 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention
Apr 01, 2026Token-level sparse attention mechanisms, exemplified by DeepSeek Sparse Attention (DSA), achieve fine-grained key selection by scoring every historical key for each query through a lightweight indexer, then computing attention only on the selected subset. While the downstream sparse attention itself scales favorably, the indexer must still scan the entire prefix for every query, introducing an per-layer bottleneck that grows prohibitively with context length. We propose HISA (Hierarchical Indexed Sparse Attention), a plug-and-play replacement for the indexer that rewrites the search path from a flat token scan into a two-stage hierarchical procedure: (1) a block-level coarse filtering stage that scores pooled block representations to discard irrelevant regions, followed by (2) a token-level refinement stage that applies the original indexer exclusively within the retained candidate blocks. HISA preserves the identical token-level top-sparse pattern consumed by the downstream Sparse MLA operator and requires no additional training. On kernel-level benchmarks, HISA achieves up to speedup at 64K context. On Needle-in-a-Haystack and LongBench, we directly replace the indexer in DeepSeek-V3.2 and GLM-5 with our HISA indexer, without any finetuning. HISA closely matches the original DSA in quality, while substantially outperforming block-sparse baselines.
Privacy-Preserving Debiasing using Data Augmentation and Machine Unlearning
Apr 19, 2024Data augmentation is widely used to mitigate data bias in the training dataset. However, data augmentation exposes machine learning models to privacy attacks, such as membership inference attacks. In this paper, we propose an effective combination of data augmentation and machine unlearning, which can reduce data bias while providing a provable defense against known attacks. Specifically, we maintain the fairness of the trained model with diffusion-based data augmentation, and then utilize multi-shard unlearning to remove identifying information of original data from the ML model for protection against privacy attacks. Experimental evaluation across diverse datasets demonstrates that our approach can achieve significant improvements in bias reduction as well as robustness against state-of-the-art privacy attacks.
SDIP: Self-Reinforcement Deep Image Prior Framework for Image Processing
Apr 17, 2024Deep image prior (DIP) proposed in recent research has revealed the inherent trait of convolutional neural networks (CNN) for capturing substantial low-level image statistics priors. This framework efficiently addresses the inverse problems in image processing and has induced extensive applications in various domains. However, as the whole algorithm is initialized randomly, the DIP algorithm often lacks stability. Thus, this method still has space for further improvement. In this paper, we propose the self-reinforcement deep image prior (SDIP) as an improved version of the original DIP. We observed that the changes in the DIP networks' input and output are highly correlated during each iteration. SDIP efficiently utilizes this trait in a reinforcement learning manner, where the current iteration's output is utilized by a steering algorithm to update the network input for the next iteration, guiding the algorithm toward improved results. Experimental results across multiple applications demonstrate that our proposed SDIP framework offers improvement compared to the original DIP method and other state-of-the-art methods.
Hardware Acceleration of Explainable Artificial Intelligence
May 04, 2023



Machine learning (ML) is successful in achieving human-level artificial intelligence in various fields. However, it lacks the ability to explain an outcome due to its black-box nature. While recent efforts on explainable AI (XAI) has received significant attention, most of the existing solutions are not applicable in real-time systems since they map interpretability as an optimization problem, which leads to numerous iterations of time-consuming complex computations. Although there are existing hardware-based acceleration framework for XAI, they are implemented through FPGA and designed for specific tasks, leading to expensive cost and lack of flexibility. In this paper, we propose a simple yet efficient framework to accelerate various XAI algorithms with existing hardware accelerators. Specifically, this paper makes three important contributions. (1) The proposed method is the first attempt in exploring the effectiveness of Tensor Processing Unit (TPU) to accelerate XAI. (2) Our proposed solution explores the close relationship between several existing XAI algorithms with matrix computations, and exploits the synergy between convolution and Fourier transform, which takes full advantage of TPU's inherent ability in accelerating matrix computations. (3) Our proposed approach can lead to real-time outcome interpretation. Extensive experimental evaluation demonstrates that proposed approach deployed on TPU can provide drastic improvement in interpretation time (39x on average) as well as energy efficiency (69x on average) compared to existing acceleration techniques.
