 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoryDocDataSet: A Benchmark for Joint Conversational Memory and Long Document Reasoning
Jun 03, 2026AI systems increasingly need to combine two demanding capabilities: navigating multi-session conversation history and performing deep reading comprehension within long documents. Yet no existing benchmark evaluates both simultaneously. We introduce MemoryDocDataSet, a synthetic benchmark of 50 micro-worlds and 1,000 QA pairs in which each instance comprises 3-5 personas, a temporal event graph spanning months of activity, 3-5 real long documents (20,000-50,000 tokens each sourced from the Caselaw Access Project), multi-session conversations grounded on those documents, and 20 question-answer pairs across five reasoning categories. The defining feature is the Hybrid source tag: questions requiring a system to first navigate conversation history to identify which document is relevant, then extract the answer from within that document. Hybrid questions account for 75.1% of the dataset. Dataset quality is characterised through a prompt-sensitivity self-consistency analysis using LLM-as-judge, yielding a median Cohen's $κ= 0.634$ across all 50 micro-worlds. We evaluate six baseline configurations spanning truncated context, long-context LLMs, retrieval-augmented generation (RAG), and memory systems. The best baseline (RAG-Both) achieves 0.358 overall F1 and 0.342 on Hybrid. Document-only retrieval (RAG-Doc) collapses to 0.267 on Hybrid despite achieving 0.453 on Doc-only questions, demonstrating a clear joint-retrieval gap that motivates architectures unifying conversational memory with long-document navigation. We release the dataset, generation pipeline, and all baseline implementations.
When Does Persona Prompting Actually Help? A Retrieval and Metric Analysis of Expert Role Injection in LLMs
May 28, 2026Persona prompting is widely used to steer large language models, yet its practical value remains unclear. Prior work often evaluates persona prompting using aggregate scores, making it difficult to determine whether expert-role prompting consistently improves response quality or instead changes responses along different quality dimensions. We study this question through a controlled comparison of four prompting conditions across 1,140 open-ended questions spanning 38 expert roles and six domains: no role prompt, a generic domain-expert prompt, embedding-based role retrieval, and a hybrid retrieval method combining embedding search with LLM-based role selection. Aggregate results show only small overall differences between conditions. However, metric-level analysis reveals a consistent tradeoff that aggregate averages obscure: role prompting systematically increases expertise depth while reducing clarity. These effects are highly conditional rather than universal. Role prompting performs best on advisory questions and in domains such as medicine and psychology, where structured expert framing and risk communication are intrinsically valuable. In contrast, baseline prompting performs better on conceptual and explanatory questions in finance, legal, science, and technology domains, where concise plain-language explanation is more important. We further show that hybrid retrieval significantly improves over embedding-only role selection, although better role retrieval does not eliminate the broader expertise-depth versus clarity tradeoff. Overall, our findings suggest that persona prompting primarily reshapes response characteristics rather than broadly improving capability, and that multi-metric evaluation is necessary for understanding its effects.
What Training Data Teaches RL Memory Agents: An Empirical Study of Curriculum Effects in Memory-Augmented QA
May 21, 2026Reinforcement learning (RL) has emerged as a viable recipe for training LLM agents to reason over external memory banks in multi-session dialogue. Existing work trains exclusively on a single benchmark, leaving open how the composition of training data shapes the skills a memory agent acquires. We present a controlled empirical study that holds architecture, RL algorithm, and all hyperparameters fixed and varies only the training curriculum across three conditions: in-domain (LoCoMo), mixed-benchmark (LoCoMo + LongMemEval), and out-of-domain (LongMemEval only). Across two benchmarks and ten question types, curriculum composition acts as a fine-grained lever on specialization rather than a uniform scaling factor on performance. The mixed curriculum yields the strongest overall F1 on both evaluation sets. Training on a narrow out-of-domain set transfers a targeted skill - temporal reasoning - despite weak aggregate performance. Per-type differences substantially exceed aggregate differences, indicating that single-number benchmark comparisons systematically underreport curriculum effects. We further report two practical lessons from adapting GRPO to a single-GPU regime: cross-benchmark mixing requires filtering format-specific noise from memory banks to preserve training signal, and binary exact-match reward produces no learning signal at the small group sizes (G = 4) required on one GPU, motivating continuous reward functions in this regime.
