 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures
Aug 06, 2022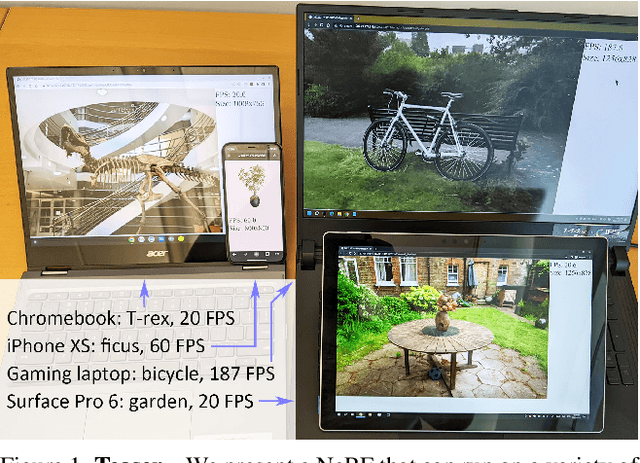

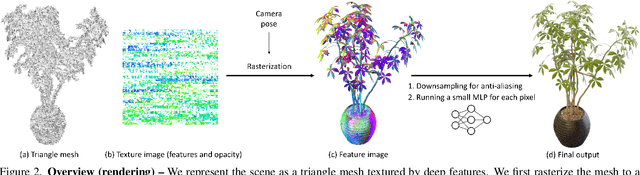
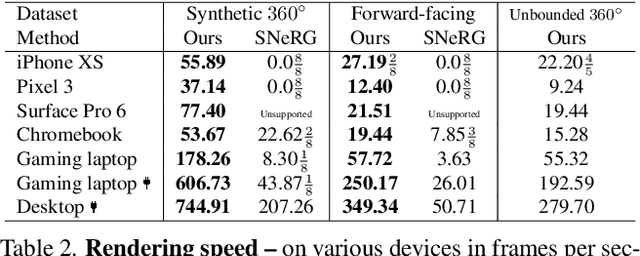
Neural Radiance Fields (NeRFs) have demonstrated amazing ability to synthesize images of 3D scenes from novel views. However, they rely upon specialized volumetric rendering algorithms based on ray marching that are mismatched to the capabilities of widely deployed graphics hardware. This paper introduces a new NeRF representation based on textured polygons that can synthesize novel images efficiently with standard rendering pipelines. The NeRF is represented as a set of polygons with textures representing binary opacities and feature vectors. Traditional rendering of the polygons with a z-buffer yields an image with features at every pixel, which are interpreted by a small, view-dependent MLP running in a fragment shader to produce a final pixel color. This approach enables NeRFs to be rendered with the traditional polygon rasterization pipeline, which provides massive pixel-level parallelism, achieving interactive frame rates on a wide range of compute platforms, including mobile phones.
AUV-Net: Learning Aligned UV Maps for Texture Transfer and Synthesis
Apr 06, 2022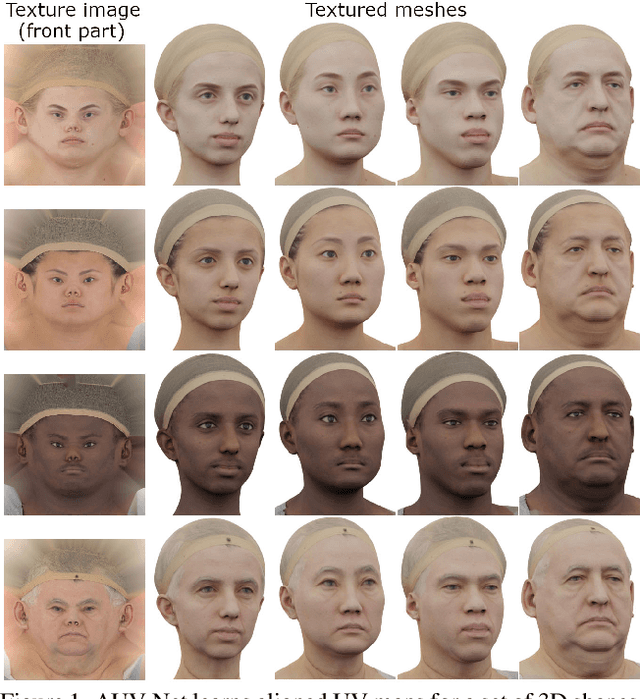


In this paper, we address the problem of texture representation for 3D shapes for the challenging and underexplored tasks of texture transfer and synthesis. Previous works either apply spherical texture maps which may lead to large distortions, or use continuous texture fields that yield smooth outputs lacking details. We argue that the traditional way of representing textures with images and linking them to a 3D mesh via UV mapping is more desirable, since synthesizing 2D images is a well-studied problem. We propose AUV-Net which learns to embed 3D surfaces into a 2D aligned UV space, by mapping the corresponding semantic parts of different 3D shapes to the same location in the UV space. As a result, textures are aligned across objects, and can thus be easily synthesized by generative models of images. Texture alignment is learned in an unsupervised manner by a simple yet effective texture alignment module, taking inspiration from traditional works on linear subspace learning. The learned UV mapping and aligned texture representations enable a variety of applications including texture transfer, texture synthesis, and textured single view 3D reconstruction. We conduct experiments on multiple datasets to demonstrate the effectiveness of our method. Project page: https://nv-tlabs.github.io/AUV-NET.
