 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Batch Normalization in Transformers
Mar 17, 2020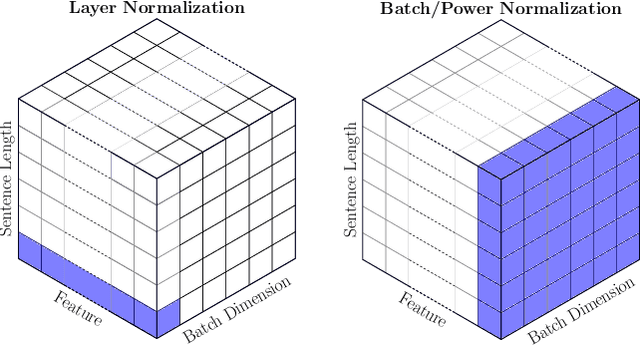
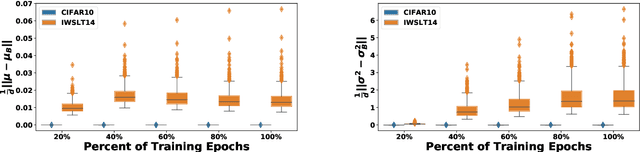
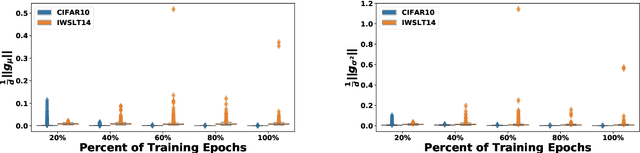
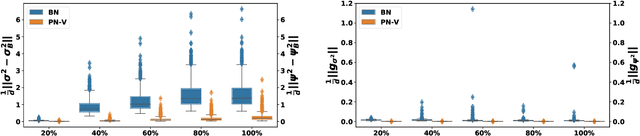
The standard normalization method for neural network (NN) models used in Natural Language Processing (NLP) is layer normalization (LN). This is different than batch normalization (BN), which is widely-adopted in Computer Vision. The preferred use of LN in NLP is principally due to the empirical observation that a (naive/vanilla) use of BN leads to significant performance degradation for NLP tasks; however, a thorough understanding of the underlying reasons for this is not always evident. In this paper, we perform a systematic study of NLP transformer models to understand why BN has a poor performance, as compared to LN. We find that the statistics of NLP data across the batch dimension exhibit large fluctuations throughout training. This results in instability, if BN is naively implemented. To address this, we propose Power Normalization (PN), a novel normalization scheme that resolves this issue by (i) relaxing zero-mean normalization in BN, (ii) incorporating a running quadratic mean instead of per batch statistics to stabilize fluctuations, and (iii) using an approximate backpropagation for incorporating the running statistics in the forward pass. We show theoretically, under mild assumptions, that PN leads to a smaller Lipschitz constant for the loss, compared with BN. Furthermore, we prove that the approximate backpropagation scheme leads to bounded gradients. We extensively test PN for transformers on a range of NLP tasks, and we show that it significantly outperforms both LN and BN. In particular, PN outperforms LN by 0.4/0.6 BLEU on IWSLT14/WMT14 and 5.6/3.0 PPL on PTB/WikiText-103.
PyHessian: Neural Networks Through the Lens of the Hessian
