 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDongYuan: An LLM-Based Framework for Integrative Chinese and Western Medicine Spleen-Stomach Disorders Diagnosis
Mar 30, 2026The clinical burden of spleen-stomach disorders is substantial. While large language models (LLMs) offer new potential for medical applications, they face three major challenges in the context of integrative Chinese and Western medicine (ICWM): a lack of high-quality data, the absence of models capable of effectively integrating the reasoning logic of traditional Chinese medicine (TCM) syndrome differentiation with that of Western medical (WM) disease diagnosis, and the shortage of a standardized evaluation benchmark. To address these interrelated challenges, we propose DongYuan, an ICWM spleen-stomach diagnostic framework. Specifically, three ICWM datasets (SSDF-Syndrome, SSDF-Dialogue, and SSDF-PD) were curated to fill the gap in high-quality data for spleen-stomach disorders. We then developed SSDF-Core, a core diagnostic LLM that acquires robust ICWM reasoning capabilities through a two-stage training regimen of supervised fine-tuning. tuning (SFT) and direct preference optimization (DPO), and complemented it with SSDF-Navigator, a pluggable consultation navigation model designed to optimize clinical inquiry strategies. Additionally, we established SSDF-Bench, a comprehensive evaluation benchmark focused on ICWM diagnosis of spleen-stomach disorders. Experimental results demonstrate that SSDF-Core significantly outperforms 12 mainstream baselines on SSDF-Bench. DongYuan lays a solid methodological foundation and provides practical technical references for the future development of intelligent ICWM diagnostic systems.
Flexible Attributed Network Embedding
Nov 27, 2018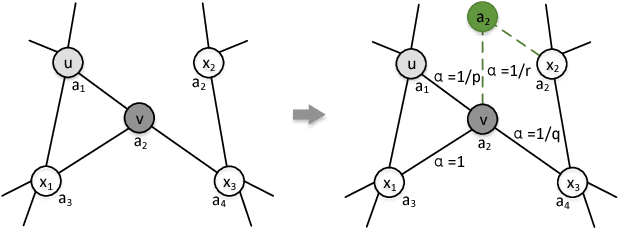
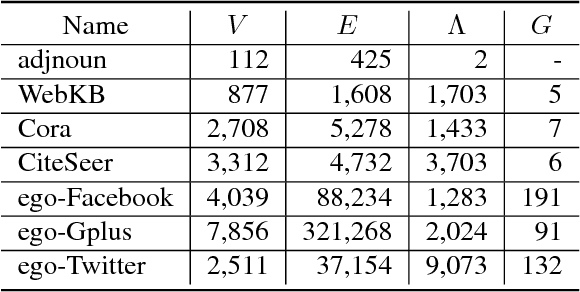
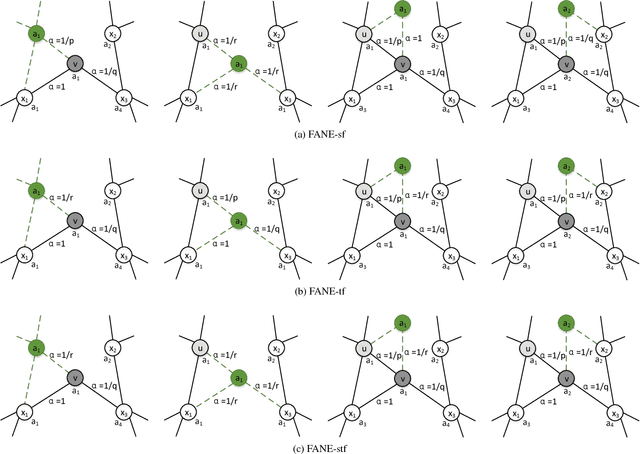
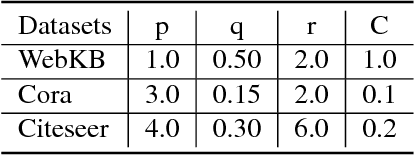
Network embedding aims to find a way to encode network by learning an embedding vector for each node in the network. The network often has property information which is highly informative with respect to the node's position and role in the network. Most network embedding methods fail to utilize this information during network representation learning. In this paper, we propose a novel framework, FANE, to integrate structure and property information in the network embedding process. In FANE, we design a network to unify heterogeneity of the two information sources, and define a new random walking strategy to leverage property information and make the two information compensate. FANE is conceptually simple and empirically powerful. It improves over the state-of-the-art methods on Cora dataset classification task by over 5%, more than 10% on WebKB dataset classification task. Experiments also show that the results improve more than the state-of-the-art methods as increasing training size. Moreover, qualitative visualization show that our framework is helpful in network property information exploration. In all, we present a new way for efficiently learning state-of-the-art task-independent representations in complex attributed networks. The source code and datasets of this paper can be obtained from https://github.com/GraphWorld/FANE.