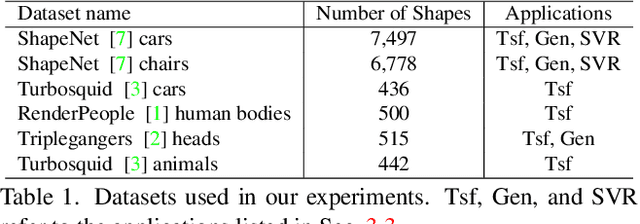
Neural Dual Contouring
Feb 04, 2022
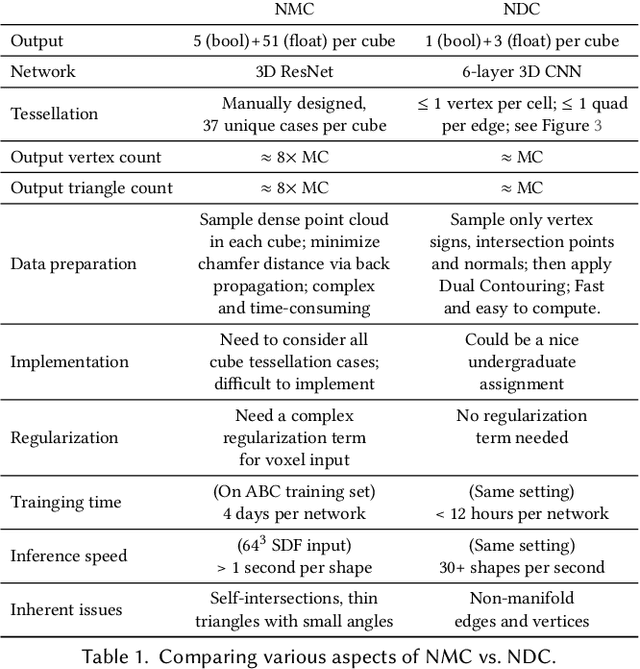
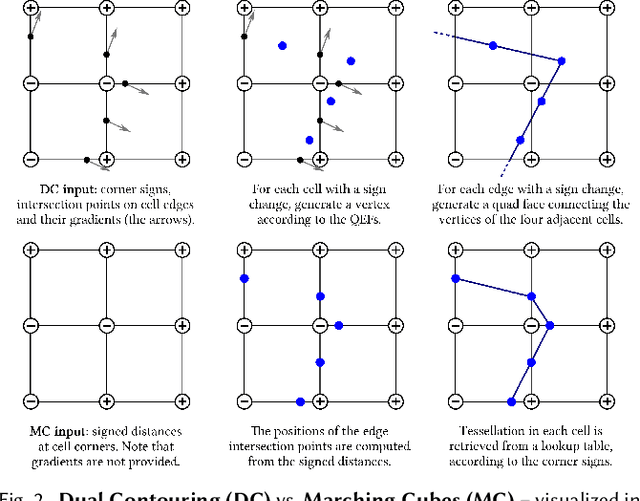
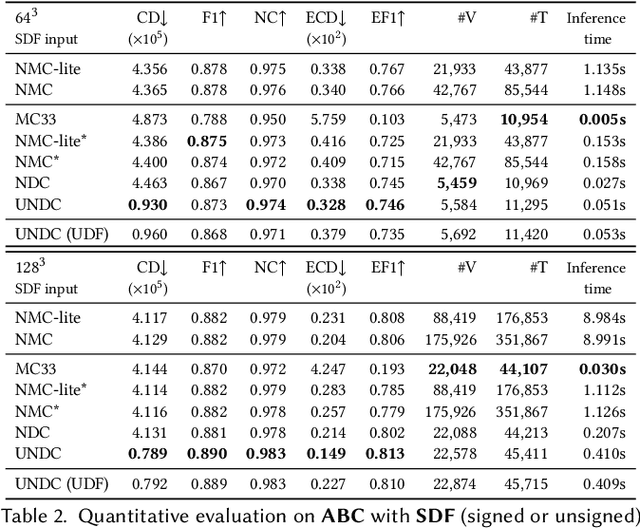
We introduce neural dual contouring (NDC), a new data-driven approach to mesh reconstruction based on dual contouring (DC). Like traditional DC, it produces exactly one vertex per grid cell and one quad for each grid edge intersection, a natural and efficient structure for reproducing sharp features. However, rather than computing vertex locations and edge crossings with hand-crafted functions that depend directly on difficult-to-obtain surface gradients, NDC uses a neural network to predict them. As a result, NDC can be trained to produce meshes from signed or unsigned distance fields, binary voxel grids, or point clouds (with or without normals); and it can produce open surfaces in cases where the input represents a sheet or partial surface. During experiments with five prominent datasets, we find that NDC, when trained on one of the datasets, generalizes well to the others. Furthermore, NDC provides better surface reconstruction accuracy, feature preservation, output complexity, triangle quality, and inference time in comparison to previous learned (e.g., neural marching cubes, convolutional occupancy networks) and traditional (e.g., Poisson) methods.
Learning Mesh Representations via Binary Space Partitioning Tree Networks
Jul 02, 2021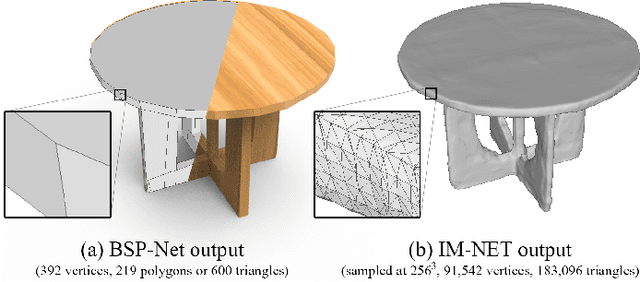
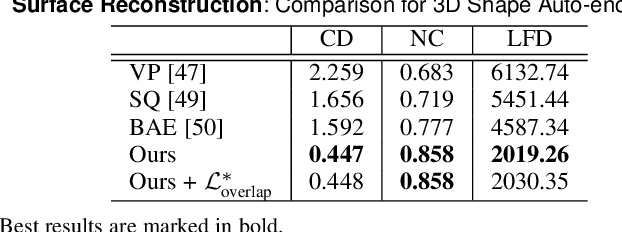