Jan 02, 2020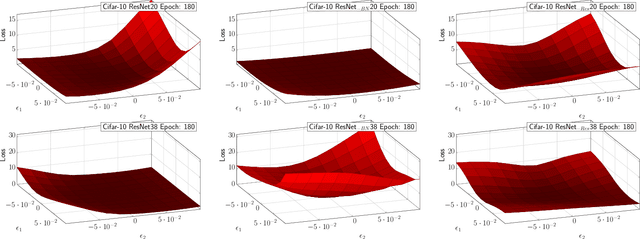
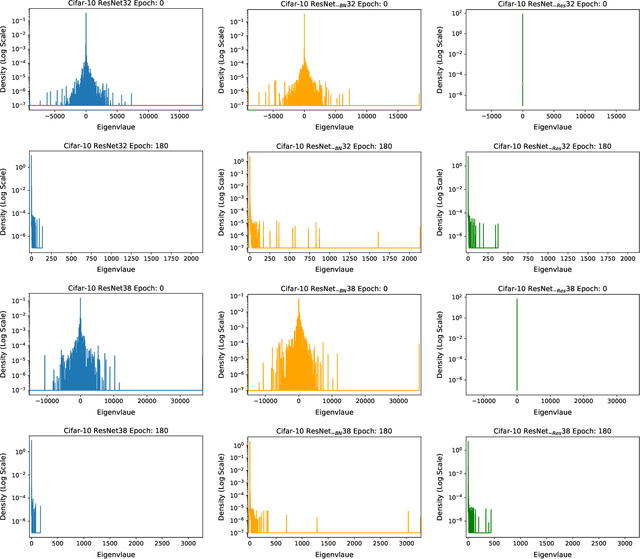
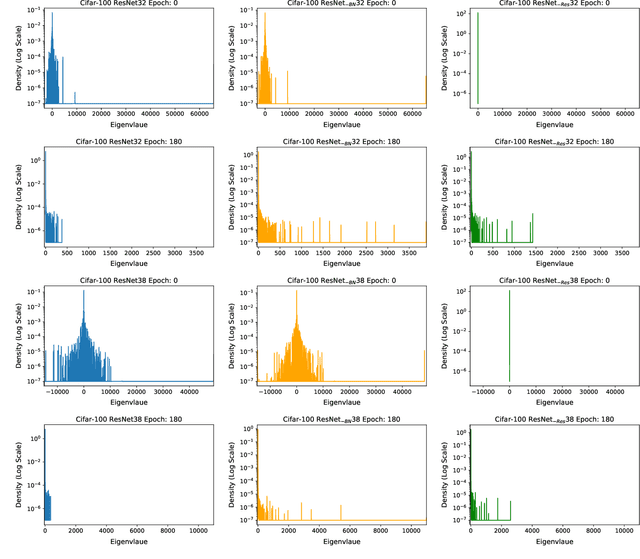
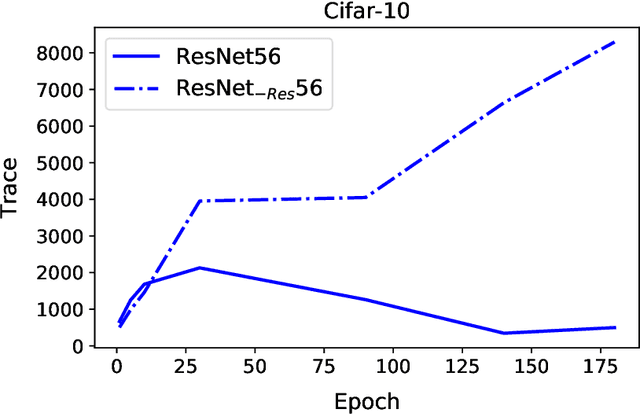
We present PyHessian, a new scalable framework that enables fast computation of Hessian (i.e., second-order derivative) information for deep neural networks. This framework is developed in Pytorch, and it enables distributed-memory execution on both cloud and supercomputer systems. PyHessian enables fast computations of the top Hessian eigenvalues, the Hessian trace, and the full Hessian eigenvalue/spectral density. This general framework can be used to analyze neural network models, including the topology of the loss landscape (i.e., curvature information) to gain insight into the behavior of different models/optimizers. To illustrate this, we apply PyHessian to analyze the effect of residual connections and Batch Normalization layers on the smoothness of the loss landscape during training. One recent claim, based on simpler first-order analysis, is that residual connections and Batch Normalization make the loss landscape ``smoother,'' thus making it easier for Stochastic Gradient Descent to converge to a good solution. We perform an extensive analysis of this hypothesis, on four residual networks (ResNet20/32/38/56) on the Cifar-10/100 dataset, by measuring directly the Hessian spectrum using PyHessian. This analysis leads to finer-scale insight, demonstrating that while conventional wisdom is sometimes validated, in other cases it is simply incorrect. In particular, we find that Batch Normalization layers do not necessarily make the loss landscape smoother, especially for shallow networks. Instead, the claimed smoother loss landscape only becomes evident for deeper neural networks, at least within this ResNet series. We have open-sourced the PyHessian framework for Hessian spectrum computation.
