 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment-Conditioned Diffusion Meta-Learning for Data-Efficient WiFi Localization
May 11, 2026Fingerprinting-based localization often suffers from poor cross-environment generalization, especially when only a few labeled samples are available in the target environment. Existing methods mitigate distribution shifts through domain adaptation or improved signal representations, but they usually ignore environmental geometry or use it in a deterministic manner, limiting their ability to capture diverse multipath variations in complex propagation conditions. To address this issue, we propose EnvCoLoc, an environment-conditioned diffusion meta-learning framework for few-shot fingerprinting localization. EnvCoLoc extracts structured descriptors from 3D point clouds and uses them to condition a latent diffusion generator, which produces environment-specific parameter offsets to modulate a shared meta-learned initialization. This design injects geometry-aware priors into the adaptation process and provides more informative initializations for new environments. To learn the stochastic mapping from coarse environmental descriptors to high-dimensional parameter corrections under limited data, the diffusion generator and localization network are jointly optimized within a two-loop meta-learning framework. The generated offsets capture systematic environment-dependent variations, while gradient-based inner-loop adaptation further refines the model to reduce residual task-specific mismatch. We also provide an excess-loss analysis for finite-step adaptation, theoretically supporting the benefit of geometry-aware initialization. Real-world experiments show that EnvCoLoc consistently improves localization accuracy over baseline methods, achieving up to a 20.0% reduction in mean localization error in NLOS scenarios with only 10 support samples.
MagicVO: End-to-End Monocular Visual Odometry through Deep Bi-directional Recurrent Convolutional Neural Network
Nov 28, 2018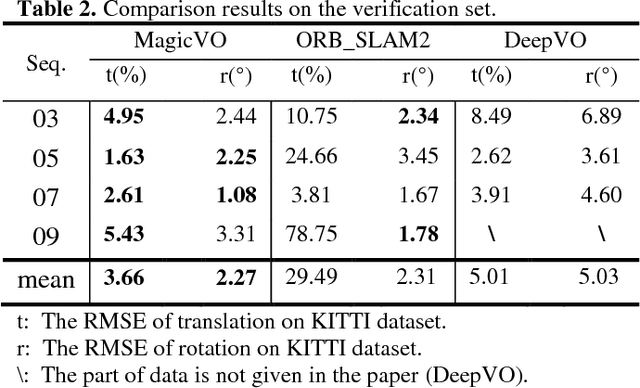
This paper proposes a new framework to solve the problem of monocular visual odometry, called MagicVO . Based on Convolutional Neural Network (CNN) and Bi-directional LSTM (Bi-LSTM), MagicVO outputs a 6-DoF absolute-scale pose at each position of the camera with a sequence of continuous monocular images as input. It not only utilizes the outstanding performance of CNN in image feature processing to extract the rich features of image frames fully but also learns the geometric relationship from image sequences pre and post through Bi-LSTM to get a more accurate prediction. A pipeline of the MagicVO is shown in Fig. 1. The MagicVO system is end-to-end, and the results of experiments on the KITTI dataset and the ETH-asl cla dataset show that MagicVO has a better performance than traditional visual odometry (VO) systems in the accuracy of pose and the generalization ability.