 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative User Simulator with GPT-based Architecture and Goal State Tracking for Reinforced Multi-Domain Dialog Systems
Oct 18, 2022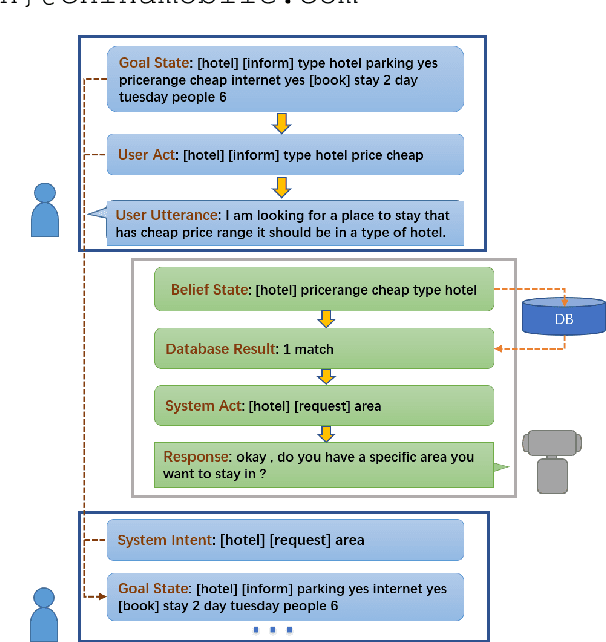
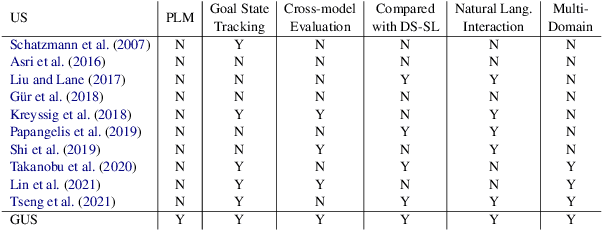
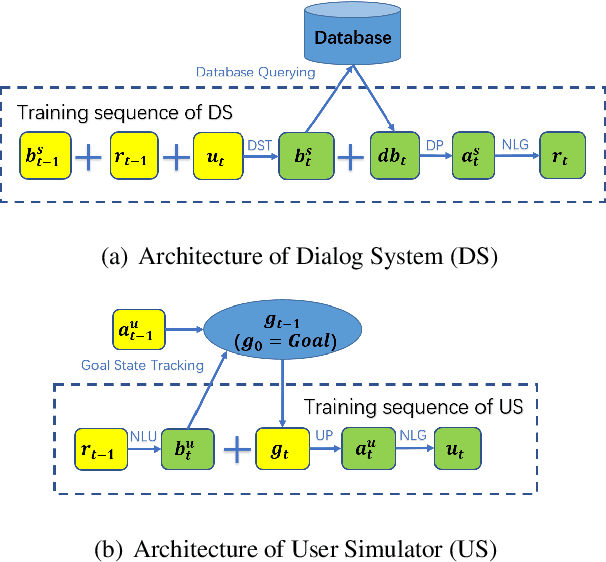
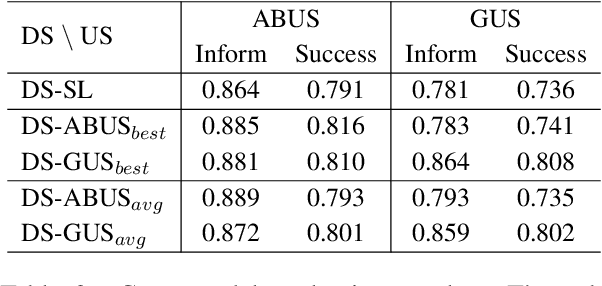
Building user simulators (USs) for reinforcement learning (RL) of task-oriented dialog systems (DSs) has gained more and more attention, which, however, still faces several fundamental challenges. First, it is unclear whether we can leverage pretrained language models to design, for example, GPT-2 based USs, to catch up and interact with the recently advanced GPT-2 based DSs. Second, an important ingredient in a US is that the user goal can be effectively incorporated and tracked; but how to flexibly integrate goal state tracking and develop an end-to-end trainable US for multi-domains has remained to be a challenge. In this work, we propose a generative user simulator (GUS) with GPT-2 based architecture and goal state tracking towards addressing the above two challenges. Extensive experiments are conducted on MultiWOZ2.1. Different DSs are trained via RL with GUS, the classic agenda-based user simulator (ABUS) and other ablation simulators respectively, and are compared for cross-model evaluation, corpus-based evaluation and human evaluation. The GUS achieves superior results in all three evaluation tasks.