ZeroQ: A Novel Zero Shot Quantization Framework
Jan 01, 2020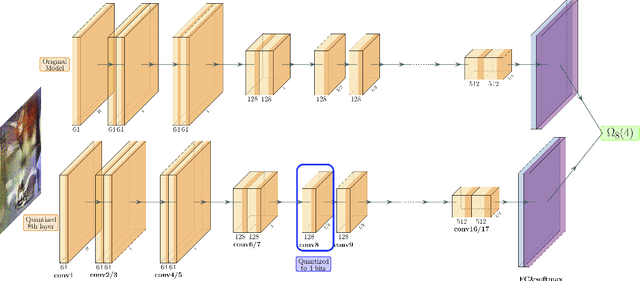

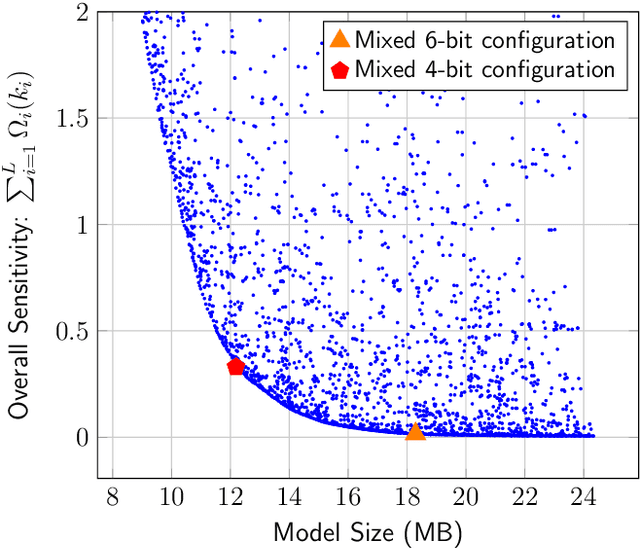
Quantization is a promising approach for reducing the inference time and memory footprint of neural networks. However, most existing quantization methods require access to the original training dataset for retraining during quantization. This is often not possible for applications with sensitive or proprietary data, e.g., due to privacy and security concerns. Existing zero-shot quantization methods use different heuristics to address this, but they result in poor performance, especially when quantizing to ultra-low precision. Here, we propose ZeroQ , a novel zero-shot quantization framework to address this. ZeroQ enables mixed-precision quantization without any access to the training or validation data. This is achieved by optimizing for a Distilled Dataset, which is engineered to match the statistics of batch normalization across different layers of the network. ZeroQ supports both uniform and mixed-precision quantization. For the latter, we introduce a novel Pareto frontier based method to automatically determine the mixed-precision bit setting for all layers, with no manual search involved. We extensively test our proposed method on a diverse set of models, including ResNet18/50/152, MobileNetV2, ShuffleNet, SqueezeNext, and InceptionV3 on ImageNet, as well as RetinaNet-ResNet50 on the Microsoft COCO dataset. In particular, we show that ZeroQ can achieve 1.71\% higher accuracy on MobileNetV2, as compared to the recently proposed DFQ method. Importantly, ZeroQ has a very low computational overhead, and it can finish the entire quantization process in less than 30s (0.5\% of one epoch training time of ResNet50 on ImageNet). We have open-sourced the ZeroQ framework\footnote{https://github.com/amirgholami/ZeroQ}.
HAWQ-V2: Hessian Aware trace-Weighted Quantization of Neural Networks
Nov 10, 2019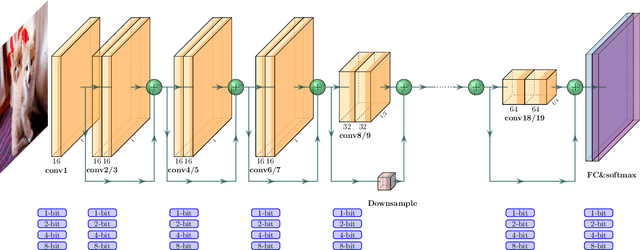
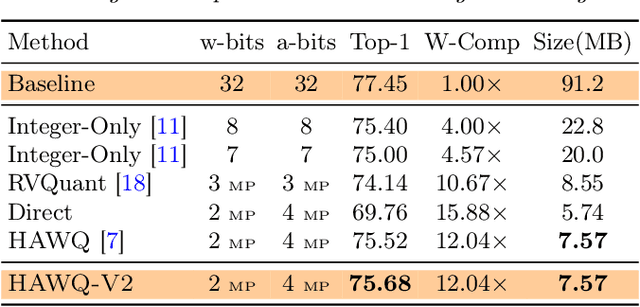
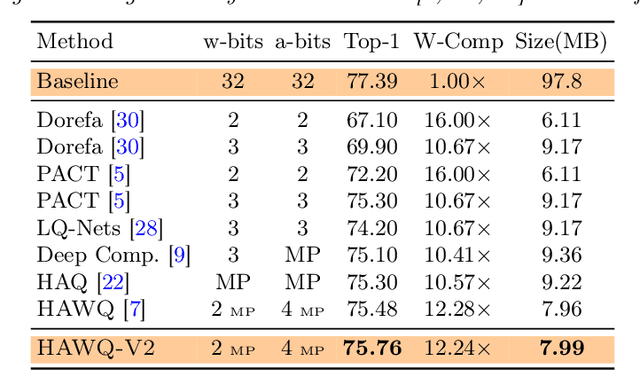
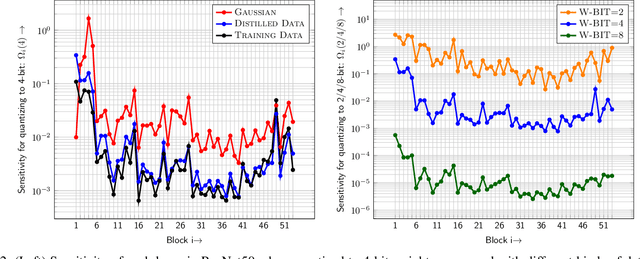
Quantization is an effective method for reducing memory footprint and inference time of Neural Networks, e.g., for efficient inference in the cloud, especially at the edge. However, ultra low precision quantization could lead to significant degradation in model generalization. A promising method to address this is to perform mixed-precision quantization, where more sensitive layers are kept at higher precision. However, the search space for a mixed-precision quantization is exponential in the number of layers. Recent work has proposed HAWQ, a novel Hessian based framework, with the aim of reducing