Generative Bayesian Spectrum Cartography: Unified Reconstruction and Active Sensing via Diffusion Models
Dec 23, 2025High-fidelity spectrum cartography is pivotal for spectrum management and wireless situational awareness, yet it remains a challenging ill-posed inverse problem due to the sparsity and irregularity of observations. Furthermore, existing approaches often decouple reconstruction from sensing, lacking a principled mechanism for informative sampling. To address these limitations, this paper proposes a unified diffusion-based Bayesian framework that jointly addresses spectrum reconstruction and active sensing. We formulate the reconstruction task as a conditional generation process driven by a learned diffusion prior. Specifically, we derive tractable, closed-form posterior transition kernels for the reverse diffusion process, which enforce consistency with both linear Gaussian and non-linear quantized measurements. Leveraging the intrinsic probabilistic nature of diffusion models, we further develop an uncertainty-aware active sampling strategy. This strategy quantifies reconstruction uncertainty to adaptively guide sensing agents toward the most informative locations, thereby maximizing spectral efficiency. Extensive experiments demonstrate that the proposed framework significantly outperforms state-of-the-art interpolation, sparsity-based, and deep learning baselines in terms of reconstruction accuracy, sampling efficiency, and robustness to low-bit quantization.
A deep reinforcement learning approach for real-time demand-responsive railway rescheduling to mitigate station overcrowding using mobile data
Aug 23, 2023Real-time railway rescheduling is a timely and flexible technique to automatically alter the operation schedule in response to time-varying conditions. Current research lacks data-driven approaches that capture real-time passenger mobility during railway disruptions, relying mostly on OD-based data and model-based methods for estimating demands of trains. Meanwhile, the schedule-updating principles for a long-term disruption overlook the uneven distribution of demand over time. To fill this gap, this paper proposes a demand-responsive approach by inferring real-world passenger mobility from mobile data (MD) to facilitate real-time rescheduling. Unlike network-level approaches, this paper focuses on a heavy-demand station upstream of the disrupted area. The objective is to reschedule all trains on multiple routes passing through this target station, which have been affected by a severe emergency event such as a natural disaster. Particular attention should be given to avoiding the accumulation of overcrowded passengers at this station, to prevent additional accidents arising from overcrowding. This research addresses the challenges associated with this scenario, including the dynamics of arriving and leaving of passengers, station overcrowding, rolling stock shortage, open-ended disruption duration, integrated rescheduling on multiple routes, and delays due to detours. A deep reinforcement learning (DRL) framework is proposed to determine the optimal rescheduled timetable, route stops, and rolling stock allocation, while considering real-time demand satisfaction, station overcrowding, train capacity utilization, and headway safety.
