 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Fitness With Search Spaces By Fitness Supremums: A Theoretical Study on LGP
May 28, 2025Genetic programming has undergone rapid development in recent years. However, theoretical studies of genetic programming are far behind. One of the major obstacles to theoretical studies is the challenge of developing a model to describe the relationship between fitness values and program genotypes. In this paper, we take linear genetic programming (LGP) as an example to study the fitness-to-genotype relationship. We find that the fitness expectation increases with fitness supremum over instruction editing distance, considering 1) the fitness supremum linearly increases with the instruction editing distance in LGP, 2) the fitness infimum is fixed, and 3) the fitness probabilities over different instruction editing distances are similar. We then extend these findings to explain the bloat effect and the minimum hitting time of LGP based on instruction editing distance. The bloat effect happens because it is more likely to produce better offspring by adding instructions than by removing them, given an instruction editing distance from the optimal program. The analysis of the minimum hitting time suggests that for a basic LGP genetic operator (i.e., freemut), maintaining a necessarily small program size and mutating multiple instructions each time can improve LGP performance. The reported empirical results verify our hypothesis.
Symbolically Regressing Fish Biomass Spectral Data: A Linear Genetic Programming Method with Tunable Primitives
May 28, 2025Machine learning techniques play an important role in analyzing spectral data. The spectral data of fish biomass is useful in fish production, as it carries many important chemistry properties of fish meat. However, it is challenging for existing machine learning techniques to comprehensively discover hidden patterns from fish biomass spectral data since the spectral data often have a lot of noises while the training data are quite limited. To better analyze fish biomass spectral data, this paper models it as a symbolic regression problem and solves it by a linear genetic programming method with newly proposed tunable primitives. In the symbolic regression problem, linear genetic programming automatically synthesizes regression models based on the given primitives and training data. The tunable primitives further improve the approximation ability of the regression models by tuning their inherent coefficients. Our empirical results over ten fish biomass targets show that the proposed method improves the overall performance of fish biomass composition prediction. The synthesized regression models are compact and have good interpretability, which allow us to highlight useful features over the spectrum. Our further investigation also verifies the good generality of the proposed method across various spectral data treatments and other symbolic regression problems.
Multi-Representation Genetic Programming: A Case Study on Tree-based and Linear Representations
May 23, 2024



Existing genetic programming (GP) methods are typically designed based on a certain representation, such as tree-based or linear representations. These representations show various pros and cons in different domains. However, due to the complicated relationships among representation and fitness landscapes of GP, it is hard to intuitively determine which GP representation is the most suitable for solving a certain problem. Evolving programs (or models) with multiple representations simultaneously can alternatively search on different fitness landscapes since representations are highly related to the search space that essentially defines the fitness landscape. Fully using the latent synergies among different GP individual representations might be helpful for GP to search for better solutions. However, existing GP literature rarely investigates the simultaneous effective use of evolving multiple representations. To fill this gap, this paper proposes a multi-representation GP algorithm based on tree-based and linear representations, which are two commonly used GP representations. In addition, we develop a new cross-representation crossover operator to harness the interplay between tree-based and linear representations. Empirical results show that navigating the learned knowledge between basic tree-based and linear representations successfully improves the effectiveness of GP with solely tree-based or linear representation in solving symbolic regression and dynamic job shop scheduling problems.
Collaborative Attention Memory Network for Video Object Segmentation
May 23, 2022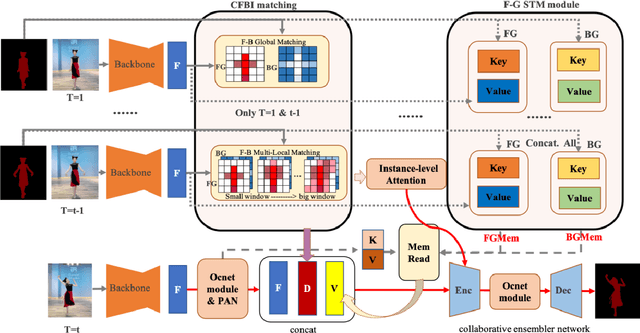
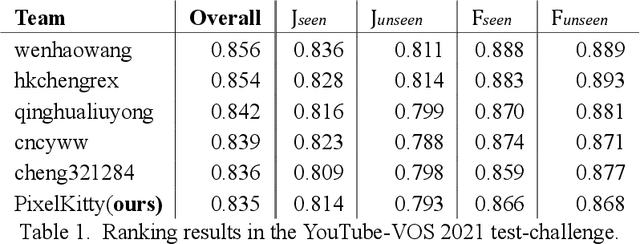
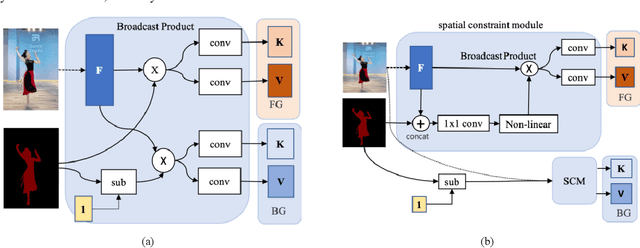

Semi-supervised video object segmentation is a fundamental yet Challenging task in computer vision. Embedding matching based CFBI series networks have achieved promising results by foreground-background integration approach. Despite its superior performance, these works exhibit distinct shortcomings, especially the false predictions caused by little appearance instances in first frame, even they could easily be recognized by previous frame. Moreover, they suffer from object's occlusion and error drifts. In order to overcome the shortcomings , we propose Collaborative Attention Memory Network with an enhanced segmentation head. We introduce a object context scheme that explicitly enhances the object information, which aims at only gathering the pixels that belong to the same category as a given pixel as its context. Additionally, a segmentation head with Feature Pyramid Attention(FPA) module is adopted to perform spatial pyramid attention structure on high-level output. Furthermore, we propose an ensemble network to combine STM network with all these new refined CFBI network. Finally, we evaluated our approach on the 2021 Youtube-VOS challenge where we obtain 6th place with an overall score of 83.5\%.