this exponential search space by using second-order information. While promising, this prior work has three major limitations: (i) HAWQV1 only uses the top Hessian eigenvalue as a measure of sensitivity and do not consider the rest of the Hessian spectrum; (ii) HAWQV1 approach only provides relative sensitivity of different layers and therefore requires a manual selection of the mixed-precision setting; and (iii) HAWQV1 does not consider mixed-precision activation quantization. Here, we present HAWQV2 which addresses these shortcomings. For (i), we perform a theoretical analysis showing that a better sensitivity metric is to compute the average of all of the Hessian eigenvalues. For (ii), we develop a Pareto frontier based method for selecting the exact bit precision of different layers without any manual selection. For (iii), we extend the Hessian analysis to mixed-precision activation quantization. We have found this to be very beneficial for object detection. We show that HAWQV2 achieves new state-of-the-art results for a wide range of tasks.
Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
Sep 25, 2019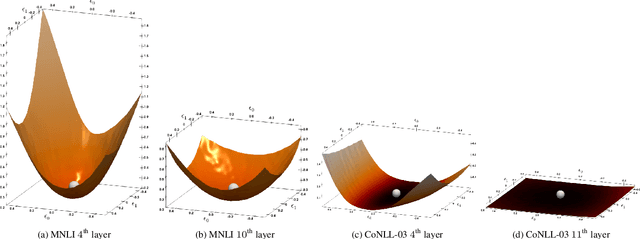
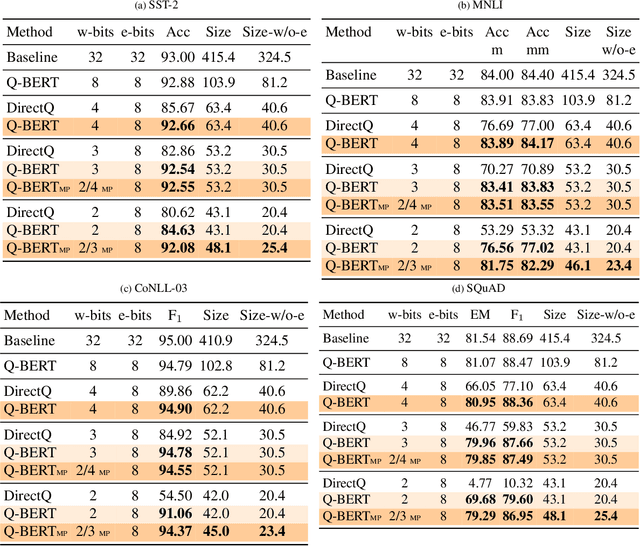
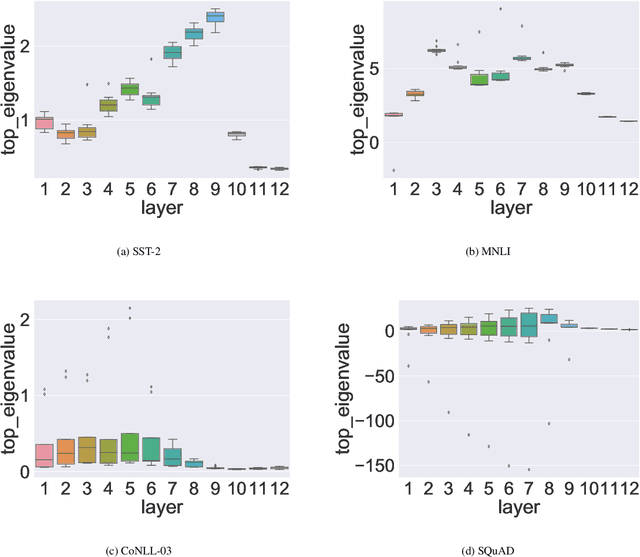
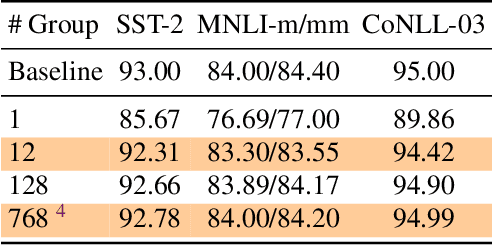
Transformer based architectures have become de-facto models used for a range of Natural Language Processing tasks. In particular, the BERT based models achieved significant accuracy gain for GLUE tasks, CoNLL-03 and SQuAD. However, BERT based models have a prohibitive memory footprint and latency. As a result, deploying BERT based models in resource constrained environments has become a challenging task. In this work, we perform an extensive analysis of fine-tuned BERT models using second order Hessian information, and we use our results to propose a novel method for quantizing BERT models to ultra low precision. In particular, we propose a new group-wise quantization scheme, and we use a Hessian based mix-precision method to compress the model further. We extensively test our proposed method on BERT downstream tasks of SST-2, MNLI, CoNLL-03, and SQuAD. We can achieve comparable performance to baseline with at most $2.3\%$ performance degradation, even with ultra-low precision quantization down to 2 bits, corresponding up to $13\times$ compression of the model parameters, and up to $4\times$ compression of the embedding table as well as activations. Among all tasks, we observed the highest performance loss for BERT fine-tuned on SQuAD. By probing into the Hessian based analysis as well as visualization, we show that this is related to the fact that current training/fine-tuning strategy of BERT does not converge for SQuAD.