Jointly Reinforced User Simulator and Task-oriented Dialog System with Simplified Generative Architecture
Oct 13, 2022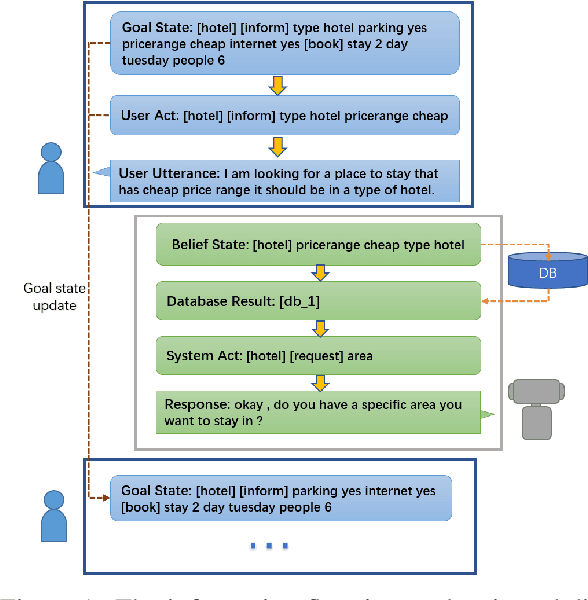
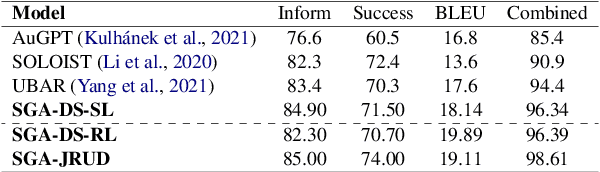
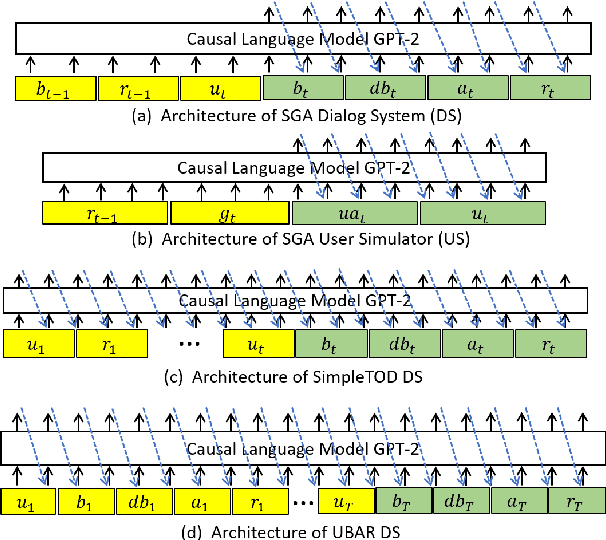
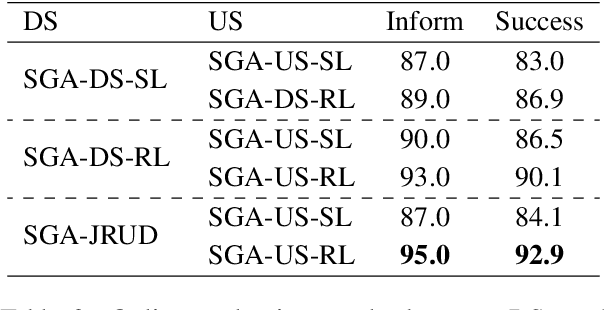
Recently, there has been progress in supervised funetuning pretrained GPT-2 to build end-to-end task-oriented dialog (TOD) systems. However, online reinforcement learning of a GPT-2 based dialog system (DS), together with a end-to-end user simulator (US), has not ever been explored. Moreover, a drawback with existing GPT-2 based TOD systems is that they mostly employ the whole dialog history as input, which brings inefficiencies in memory and compute. In this paper, we first propose Simplified Generative Architectures (SGA) for DS and US respectively, both based on GPT-2 but using shortened history. Then, we successfully develop Jointly Reinforced US and DS, called SGA-JRUD. Our DS with the proposed SGA, when only supervised trained, achieves state-of-the-art performance on MultiWOZ2.1 and is more compute-efficient in both training and generation. Extensive experiments on MultiWOZ2.1 further show the superiority of SGA-JRUD in both offline and online evaluations.
