 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot learning of neural networks from scratch by pseudo example optimization
Paper and Code
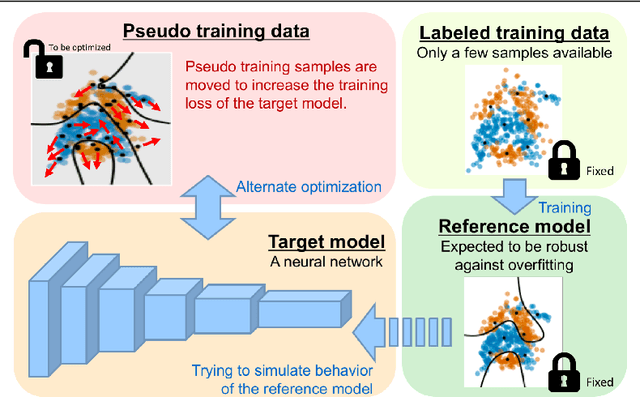
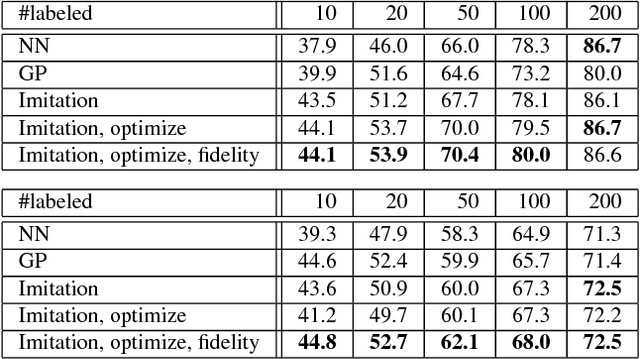
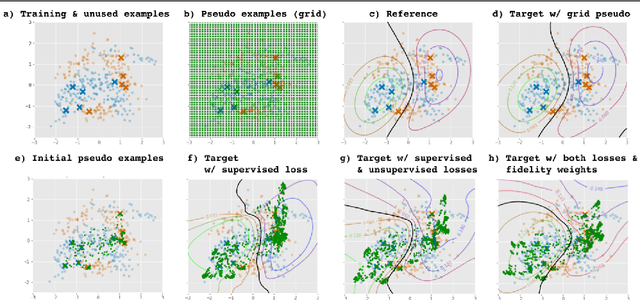
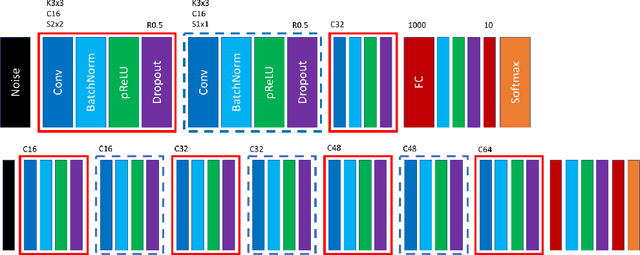
In this paper, we propose a simple but effective method for training neural networks with a limited amount of training data. Our approach inherits the idea of knowledge distillation that transfers knowledge from a deep or wide reference model to a shallow or narrow target model. The proposed method employs this idea to mimic predictions of reference estimators that are more robust against overfitting than the network we want to train. Different from almost all the previous work for knowledge distillation that requires a large amount of labeled training data, the proposed method requires only a small amount of training data. Instead, we introduce pseudo training examples that are optimized as a part of model parameters. Experimental results for several benchmark datasets demonstrate that the proposed method outperformed all the other baselines, such as naive training of the target model and standard knowledge distillation.