 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentVLN: Towards Agentic Vision-and-Language Navigation
Mar 18, 2026Vision-and-Language Navigation (VLN) requires an embodied agent to ground complex natural-language instructions into long-horizon navigation in unseen environments. While Vision-Language Models (VLMs) offer strong 2D semantic understanding, current VLN systems remain constrained by limited spatial perception, 2D-3D representation mismatch, and monocular scale ambiguity. In this paper, we propose AgentVLN, a novel and efficient embodied navigation framework that can be deployed on edge computing platforms. We formulate VLN as a Partially Observable Semi-Markov Decision Process (POSMDP) and introduce a VLM-as-Brain paradigm that decouples high-level semantic reasoning from perception and planning via a plug-and-play skill library. To resolve multi-level representation inconsistency, we design a cross-space representation mapping that projects perception-layer 3D topological waypoints into the image plane, yielding pixel-aligned visual prompts for the VLM. Building on this bridge, we integrate a context-aware self-correction and active exploration strategy to recover from occlusions and suppress error accumulation over long trajectories. To further address the spatial ambiguity of instructions in unstructured environments, we propose a Query-Driven Perceptual Chain-of-Thought (QD-PCoT) scheme, enabling the agent with the metacognitive ability to actively seek geometric depth information. Finally, we construct AgentVLN-Instruct, a large-scale instruction-tuning dataset with dynamic stage routing conditioned on target visibility. Extensive experiments show that AgentVLN consistently outperforms prior state-of-the-art methods (SOTA) on long-horizon VLN benchmarks, offering a practical paradigm for lightweight deployment of next-generation embodied navigation models. Code: https://github.com/Allenxinn/AgentVLN.
DecoVLN: Decoupling Observation, Reasoning, and Correction for Vision-and-Language Navigation
Mar 13, 2026Vision-and-Language Navigation (VLN) requires agents to follow long-horizon instructions and navigate complex 3D environments. However, existing approaches face two major challenges: constructing an effective long-term memory bank and overcoming the compounding errors problem. To address these issues, we propose DecoVLN, an effective framework designed for robust streaming perception and closed-loop control in long-horizon navigation. First, we formulate long-term memory construction as an optimization problem and introduce adaptive refinement mechanism that selects frames from a historical candidate pool by iteratively optimizing a unified scoring function. This function jointly balances three key criteria: semantic relevance to the instruction, visual diversity from the selected memory, and temporal coverage of the historical trajectory. Second, to alleviate compounding errors, we introduce a state-action pair-level corrective finetuning strategy. By leveraging geodesic distance between states to precisely quantify deviation from the expert trajectory, the agent collects high-quality state-action pairs in the trusted region while filtering out the polluted data with low relevance. This improves both the efficiency and stability of error correction. Extensive experiments demonstrate the effectiveness of DecoVLN, and we have deployed it in real-world environments.
SHREC'22 Track: Sketch-Based 3D Shape Retrieval in the Wild
Jul 11, 2022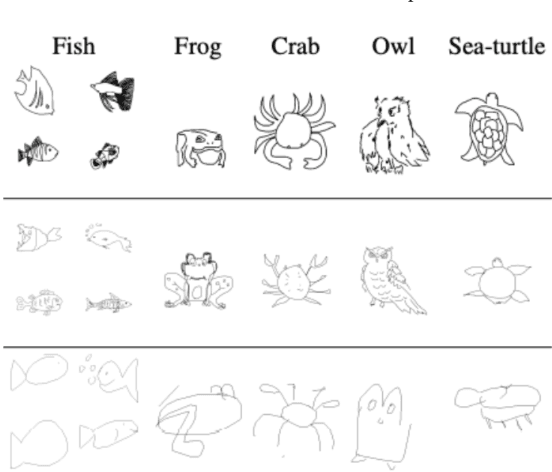
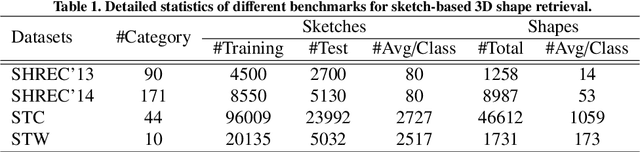
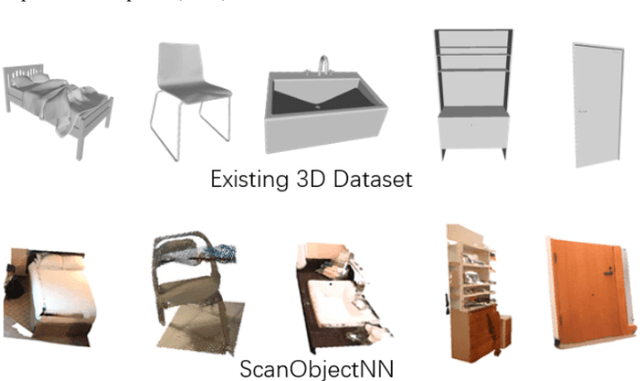
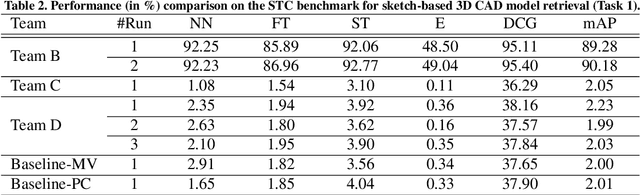
Sketch-based 3D shape retrieval (SBSR) is an important yet challenging task, which has drawn more and more attention in recent years. Existing approaches address the problem in a restricted setting, without appropriately simulating real application scenarios. To mimic the realistic setting, in this track, we adopt large-scale sketches drawn by amateurs of different levels of drawing skills, as well as a variety of 3D shapes including not only CAD models but also models scanned from real objects. We define two SBSR tasks and construct two benchmarks consisting of more than 46,000 CAD models, 1,700 realistic models, and 145,000 sketches in total. Four teams participated in this track and submitted 15 runs for the two tasks, evaluated by 7 commonly-adopted metrics. We hope that, the benchmarks, the comparative results, and the open-sourced evaluation code will foster future research in this direction among the 3D object retrieval community.