Information Extraction and Human-Robot Dialogue towards Real-life Tasks: A Baseline Study with the MobileCS Dataset
Sep 27, 2022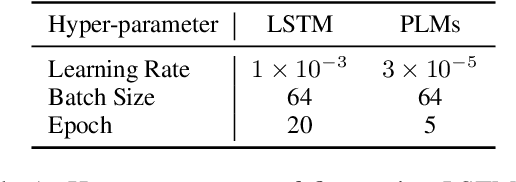
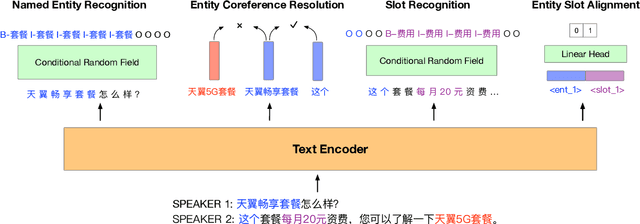
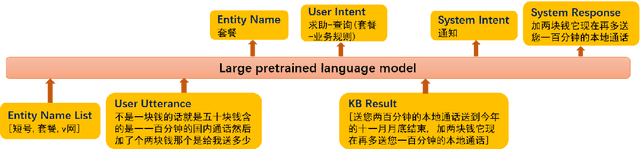

Recently, there have merged a class of task-oriented dialogue (TOD) datasets collected through Wizard-of-Oz simulated games. However, the Wizard-of-Oz data are in fact simulated data and thus are fundamentally different from real-life conversations, which are more noisy and casual. Recently, the SereTOD challenge is organized and releases the MobileCS dataset, which consists of real-world dialog transcripts between real users and customer-service staffs from China Mobile. Based on the MobileCS dataset, the SereTOD challenge has two tasks, not only evaluating the construction of the dialogue system itself, but also examining information extraction from dialog transcripts, which is crucial for building the knowledge base for TOD. This paper mainly presents a baseline study of the two tasks with the MobileCS dataset. We introduce how the two baselines are constructed, the problems encountered, and the results. We anticipate that the baselines can facilitate exciting future research to build human-robot dialogue systems for real-life tasks.
Advancing Semi-Supervised Task Oriented Dialog Systems by JSA Learning of Discrete Latent Variable Models
Jul 25, 2022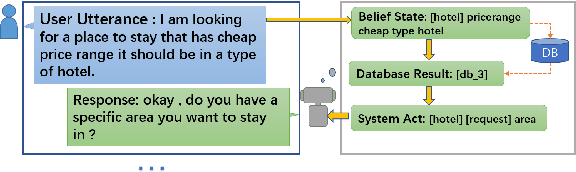
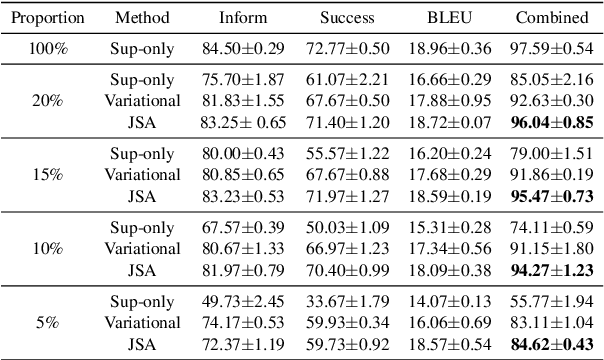
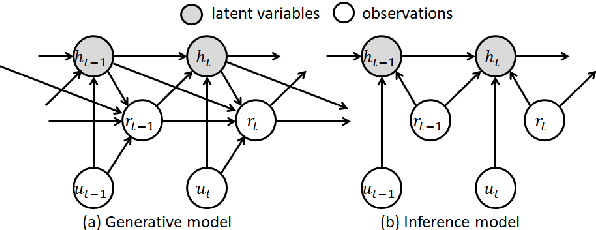
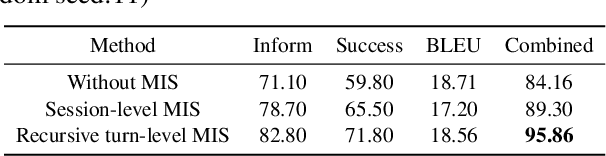
Developing semi-supervised task-oriented dialog (TOD) systems by leveraging unlabeled dialog data has attracted increasing interests. For semi-supervised learning of latent state TOD models, variational learning is often used, but suffers from the annoying high-variance of the gradients propagated through discrete latent variables and the drawback of indirectly optimizing the target log-likelihood. Recently, an alternative algorithm, called joint stochastic approximation (JSA), has emerged for learning discrete latent variable models with impressive performances. In this paper, we propose to apply JSA to semi-supervised learning of the latent state TOD models, which is referred to as JSA-TOD. To our knowledge, JSA-TOD represents the first work in developing JSA based semi-supervised learning of discrete latent variable conditional models for such long sequential generation problems like in TOD systems. Extensive experiments show that JSA-TOD significantly outperforms its variational learning counterpart. Remarkably, semi-supervised JSA-TOD using 20% labels performs close to the full-supervised baseline on MultiWOZ2.1.
A Challenge on Semi-Supervised and Reinforced Task-Oriented Dialog Systems
Jul 06, 2022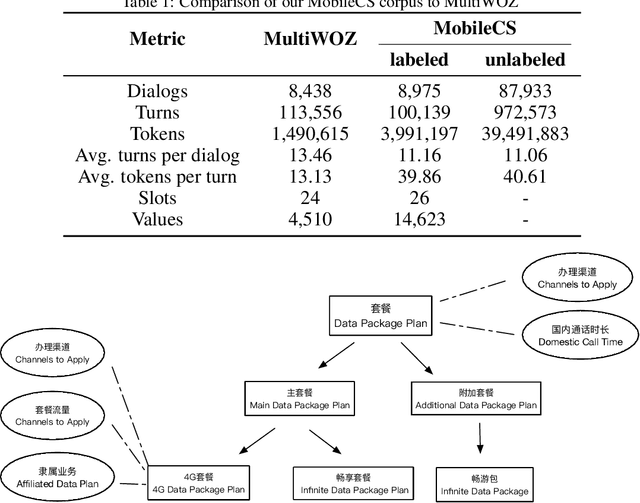

A challenge on Semi-Supervised and Reinforced Task-Oriented Dialog Systems, Co-located with EMNLP2022 SereTOD Workshop.