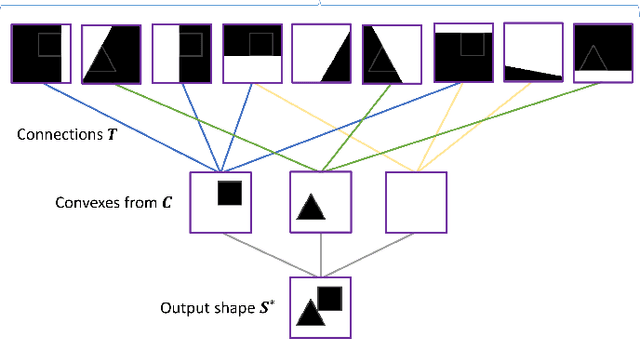
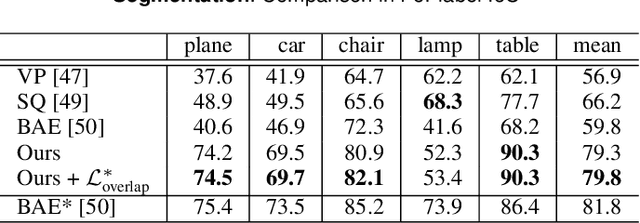
Polygonal meshes are ubiquitous, but have only played a relatively minor role in the deep learning revolution. State-of-the-art neural generative models for 3D shapes learn implicit functions and generate meshes via expensive iso-surfacing. We overcome these challenges by employing a classical spatial data structure from computer graphics, Binary Space Partitioning (BSP), to facilitate 3D learning. The core operation of BSP involves recursive subdivision of 3D space to obtain convex sets. By exploiting this property, we devise BSP-Net, a network that learns to represent a 3D shape via convex decomposition without supervision. The network is trained to reconstruct a shape using a set of convexes obtained from a BSP-tree built over a set of planes, where the planes and convexes are both defined by learned network weights. BSP-Net directly outputs polygonal meshes from the inferred convexes. The generated meshes are watertight, compact (i.e., low-poly), and well suited to represent sharp geometry. We show that the reconstruction quality by BSP-Net is competitive with those from state-of-the-art methods while using much fewer primitives. We also explore variations to BSP-Net including using a more generic decoder for reconstruction, more general primitives than planes, as well as training a generative model with variational auto-encoders. Code is available at https://github.com/czq142857/BSP-NET-original.
