 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-as-Peer-Debriefer: A Multi-Agent Framework with Perspective-Based Refinement for Qualitative Analysis
May 23, 2026Large language models (LLMs) are increasingly used for qualitative data analysis (QDA), yet their outputs often miss the depth and nuance of human analysis. We argue this gap reflects a missing credibility practice from human QDA: peer debriefing, in which an analyst seeks feedback from a disinterested peer and uses it to refine their coding. To bring this practice into LLM-assisted QDA, we propose Agent-as-Peer-Debriefer, a multi-agent QDA framework that builds peer debriefing into key coding steps. In our framework, a Hierarchical Coding Agent follows the standard QDA process to generate codes, sub-themes, and themes, along with self-explanations and reflection memos. It then shares these outputs with three Peer-Debriefing Agents, each applying a distinct analytical perspective (Theory-Driven, Data-Driven, or Applied) and refining the codes by keeping, renaming, reassigning, merging, or splitting them. These perspectives are drawn from established human QDA practices that generalize across domains and datasets. To evaluate the framework, we test it on three datasets across two domains with three LLMs, measuring semantic similarity to human-annotated codes. Across all settings, perspective-based, peer-debriefing refinement aligns more closely with human codes than a single-LLM baseline, and an ablation further shows the gain is not merely from additional refinement. The three perspectives also produce distinct trade-offs, showing that the choice of perspective is a meaningful and controllable design decision. More broadly, these findings suggest that simulating peer debriefing with explicit perspectives is a promising route to more credible LLM-assisted QDA.
LongCat-Flash-Prover: Advancing Native Formal Reasoning via Agentic Tool-Integrated Reinforcement Learning
Mar 22, 2026We introduce LongCat-Flash-Prover, a flagship 560-billion-parameter open-source Mixture-of- Experts (MoE) model that advances Native Formal Reasoning in Lean4 through agentic tool-integrated reasoning (TIR). We decompose the native formal reasoning task into three independent formal capabilities, i.e., auto-formalization, sketching, and proving. To facilitate these capabilities, we propose a Hybrid-Experts Iteration Framework to expand high-quality task trajectories, including generating a formal statement based on a given informal problem, producing a whole-proof directly from the statement, or a lemma-style sketch. During agentic RL, we present a Hierarchical Importance Sampling Policy Optimization (HisPO) algorithm, which aims to stabilize the MoE model training on such long-horizon tasks. It employs a gradient masking strategy that accounts for the policy staleness and the inherent train-inference engine discrepancies at both sequence and token levels. Additionally, we also incorporate theorem consistency and legality detection mechanisms to eliminate reward hacking issues. Extensive evaluations show that our LongCat-Flash-Prover sets a new state-of-the-art for open-weights models in both auto-formalization and theorem proving. Demonstrating remarkable sample efficiency, it achieves a 97.1% pass rate on MiniF2F-Test using only 72 inference budget per problem. On more challenging benchmarks, it solves 70.8% of ProverBench and 41.5% of PutnamBench with no more than 220 attempts per problem, significantly outperforming existing open-weights baselines.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Multimodal Feature Fusion for Video Advertisements Tagging Via Stacking Ensemble
Aug 02, 2021
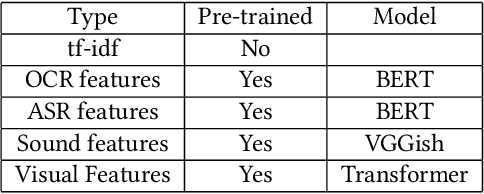
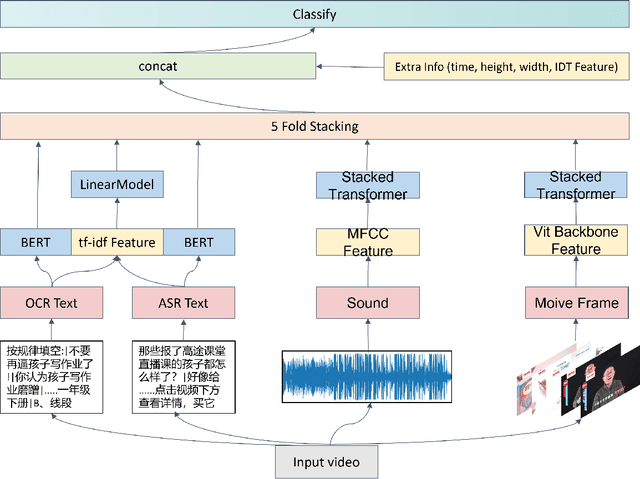
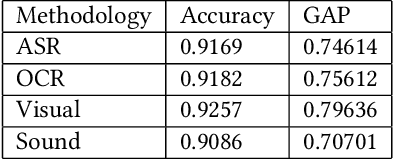
Automated tagging of video advertisements has been a critical yet challenging problem, and it has drawn increasing interests in last years as its applications seem to be evident in many fields. Despite sustainable efforts have been made, the tagging task is still suffered from several challenges, such as, efficiently feature fusion approach is desirable, but under-explored in previous studies. In this paper, we present our approach for Multimodal Video Ads Tagging in the 2021 Tencent Advertising Algorithm Competition. Specifically, we propose a novel multi-modal feature fusion framework, with the goal to combine complementary information from multiple modalities. This framework introduces stacking-based ensembling approach to reduce the influence of varying levels of noise and conflicts between different modalities. Thus, our framework can boost the performance of the tagging task, compared to previous methods. To empirically investigate the effectiveness and robustness of the proposed framework, we conduct extensive experiments on the challenge datasets. The obtained results suggest that our framework can significantly outperform related approaches and our method ranks as the 1st place on the final leaderboard, with a Global Average Precision (GAP) of 82.63%. To better promote the research in this field, we will release our code in the final version.