Revisiting Markovian Generative Architectures for Efficient Task-Oriented Dialog Systems
Apr 13, 2022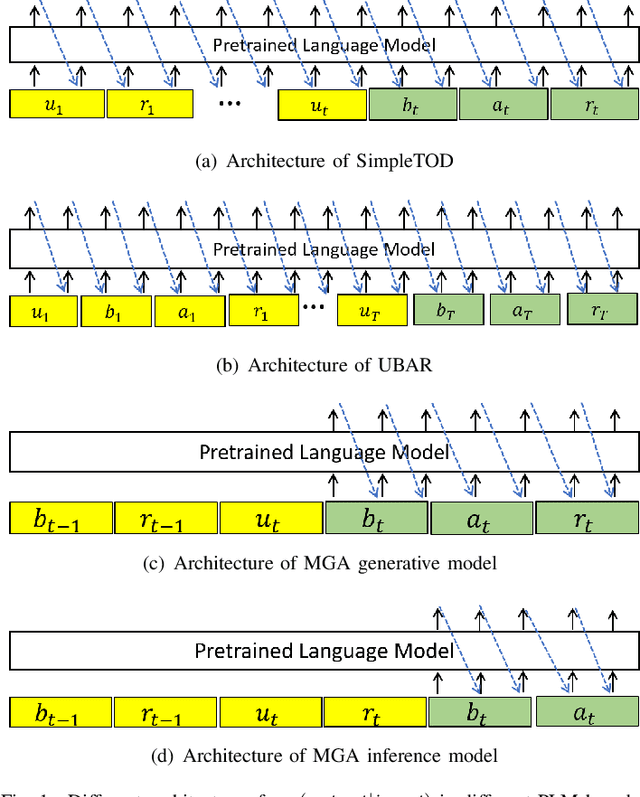
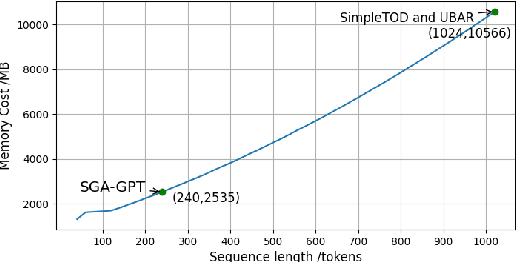
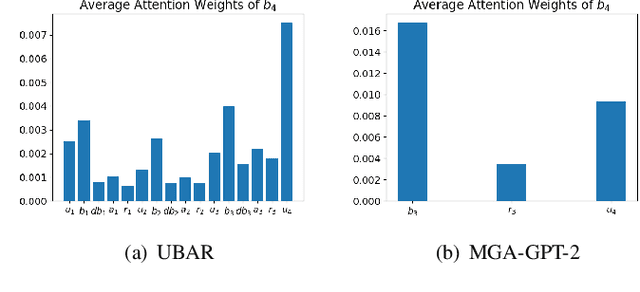
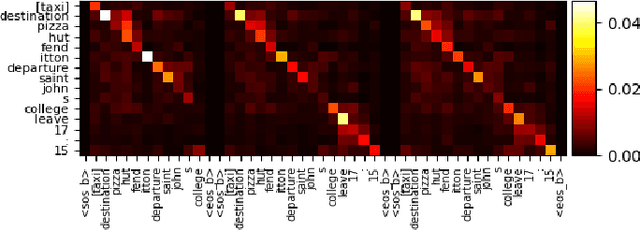
Recently, Transformer based pretrained language models (PLMs), such as GPT2 and T5, have been leveraged to build generative task-oriented dialog (TOD) systems. A drawback of existing PLM-based models is their non-Markovian architectures across turns, i.e., the whole history is used as the conditioning input at each turn, which brings inefficiencies in memory, computation and learning. In this paper, we propose to revisit Markovian Generative Architectures (MGA), which have been used in previous LSTM-based TOD systems, but not studied for PLM-based systems. Experiments on MultiWOZ2.1 show the efficiency advantages of the proposed Markovian PLM-based systems over their non-Markovian counterparts, in both supervised and semi-supervised settings.