Neural Marching Cubes
Jul 02, 2021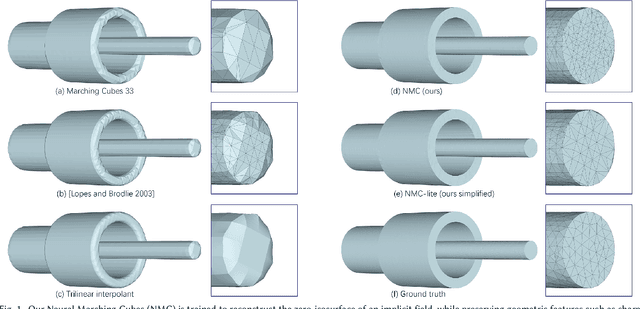
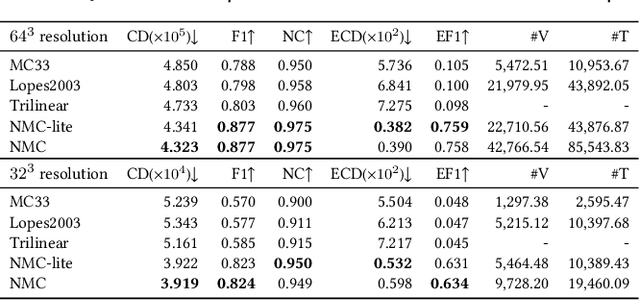
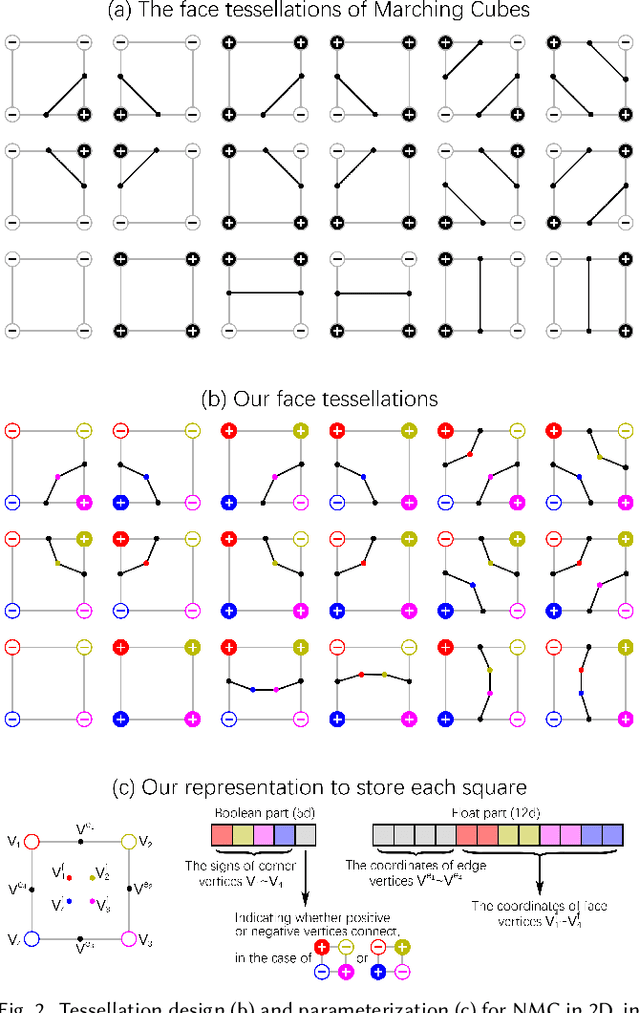
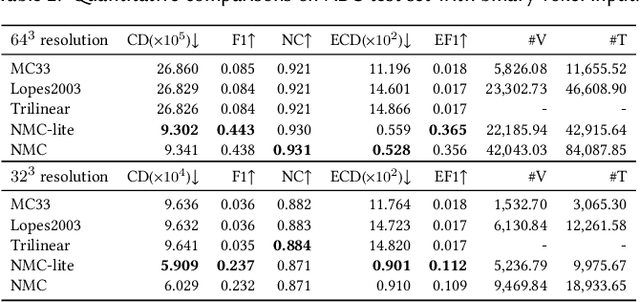
We introduce Neural Marching Cubes (NMC), a data-driven approach for extracting a triangle mesh from a discretized implicit field. Classical MC is defined by coarse tessellation templates isolated to individual cubes. While more refined tessellations have been proposed, they all make heuristic assumptions, such as trilinearity, when determining the vertex positions and local mesh topologies in each cube. In principle, none of these approaches can reconstruct geometric features that reveal coherence or dependencies between nearby cubes (e.g., a sharp edge), as such information is unaccounted for, resulting in poor estimates of the true underlying implicit field. To tackle these challenges, we re-cast MC from a deep learning perspective, by designing tessellation templates more apt at preserving geometric features, and learning the vertex positions and mesh topologies from training meshes, to account for contextual information from nearby cubes. We develop a compact per-cube parameterization to represent the output triangle mesh, while being compatible with neural processing, so that a simple 3D convolutional network can be employed for the training. We show that all topological cases in each cube that are applicable to our design can be easily derived using our representation, and the resulting tessellations can also be obtained naturally and efficiently by following a few design guidelines. In addition, our network learns local features with limited receptive fields, hence it generalizes