 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkinned Motion Retargeting with Dense Geometric Interaction Perception
Oct 28, 2024Capturing and maintaining geometric interactions among different body parts is crucial for successful motion retargeting in skinned characters. Existing approaches often overlook body geometries or add a geometry correction stage after skeletal motion retargeting. This results in conflicts between skeleton interaction and geometry correction, leading to issues such as jittery, interpenetration, and contact mismatches. To address these challenges, we introduce a new retargeting framework, MeshRet, which directly models the dense geometric interactions in motion retargeting. Initially, we establish dense mesh correspondences between characters using semantically consistent sensors (SCS), effective across diverse mesh topologies. Subsequently, we develop a novel spatio-temporal representation called the dense mesh interaction (DMI) field. This field, a collection of interacting SCS feature vectors, skillfully captures both contact and non-contact interactions between body geometries. By aligning the DMI field during retargeting, MeshRet not only preserves motion semantics but also prevents self-interpenetration and ensures contact preservation. Extensive experiments on the public Mixamo dataset and our newly-collected ScanRet dataset demonstrate that MeshRet achieves state-of-the-art performance. Code available at https://github.com/abcyzj/MeshRet.
Semantics2Hands: Transferring Hand Motion Semantics between Avatars
Aug 11, 2023Human hands, the primary means of non-verbal communication, convey intricate semantics in various scenarios. Due to the high sensitivity of individuals to hand motions, even minor errors in hand motions can significantly impact the user experience. Real applications often involve multiple avatars with varying hand shapes, highlighting the importance of maintaining the intricate semantics of hand motions across the avatars. Therefore, this paper aims to transfer the hand motion semantics between diverse avatars based on their respective hand models. To address this problem, we introduce a novel anatomy-based semantic matrix (ASM) that encodes the semantics of hand motions. The ASM quantifies the positions of the palm and other joints relative to the local frame of the corresponding joint, enabling precise retargeting of hand motions. Subsequently, we obtain a mapping function from the source ASM to the target hand joint rotations by employing an anatomy-based semantics reconstruction network (ASRN). We train the ASRN using a semi-supervised learning strategy on the Mixamo and InterHand2.6M datasets. We evaluate our method in intra-domain and cross-domain hand motion retargeting tasks. The qualitative and quantitative results demonstrate the significant superiority of our ASRN over the state-of-the-arts.
ChoreoNet: Towards Music to Dance Synthesis with Choreographic Action Unit
Sep 16, 2020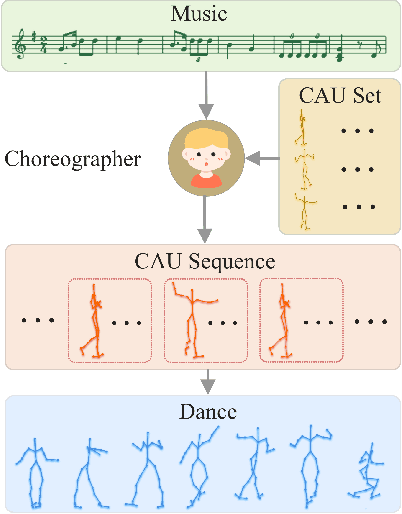

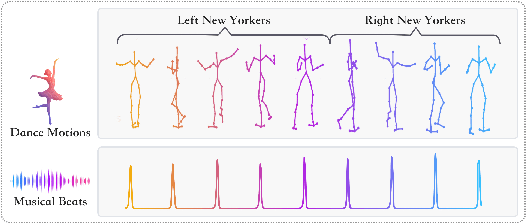
Dance and music are two highly correlated artistic forms. Synthesizing dance motions has attracted much attention recently. Most previous works conduct music-to-dance synthesis via directly music to human skeleton keypoints mapping. Meanwhile, human choreographers design dance motions from music in a two-stage manner: they firstly devise multiple choreographic dance units (CAUs), each with a series of dance motions, and then arrange the CAU sequence according to the rhythm, melody and emotion of the music. Inspired by these, we systematically study such two-stage choreography approach and construct a dataset to incorporate such choreography knowledge. Based on the constructed dataset, we design a two-stage music-to-dance synthesis framework ChoreoNet to imitate human choreography procedure. Our framework firstly devises a CAU prediction model to learn the mapping relationship between music and CAU sequences. Afterwards, we devise a spatial-temporal inpainting model to convert the CAU sequence into continuous dance motions. Experimental results demonstrate that the proposed ChoreoNet outperforms baseline methods (0.622 in terms of CAU BLEU score and 1.59 in terms of user study score).