An Empirical Study of Language Model Integration for Transducer based Speech Recognition
Mar 31, 2022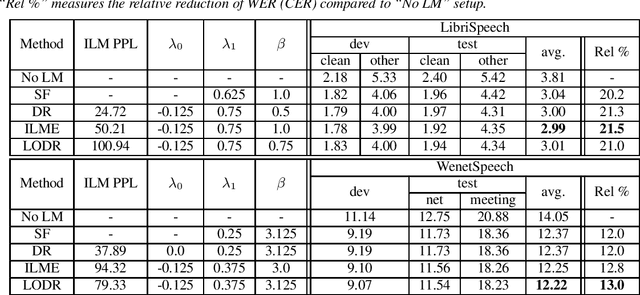
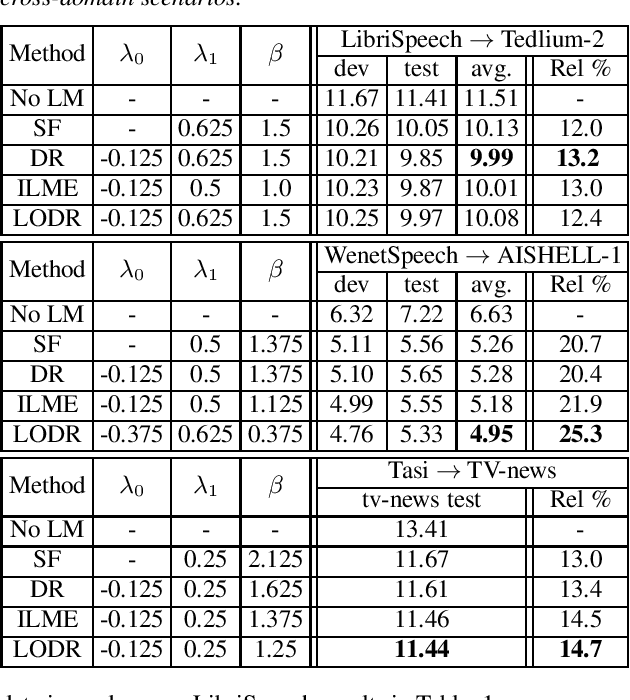
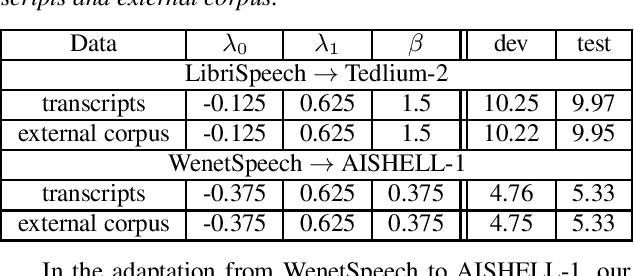
Utilizing text-only data with an external language model (LM) in end-to-end RNN-Transducer (RNN-T) for speech recognition is challenging. Recently, a class of methods such as density ratio (DR) and ILM estimation (ILME) have been developed, outperforming the classic shallow fusion (SF) method. The basic idea behind these methods is that RNN-T posterior should first subtract the implicitly learned ILM prior, in order to integrate the external LM. While recent studies suggest that RNN-T only learns some low-order language model information, the DR method uses a well-trained ILM. We hypothesize that this setting is appropriate and may deteriorate the performance of the DR method, and propose a low-order density ratio method (LODR) by training a low-order weak ILM for DR. Extensive empirical experiments are conducted on both in-domain and cross-domain scenarios on English LibriSpeech & Tedlium-2 and Chinese WenetSpeech & AISHELL-1 datasets. It is shown that LODR consistently outperforms SF in all tasks, while performing generally close to ILME and better than DR in most tests.