well to new shapes and new datasets. We evaluate our neural MC approach by quantitative and qualitative comparisons to all well-known MC variants. In particular, we demonstrate the ability of our network to recover sharp features such as edges and corners, a long-standing issue of MC and its variants. Our network also reconstructs local mesh topologies more accurately than previous approaches.
CAPRI-Net: Learning Compact CAD Shapes with Adaptive Primitive Assembly
Apr 12, 2021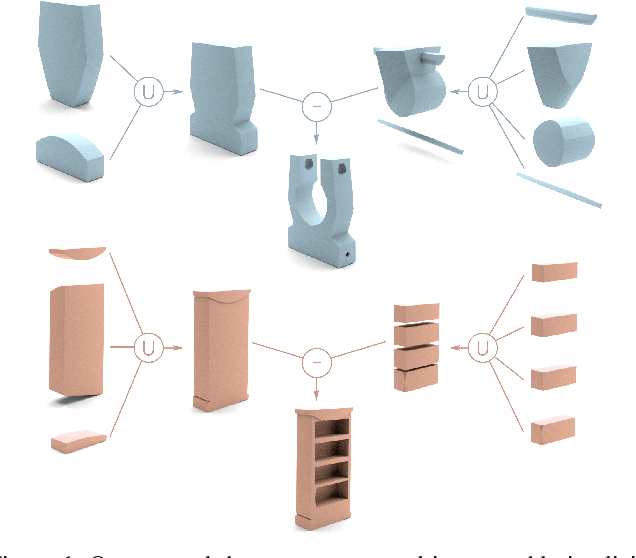
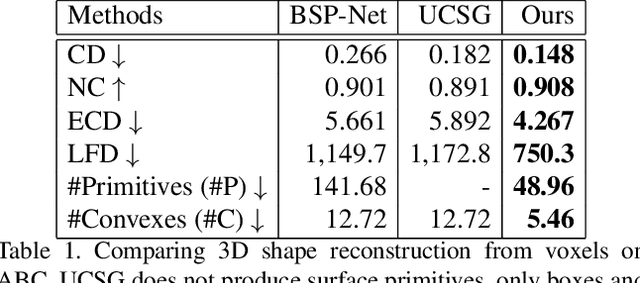

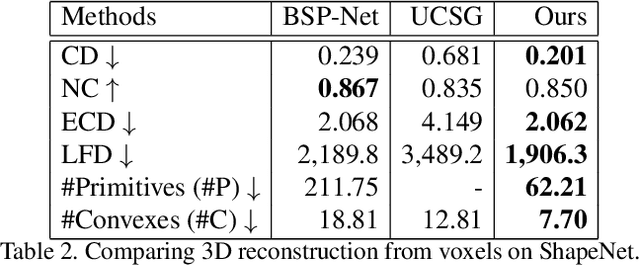
We introduce CAPRI-Net, a neural network for learning compact and interpretable implicit representations of 3D computer-aided design (CAD) models, in the form of adaptive primitive assemblies. Our network takes an input 3D shape that can be provided as a point cloud or voxel grids, and reconstructs it by a compact assembly of quadric surface primitives via constructive solid geometry (CSG) operations. The network is self-supervised with a reconstruction loss, leading to faithful 3D reconstructions with sharp edges and plausible CSG trees, without any ground-truth shape assemblies. While the parametric nature of CAD models does make them more predictable locally, at the shape level, there is a great deal of structural and topological variations, which present a significant generalizability challenge to state-of-the-art neural models for 3D shapes. Our network addresses this challenge by adaptive training with respect to each test shape, with which we fine-tune the network that was pre-trained on a model collection. We evaluate our learning framework on both ShapeNet and ABC, the largest and most diverse CAD dataset to date, in terms of reconstruction quality, shape edges, compactness, and interpretability, to demonstrate superiority over current alternatives suitable for neural CAD reconstruction.