ANODEV2: A Coupled Neural ODE Evolution Framework
Jun 10, 2019

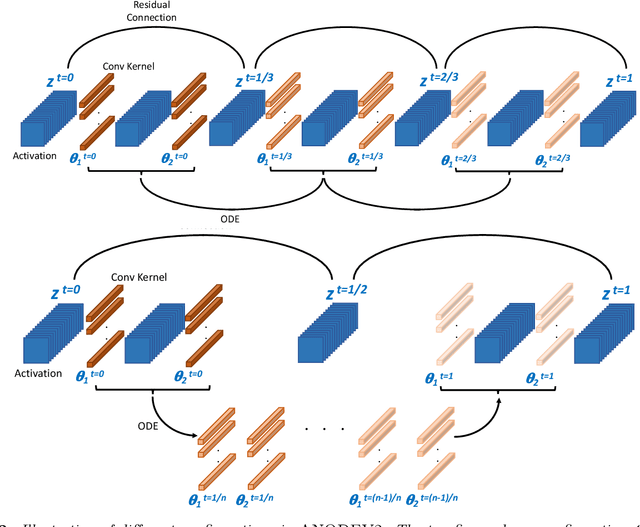

It has been observed that residual networks can be viewed as the explicit Euler discretization of an Ordinary Differential Equation (ODE). This observation motivated the introduction of so-called Neural ODEs, which allow more general discretization schemes with adaptive time stepping. Here, we propose ANODEV2, which is an extension of this approach that also allows evolution of the neural network parameters, in a coupled ODE-based formulation. The Neural ODE method introduced earlier is in fact a special case of this new more general framework. We present the formulation of ANODEV2, derive optimality conditions, and implement a coupled reaction-diffusion-advection version of this framework in PyTorch. We present empirical results using several different configurations of ANODEV2, testing them on multiple models on CIFAR-10. We report results showing that this coupled ODE-based framework is indeed trainable, and that it achieves higher accuracy, as compared to the baseline models as well as the recently-proposed Neural ODE approach.
Residual Networks as Nonlinear Systems: Stability Analysis using Linearization
May 31, 2019
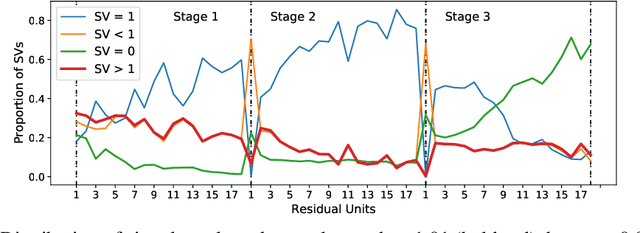
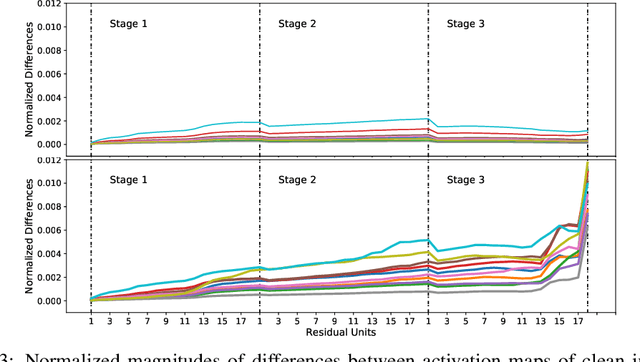
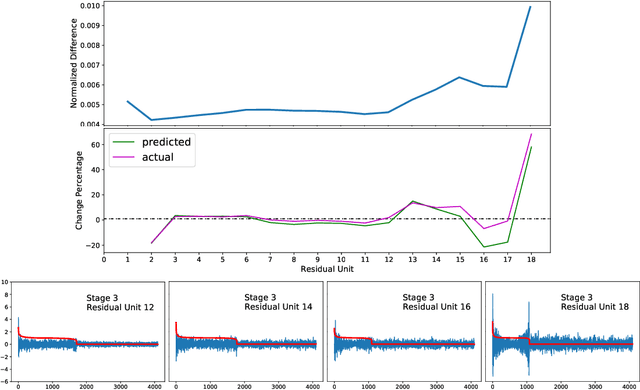
We regard pre-trained residual networks (ResNets) as nonlinear systems and use linearization, a common method used in the qualitative analysis of nonlinear systems, to understand the behavior of the networks under small perturbations of the input images. We work with ResNet-56 and ResNet-110 trained on the CIFAR-10 data set. We linearize these networks at the level of residual units and network stages, and the singular value decomposition is used in the stability analysis of these components. It is found that most of the singular values of the linearizations of residual units are 1 and, in spite of the fact that the linearizations depend directly on the activation maps, the singular values differ only slightly for different input images. However, adjusting the scaling of the skip connection or the values of the weights in a residual unit has a significant impact on the singular value distributions. Inspection of how random and adversarial perturbations of input images propagate through the network reveals that there is a dramatic jump in the magnitude of adversarial perturbations towards the end of the final stage of the network that is not present in the case of random perturbations. We attempt to gain a better understanding of this phenomenon by projecting the perturbations onto singular vectors of the linearizations of the residual units.