CUSIDE: Chunking, Simulating Future Context and Decoding for Streaming ASR
Mar 31, 2022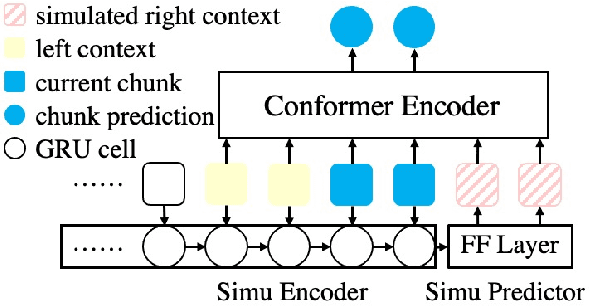
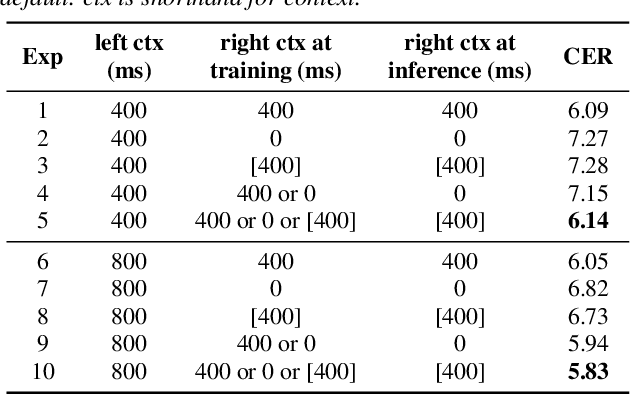
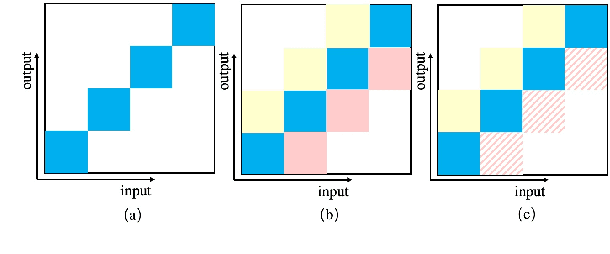

History and future contextual information are known to be important for accurate acoustic modeling. However, acquiring future context brings latency for streaming ASR. In this paper, we propose a new framework - Chunking, Simulating Future Context and Decoding (CUSIDE) for streaming speech recognition. A new simulation module is introduced to recursively simulate the future contextual frames, without waiting for future context. The simulation module is jointly trained with the ASR model using a self-supervised loss; the ASR model is optimized with the usual ASR loss, e.g., CTC-CRF as used in our experiments. Experiments show that, compared to using real future frames as right context, using simulated future context can drastically reduce latency while maintaining recognition accuracy. With CUSIDE, we obtain new state-of-the-art streaming ASR results on the AISHELL-1 dataset.