DECOR-GAN: 3D Shape Detailization by Conditional Refinement
Dec 16, 2020

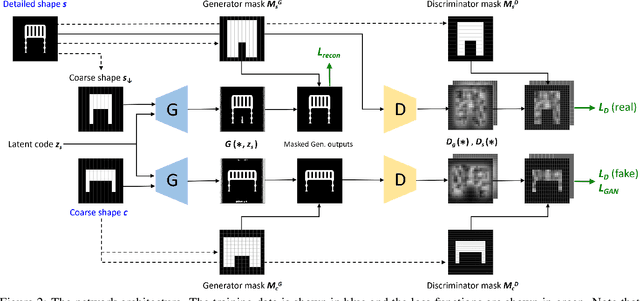
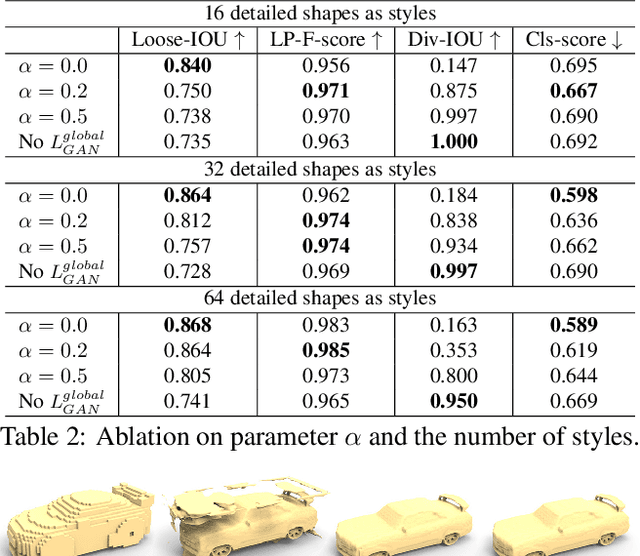
We introduce a deep generative network for 3D shape detailization, akin to stylization with the style being geometric details. We address the challenge of creating large varieties of high-resolution and detailed 3D geometry from a small set of exemplars by treating the problem as that of geometric detail transfer. Given a low-resolution coarse voxel shape, our network refines it, via voxel upsampling, into a higher-resolution shape enriched with geometric details. The output shape preserves the overall structure (or content) of the input, while its detail generation is conditioned on an input "style code" corresponding to a detailed exemplar. Our 3D detailization via conditional refinement is realized by a generative adversarial network, coined DECOR-GAN. The network utilizes a 3D CNN generator for upsampling coarse voxels and a 3D PatchGAN discriminator to enforce local patches of the generated model to be similar to those in the training detailed shapes. During testing, a style code is fed into the generator to condition the refinement. We demonstrate that our method can refine a coarse shape into a variety of detailed shapes with different styles. The generated results are evaluated in terms of content preservation, plausibility, and diversity. Comprehensive ablation studies are conducted to validate our network designs.