HAWQ: Hessian AWare Quantization of Neural Networks with Mixed-Precision
Apr 29, 2019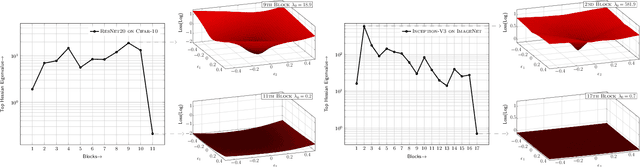
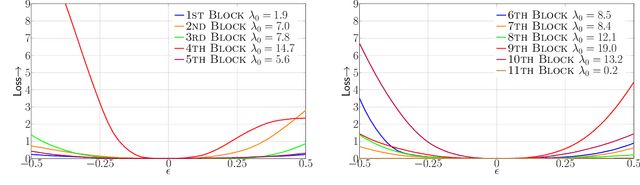
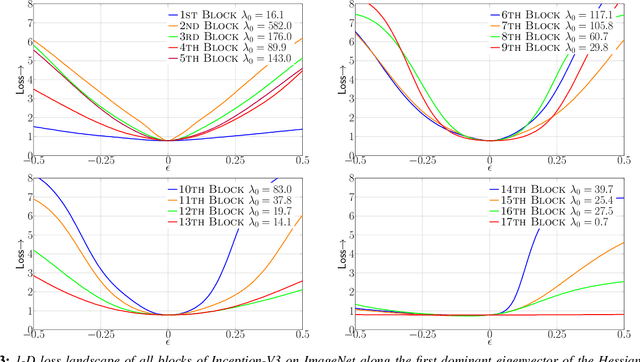
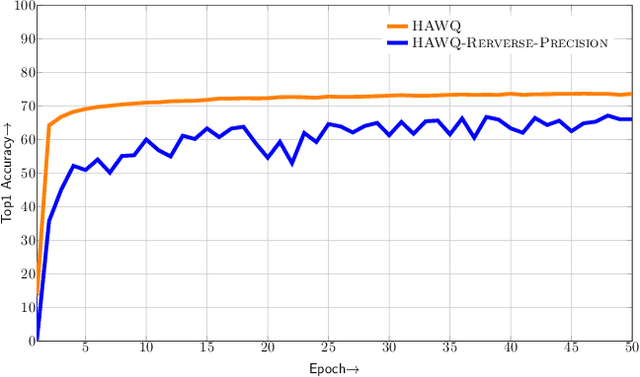
Model size and inference speed/power have become a major challenge in the deployment of Neural Networks for many applications. A promising approach to address these problems is quantization. However, uniformly quantizing a model to ultra low precision leads to significant accuracy degradation. A novel solution for this is to use mixed-precision quantization, as some parts of the network may allow lower precision as compared to other layers. However, there is no systematic way to determine the precision of different layers. A brute force approach is not feasible for deep networks, as the search space for mixed-precision is exponential in the number of layers. Another challenge is a similar factorial complexity for determining block-wise fine-tuning order when quantizing the model to a target precision. Here, we introduce Hessian AWare Quantization (HAWQ), a novel second-order quantization method to address these problems. HAWQ allows for the automatic selection of the relative quantization precision of each layer, based on the layer's Hessian spectrum. Moreover, HAWQ provides a deterministic fine-tuning order for quantizing layers, based on second-order information. We show the results of our method on Cifar-10 using ResNet20, and on ImageNet using Inception-V3, ResNet50 and SqueezeNext models. Comparing HAWQ with state-of-the-art shows that we can achieve similar/better accuracy with $8\times$ activation compression ratio on ResNet20, as compared to DNAS~\cite{wu2018mixed}, and up to $1\%$ higher accuracy with up to $14\%$ smaller models on ResNet50 and Inception-V3, compared to recently proposed methods of RVQuant~\cite{park2018value} and HAQ~\cite{wang2018haq}. Furthermore, we show that we can quantize SqueezeNext to just 1MB model size while achieving above $68\%$ top1 accuracy on ImageNet.