Exploiting Single-Channel Speech for Multi-Channel End-to-End Speech Recognition: A Comparative Study
Mar 31, 2022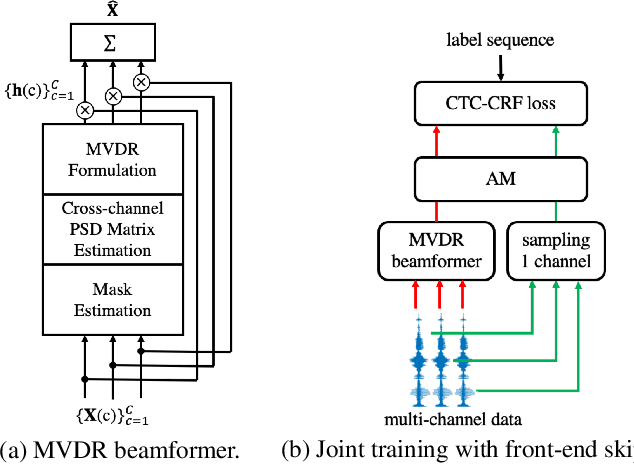

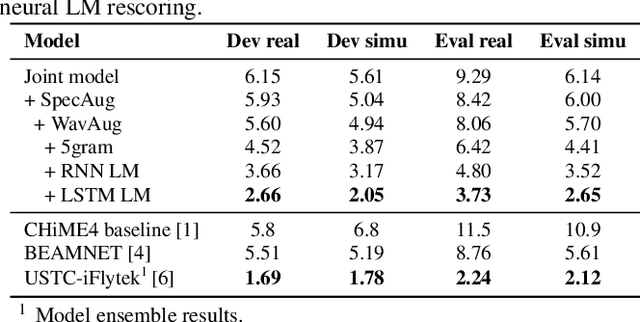
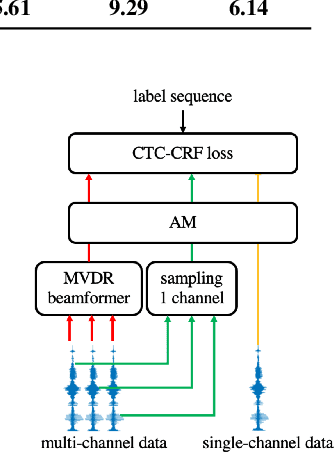
Recently, the end-to-end training approach for multi-channel ASR has shown its effectiveness, which usually consists of a beamforming front-end and a recognition back-end. However, the end-to-end training becomes more difficult due to the integration of multiple modules, particularly considering that multi-channel speech data recorded in real environments are limited in size. This raises the demand to exploit the single-channel data for multi-channel end-to-end ASR. In this paper, we systematically compare the performance of three schemes to exploit external single-channel data for multi-channel end-to-end ASR, namely back-end pre-training, data scheduling, and data simulation, under different settings such as the sizes of the single-channel data and the choices of the front-end. Extensive experiments on CHiME-4 and AISHELL-4 datasets demonstrate that while all three methods improve the multi-channel end-to-end speech recognition performance, data simulation outperforms the other two, at the cost of longer training time. Data scheduling outperforms back-end pre-training marginally but nearly consistently, presumably because that in the pre-training stage, the back-end tends to overfit on the single-channel data, especially when the single-channel data size is small.