COALESCE: Component Assembly by Learning to Synthesize Connections
Aug 05, 2020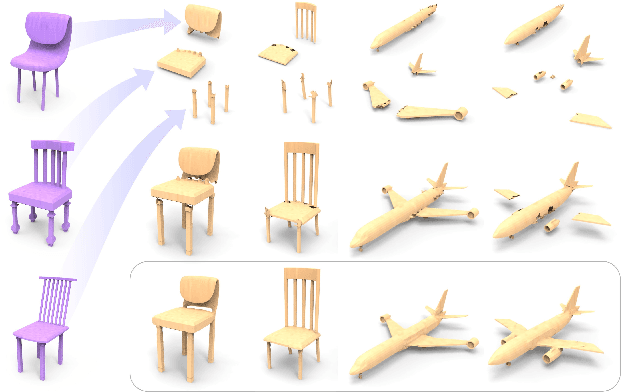
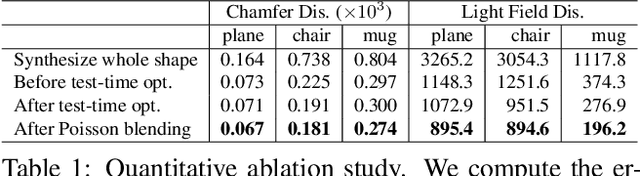
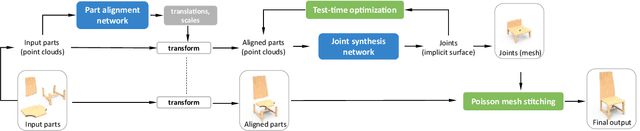
We introduce COALESCE, the first data-driven framework for component-based shape assembly which employs deep learning to synthesize part connections. To handle geometric and topological mismatches between parts, we remove the mismatched portions via erosion, and rely on a joint synthesis step, which is learned from data, to fill the gap and arrive at a natural and plausible part joint. Given a set of input parts extracted from different objects, COALESCE automatically aligns them and synthesizes plausible joints to connect the parts into a coherent 3D object represented by a mesh. The joint synthesis network, designed to focus on joint regions, reconstructs the surface between the parts by predicting an implicit shape representation that agrees with existing parts, while generating a smooth and topologically meaningful connection. We employ test-time optimization to further ensure that the synthesized joint region closely aligns with the input parts to create realistic component assemblies from diverse input parts. We demonstrate that our method significantly outperforms prior approaches including baseline deep models for 3D shape synthesis, as well as state-of-the-art methods for shape completion.
BSP-Net: Generating Compact Meshes via Binary Space Partitioning
Nov 16, 2019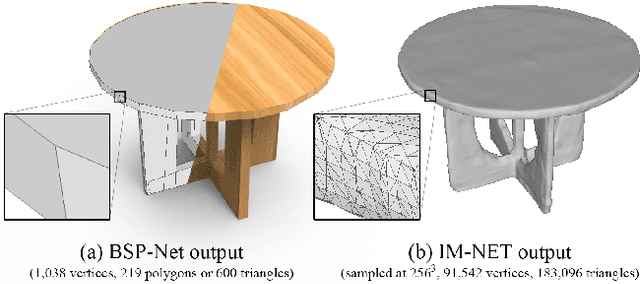
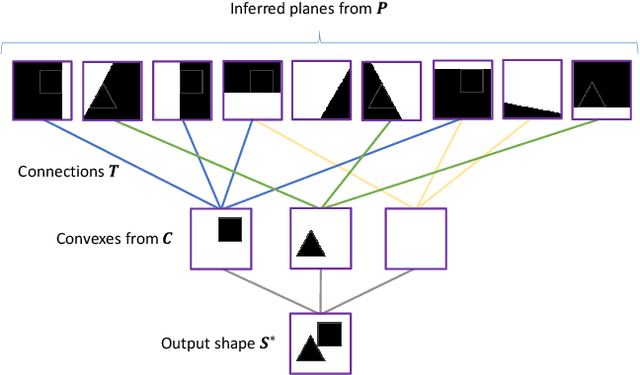
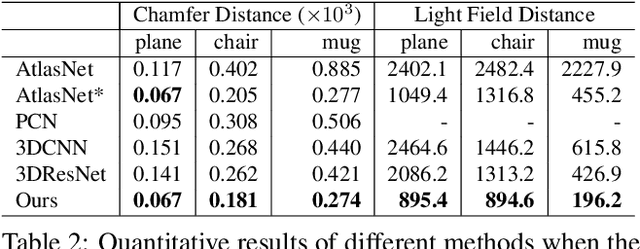
Polygonal meshes are ubiquitous in the digital 3D domain, yet they have only played a minor role in the deep learning revolution. Leading methods for learning generative models of shapes rely on implicit functions, and generate meshes only after expensive iso-surfacing routines. To overcome these challenges, we are inspired by a classical spatial data structure from computer graphics, Binary Space Partitioning (BSP), to facilitate 3D learning. The core ingredient of BSP