JumpReLU: A Retrofit Defense Strategy for Adversarial Attacks
Apr 07, 2019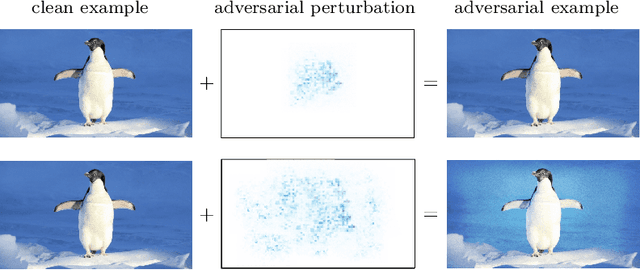
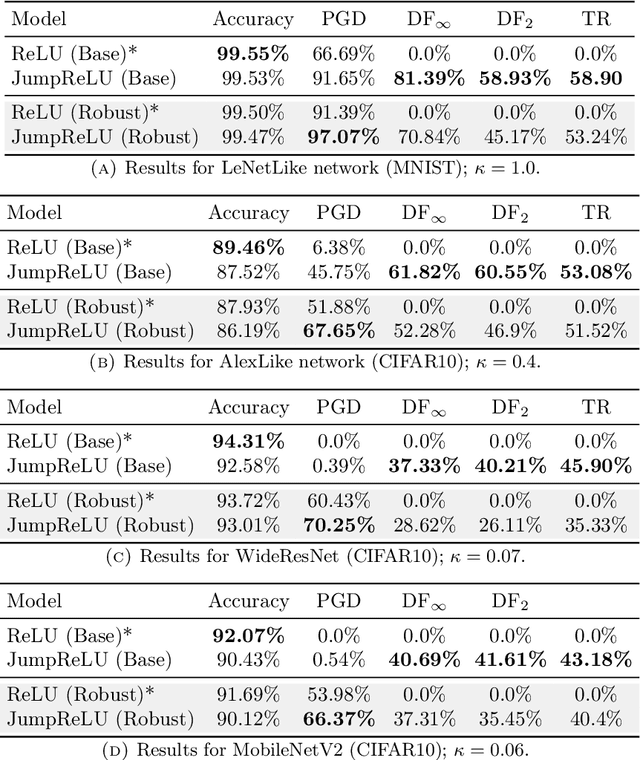
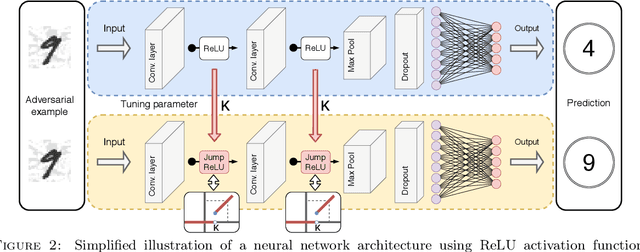
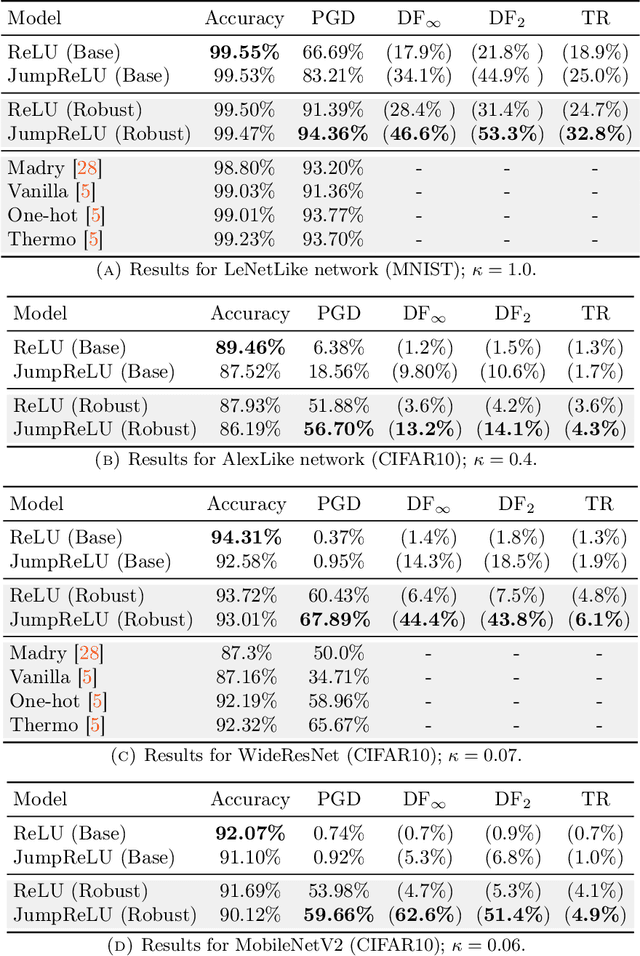
It has been demonstrated that very simple attacks can fool highly-sophisticated neural network architectures. In particular, so-called adversarial examples, constructed from perturbations of input data that are small or imperceptible to humans but lead to different predictions, may lead to an enormous risk in certain critical applications. In light of this, there has been a great deal of work on developing adversarial training strategies to improve model robustness. These training strategies are very expensive, in both human and computational time. To complement these approaches, we propose a very simple and inexpensive strategy which can be used to ``retrofit'' a previously-trained