 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntithetic and Monte Carlo kernel estimators for partial rankings
Paper and Code
Jul 25, 2018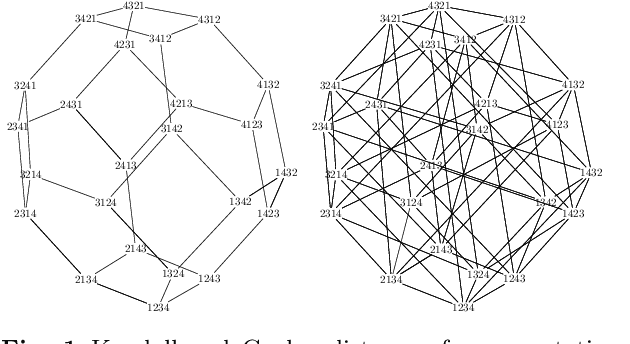
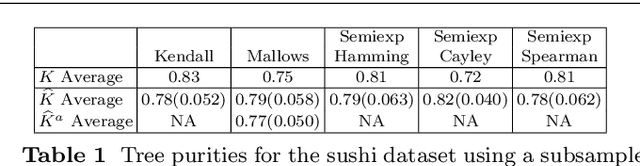
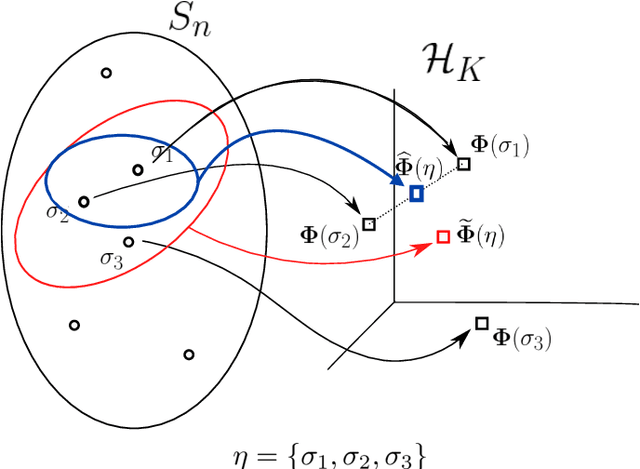
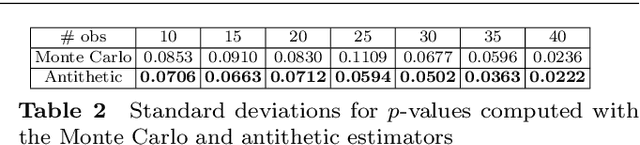
In the modern age, rankings data is ubiquitous and it is useful for a variety of applications such as recommender systems, multi-object tracking and preference learning. However, most rankings data encountered in the real world is incomplete, which prevents the direct application of existing modelling tools for complete rankings. Our contribution is a novel way to extend kernel methods for complete rankings to partial rankings, via consistent Monte Carlo estimators for Gram matrices: matrices of kernel values between pairs of observations. We also present a novel variance reduction scheme based on an antithetic variate construction between permutations to obtain an improved estimator for the Mallows kernel. The corresponding antithetic kernel estimator has lower variance and we demonstrate empirically that it has a better performance in a variety of Machine Learning tasks. Both kernel estimators are based on extending kernel mean embeddings to the embedding of a set of full rankings consistent with an observed partial ranking. They form a computationally tractable alternative to previous approaches for partial rankings data. An overview of the existing kernels and metrics for permutations is also provided.