is an operation for recursive subdivision of space to obtain convex sets. By exploiting this property, we devise BSP-Net, a network that learns to represent a 3D shape via convex decomposition. Importantly, BSP-Net is unsupervised since no convex shape decompositions are needed for training. The network is trained to reconstruct a shape using a set of convexes obtained from a BSP-tree built on a set of planes. The convexes inferred by BSP-Net can be easily extracted to form a polygon mesh, without any need for iso-surfacing. The generated meshes are compact (i.e., low-poly) and well suited to represent sharp geometry; they are guaranteed to be watertight and can be easily parameterized. We also show that the reconstruction quality by BSP-Net is competitive with state-of-the-art methods while using much fewer primitives.
BAE-NET: Branched Autoencoder for Shape Co-Segmentation
Mar 27, 2019

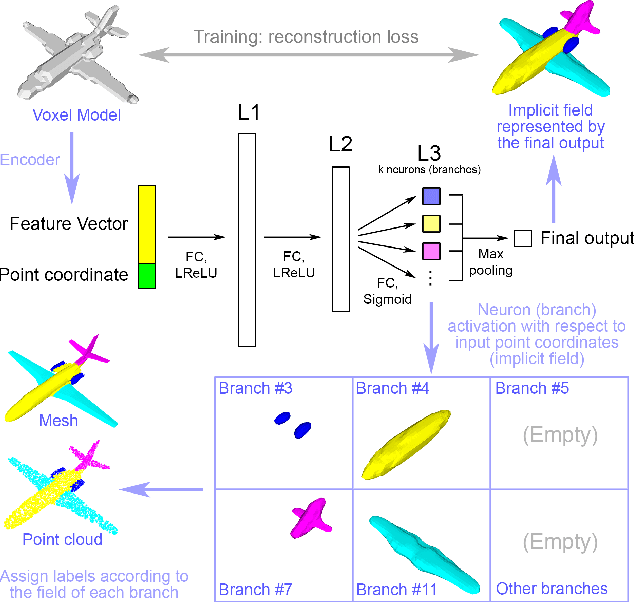
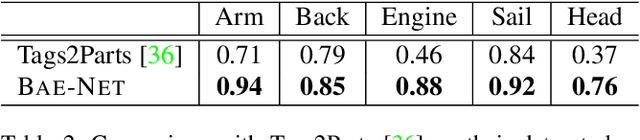
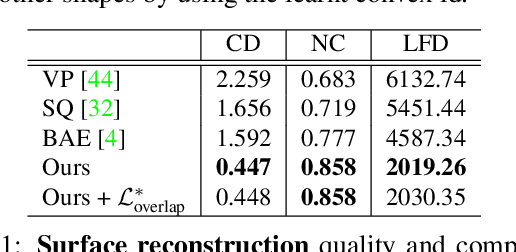
We treat shape co-segmentation as a representation learning problem and introduce BAE-NET, a branched autoencoder network, for the task. The unsupervised BAE-NET is trained with all shapes in an input collection using a shape reconstruction loss, without ground-truth segmentations. Specifically, the network takes an input shape and encodes it using a convolutional neural network, whereas the decoder concatenates the resulting feature code with a point coordinate and outputs a value indicating whether the point is inside/outside the shape. Importantly, the decoder is branched: each branch learns a compact representation for one commonly recurring part of the shape collection, e.g., airplane wings. By complementing the shape reconstruction loss with a label loss, BAE-NET is easily tuned for one-shot learning. We show unsupervised, weakly supervised, and one-shot learning results by BAE-NET, demonstrating that using only a couple of exemplars, our network can generally outperform state-of-the-art supervised methods trained on hundreds of segmented shapes.