Backdoor Attacks on Bayesian Neural Networks using Reverse Distribution
May 18, 2022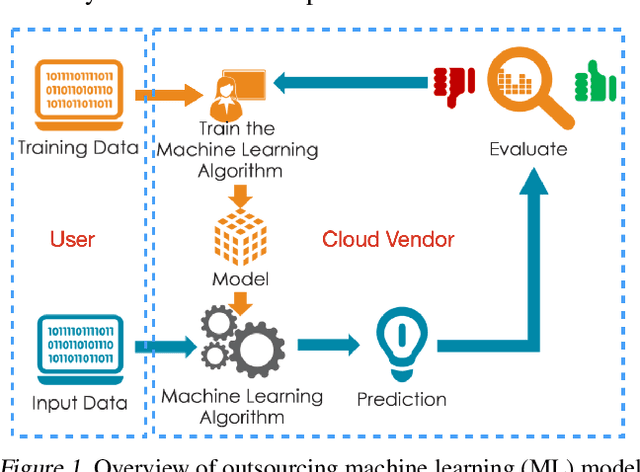

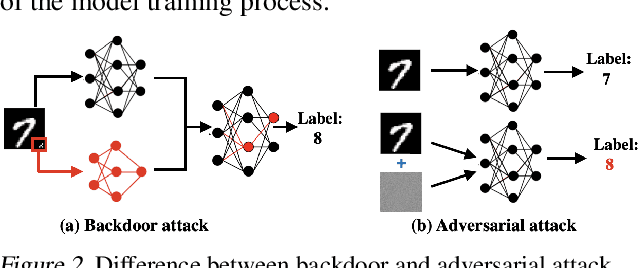
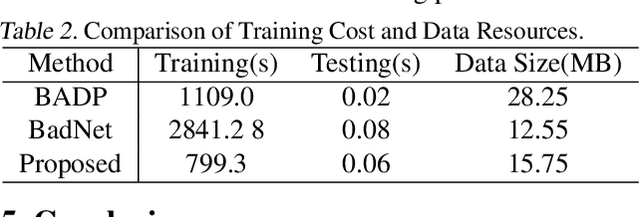
Due to cost and time-to-market constraints, many industries outsource the training process of machine learning models (ML) to third-party cloud service providers, popularly known as ML-asa-Service (MLaaS). MLaaS creates opportunity for an adversary to provide users with backdoored ML models to produce incorrect predictions only in extremely rare (attacker-chosen) scenarios. Bayesian neural networks (BNN) are inherently immune against backdoor attacks since the weights are designed to be marginal distributions to quantify the uncertainty. In this paper, we propose a novel backdoor attack based on effective learning and targeted utilization of reverse distribution. This paper makes three important contributions. (1) To the best of our knowledge, this is the first backdoor attack that can effectively break the robustness of BNNs. (2) We produce reverse distributions to cancel the original distributions when the trigger is activated. (3) We propose an efficient solution for merging probability distributions in BNNs. Experimental results on diverse benchmark datasets demonstrate that our proposed attack can achieve the attack success rate (ASR) of 100%, while the ASR of the state-of-the-art attacks is lower than 60%.
Fast Approximate Spectral Normalization for Robust Deep Neural Networks
Mar 22, 2021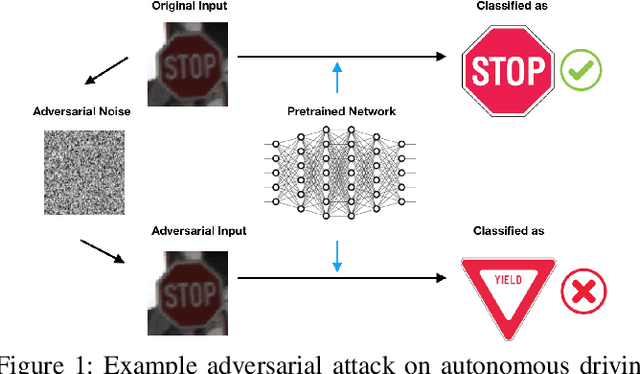
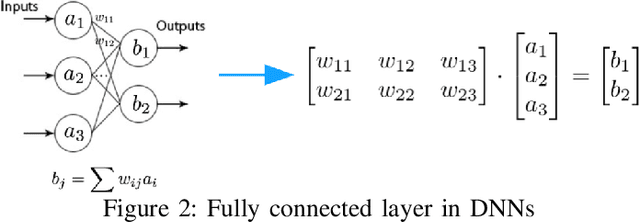
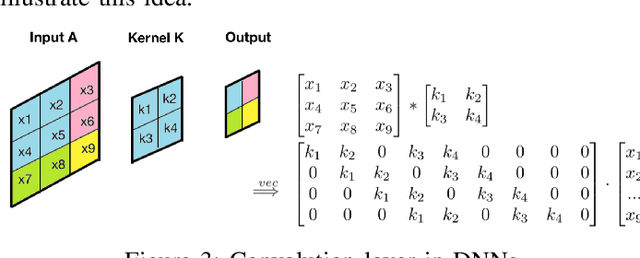
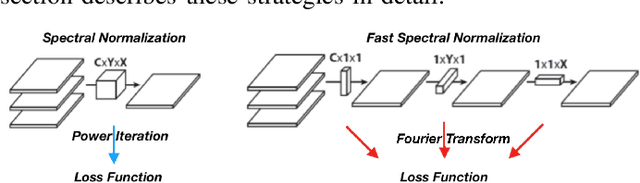
Deep neural networks (DNNs) play an important role in machine learning due to its outstanding performance compared to other alternatives. However, DNNs are not suitable for safety-critical applications since DNNs can be easily fooled by well-crafted adversarial examples. One promising strategy to counter adversarial attacks is to utilize spectral normalization, which ensures that the trained model has low sensitivity towards the disturbance of input samples. Unfortunately, this strategy requires exact computation of spectral norm, which is computation intensive and impractical for large-scale networks. In this paper, we introduce an approximate algorithm for spectral normalization based on Fourier transform and layer separation. The primary contribution of our work is to effectively combine the sparsity of weight matrix and decomposability of convolution layers. Extensive experimental evaluation demonstrates that our framework is able to significantly improve both time efficiency (up to 60\%) and model robustness (61\% on average) compared with the state-of-the-art spectral normalization.
