 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDIP: Self-Reinforcement Deep Image Prior Framework for Image Processing
Apr 17, 2024Deep image prior (DIP) proposed in recent research has revealed the inherent trait of convolutional neural networks (CNN) for capturing substantial low-level image statistics priors. This framework efficiently addresses the inverse problems in image processing and has induced extensive applications in various domains. However, as the whole algorithm is initialized randomly, the DIP algorithm often lacks stability. Thus, this method still has space for further improvement. In this paper, we propose the self-reinforcement deep image prior (SDIP) as an improved version of the original DIP. We observed that the changes in the DIP networks' input and output are highly correlated during each iteration. SDIP efficiently utilizes this trait in a reinforcement learning manner, where the current iteration's output is utilized by a steering algorithm to update the network input for the next iteration, guiding the algorithm toward improved results. Experimental results across multiple applications demonstrate that our proposed SDIP framework offers improvement compared to the original DIP method and other state-of-the-art methods.
A Global Constraint to Improve CT Reconstruction Under Non-Ideal Conditions
Dec 19, 2022Background and Objective: The strong demand for medical imaging applications leads to the popularity of the CT reconstruction problem. Researchers proposed multiple constraints to tackle none ideal factors in CT reconstruction such as sparse-view, limited-angle, and low-dose conditions. Most of these constraints such as total variation are local constraints focusing on the relationship between a pixel and its neighbors. In this paper, we propose a new constraint utilizing the global prior of CT images to greatly reduce the streak artifacts and further improve the reconstruction accuracy. Methods: A CT image of the human body contains a limited number of different types of tissues, so pixels in CT images can be grouped into several groups according to their corresponding types. In our work, we focus on the composition classification for individual pixels and utilize it as a global prior, which differs from priors utilized by most current constraints. We propose segmenting pixels based on their gray levels during the reconstruction process, and forcing pixels in the same group to have similar gray levels. Results: Our experiments on the Shepp-Logan phantom and two real CT images from different benchmarks show that the proposed constraint can help the conventional local constraints further improve the reconstruction results under sparse-view, limited-angle, and low-dose conditions. Conclusions: Different from most current constraints focusing on the local prior, our proposed constraint only utilizes the global prior of CT images. In that case, our proposed constraint can collaborate with most local constraints and improve the reconstruction quality significantly. Furthermore, the proposed constraint also has the potential for further improvement, as the composition classification can be done with some more delicate methods, such as neural network related semantic segmentation algorithms.
RBP-DIP: High-Quality CT Reconstruction Using an Untrained Neural Network with Residual Back Projection and Deep Image Prior
Oct 26, 2022Neural network related methods, due to their unprecedented success in image processing, have emerged as a new set of tools in CT reconstruction with the potential to change the field. However, the lack of high-quality training data and theoretical guarantees, together with increasingly complicated network structures, make its implementation impractical. In this paper, we present a new framework (RBP-DIP) based on Deep Image Prior (DIP) and a special residual back projection (RBP) connection to tackle these challenges. Comparing to other pre-trained neural network related algorithms, the proposed framework is closer to an iterative reconstruction (IR) algorithm as it requires no training data or training process. In that case, the proposed framework can be altered (e.g, different hyperparameters and constraints) on demand, adapting to different conditions (e.g, different imaged objects, imaging instruments, and noise levels) without retraining. Experiments show that the proposed framework has significant improvements over other state-of-the-art conventional methods, as well as pre-trained and untrained models with similar network structures, especially under sparse-view, limited-angle, and low-dose conditions.
Gram filtering and sinogram interpolation for pixel-basis in parallel-beam X-ray CT reconstruction
May 27, 2020
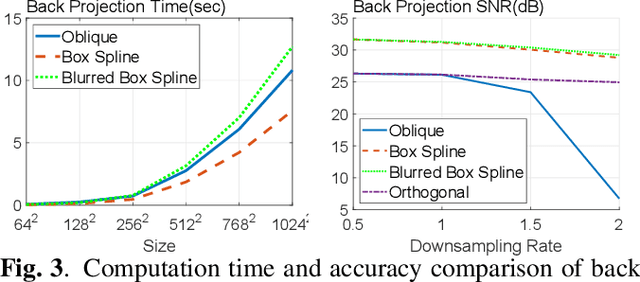
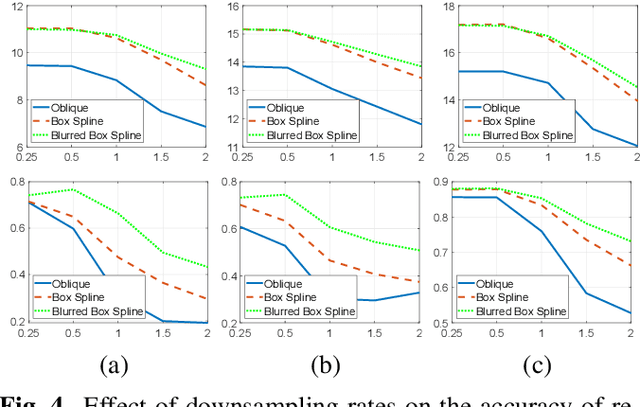
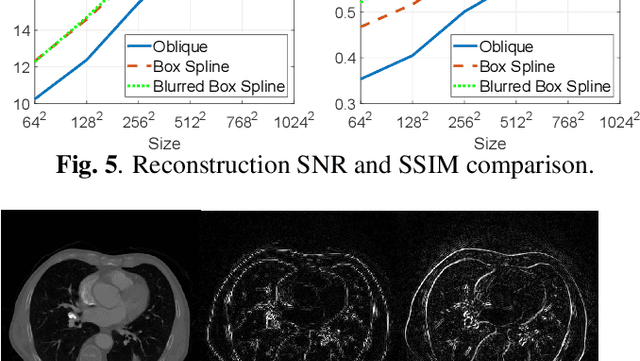
The key aspect of parallel-beam X-ray CT is forward and back projection, but its computational burden continues to be an obstacle for applications. We propose a method to improve the performance of related algorithms by calculating the Gram filter exactly and interpolating the sinogram signal optimally. In addition, the detector blur effect can be included in our model efficiently. The improvements in speed and quality for back projection and iterative reconstruction are shown in our experiments on both analytical phantoms and real CT images.