iCallee: Recovering Call Graphs for Binaries
Nov 03, 2021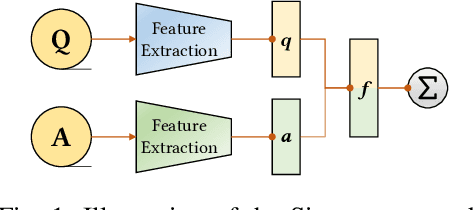
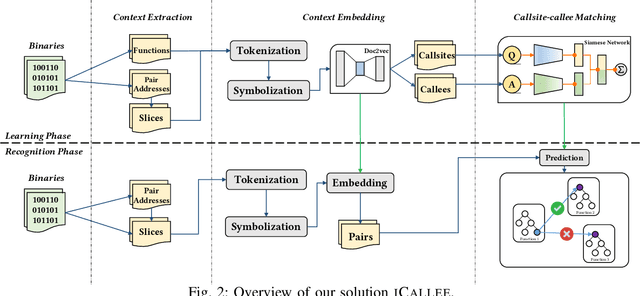
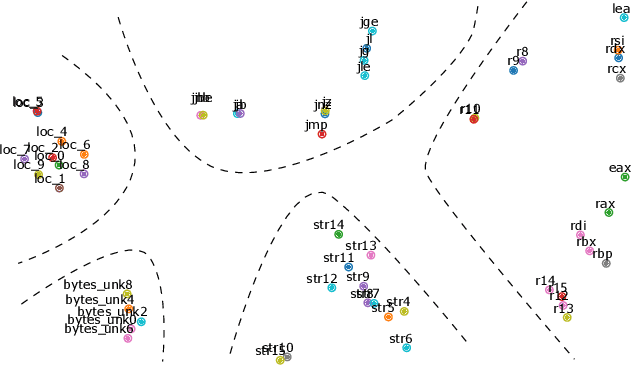
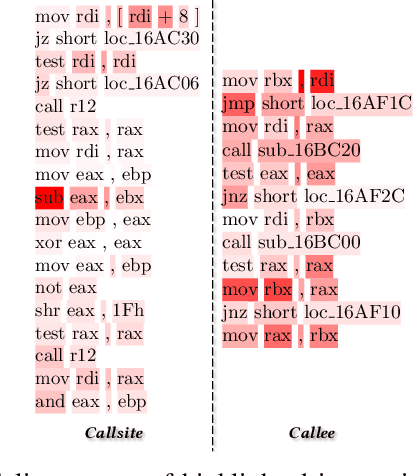
Recovering programs' call graphs is crucial for inter-procedural analysis tasks and applications based on them. The core challenge is recognizing targets of indirect calls (i.e., indirect callees). It becomes more challenging if target programs are in binary forms, due to information loss in binaries. Existing indirect callee recognition solutions for binaries all have high false positives and negatives, making call graphs inaccurate. In this paper, we propose a new solution iCallee based on the Siamese Neural Network, inspired by the advances in question-answering applications. The key insight is that, neural networks can learn to answer whether a callee function is a potential target of an indirect callsite by comprehending their contexts, i.e., instructions nearby callsites and of callees. Following this insight, we first preprocess target binaries to extract contexts of callsites and callees. Then, we build a customized Natural Language Processing (NLP) model applicable to assembly language. Further, we collect abundant pairs of callsites and callees, and embed their contexts with the NLP model, then train a Siamese network and a classifier to answer the callsite-callee question. We have implemented a prototype of iCallee and evaluated it on several groups of targets. Evaluation results showed that, our solution could match callsites to callees with an F1-Measure of 93.7%, recall of 93.8%, and precision of 93.5%, much better than state-of-the-art solutions. To show its usefulness, we apply iCallee to two specific applications - binary code similarity detection and binary program hardening, and found that it could greatly improve state-of-the-art solutions.