Hardware Acceleration of Explainable Machine Learning using Tensor Processing Units
Mar 22, 2021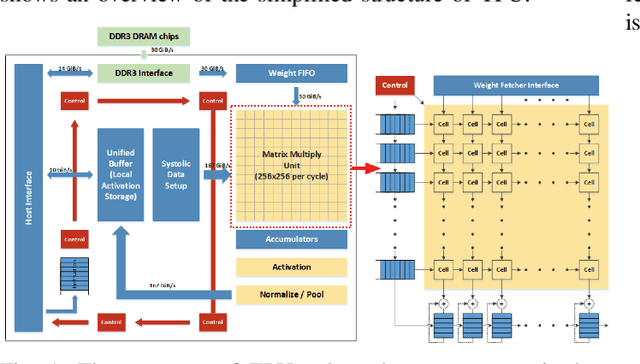
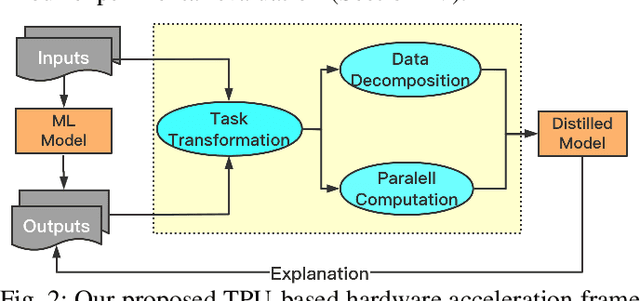
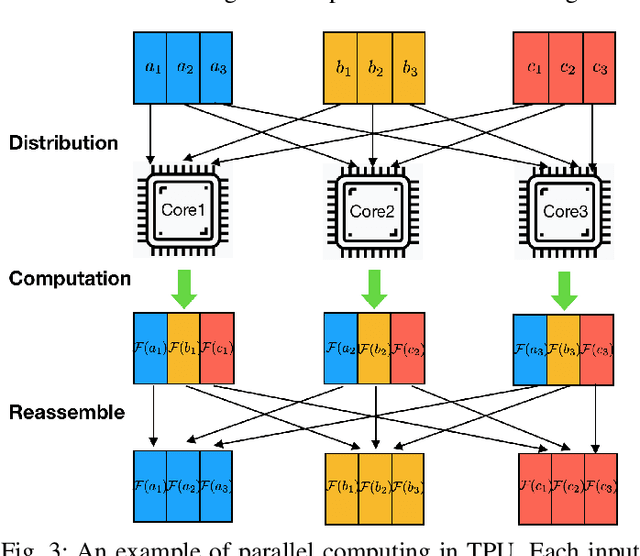
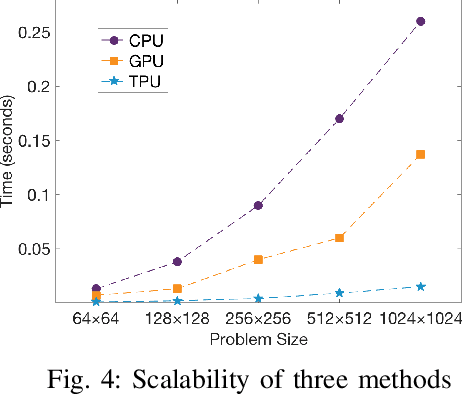
Machine learning (ML) is successful in achieving human-level performance in various fields. However, it lacks the ability to explain an outcome due to its black-box nature. While existing explainable ML is promising, almost all of these methods focus on formatting interpretability as an optimization problem. Such a mapping leads to numerous iterations of time-consuming complex computations, which limits their applicability in real-time applications. In this paper, we propose a novel framework for accelerating explainable ML using Tensor Processing Units (TPUs). The proposed framework exploits the synergy between matrix convolution and Fourier transform, and takes full advantage of TPU's natural ability in accelerating matrix computations. Specifically, this paper makes three important contributions. (1) To the best of our knowledge, our proposed work is the first attempt in enabling hardware acceleration of explainable ML using TPUs. (2) Our proposed approach is applicable across a wide variety of ML algorithms, and effective utilization of TPU-based acceleration can lead to real-time outcome interpretation. (3) Extensive experimental results demonstrate that our proposed approach can provide an order-of-magnitude speedup in both classification time (25x on average) and interpretation time (13x on average) compared to state-of-the-art techniques.