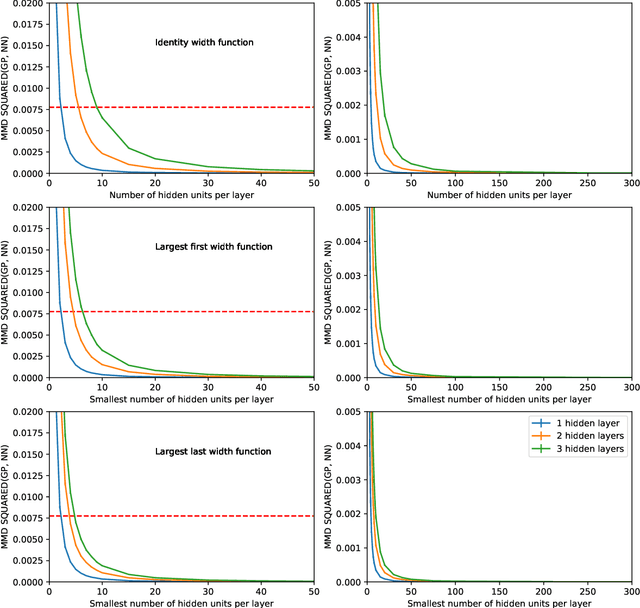
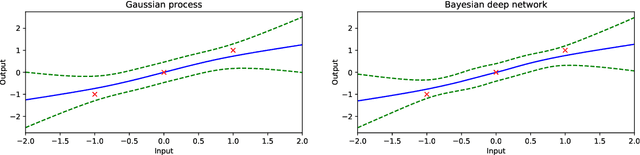
Whilst deep neural networks have shown great empirical success, there is still much work to be done to understand their theoretical properties. In this paper, we study the relationship between random, wide, fully connected, feedforward networks with more than one hidden layer and Gaussian processes with a recursive kernel definition. We show that, under broad conditions, as we make the architecture increasingly wide, the implied random function converges in distribution to a Gaussian process, formalising and extending existing results by Neal (1996) to deep networks. To evaluate convergence rates empirically, we use maximum mean discrepancy. We then compare finite Bayesian deep networks from the literature to Gaussian processes in terms of the key predictive quantities of interest, finding that in some cases the agreement can be very close. We discuss the desirability of Gaussian process behaviour and review non-Gaussian alternative models from the literature.