Probability Paths and the Structure of Predictions over Time
Jun 11, 2021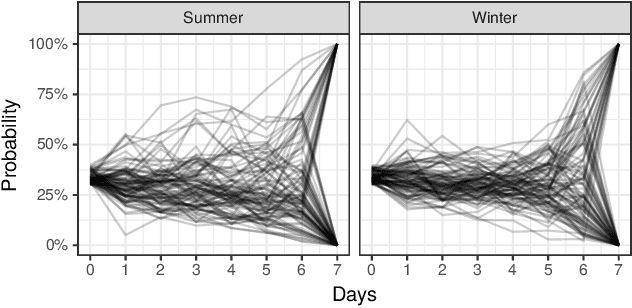
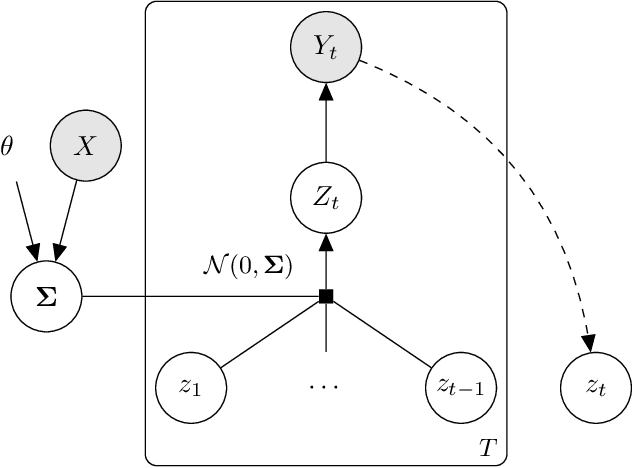
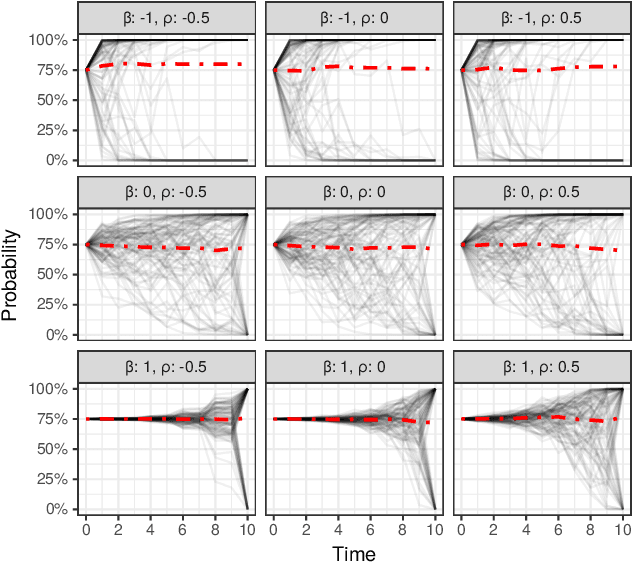
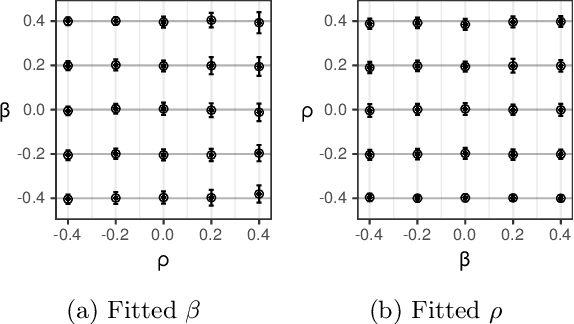
In settings ranging from weather forecasts to political prognostications to financial projections, probability estimates of future binary outcomes often evolve over time. For example, the estimated likelihood of rain on a specific day changes by the hour as new information becomes available. Given a collection of such probability paths, we introduce a Bayesian framework -- which we call the Gaussian latent information martingale, or GLIM -- for modeling the structure of dynamic predictions over time. Suppose, for example, that the likelihood of rain in a week is 50%, and consider two hypothetical scenarios. In the first, one expects the forecast is equally likely to become either 25% or 75% tomorrow; in the second, one expects the forecast to stay constant for the next several days. A time-sensitive decision-maker might select a course of action immediately in the latter scenario, but may postpone their decision in the former, knowing that new information is imminent. We model these trajectories by assuming predictions update according to a latent process of information flow, which is inferred from historical data. In contrast to general methods for time series analysis, this approach preserves the martingale structure of probability paths and better quantifies future uncertainties around probability paths. We show that GLIM outperforms three popular baseline methods, producing better estimated posterior probability path distributions measured by three different metrics. By elucidating the dynamic structure of predictions over time, we hope to help individuals make more informed choices.