network to improve its resilience to adversarial attacks. More concretely, we propose a new activation function---the JumpReLU---which, when used in place of a ReLU in an already-trained model, leads to a trade-off between predictive accuracy and robustness. This trade-off is controlled by the jump size, a hyper-parameter which can be tuned during the validation stage. Our empirical results demonstrate that this increases model robustness, protecting against adversarial attacks with substantially increased levels of perturbations. This is accomplished simply by retrofitting existing networks with our JumpReLU activation function, without the need for retraining the model. Additionally, we demonstrate that adversarially trained (robust) models can greatly benefit from retrofitting.
Inefficiency of K-FAC for Large Batch Size Training
Mar 14, 2019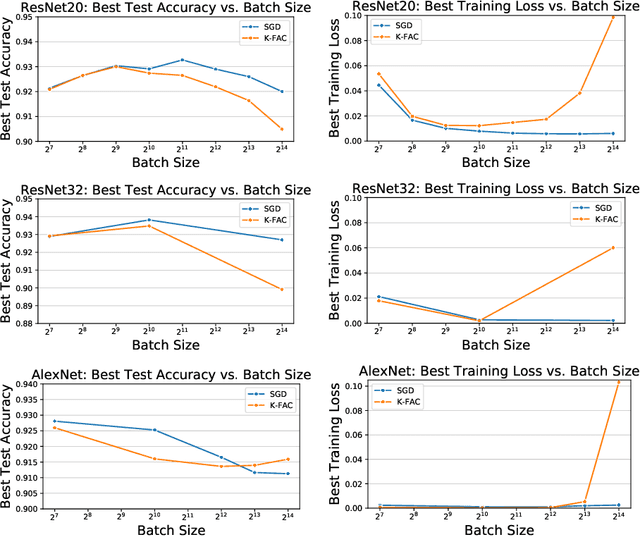
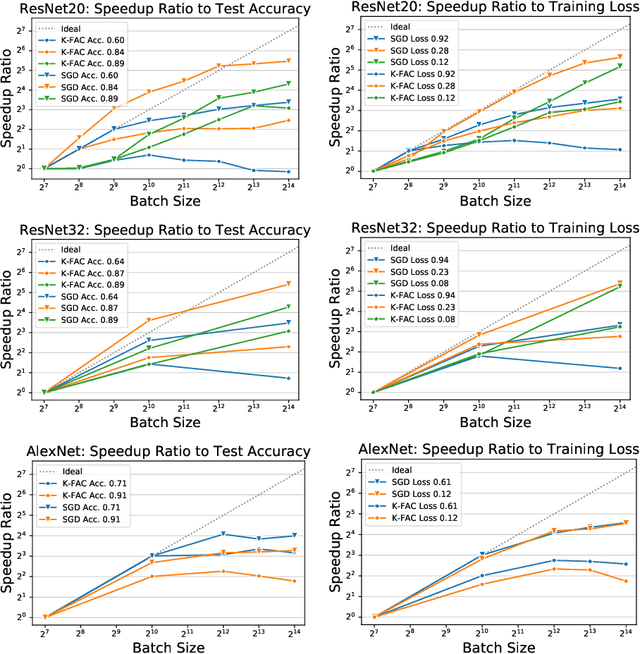
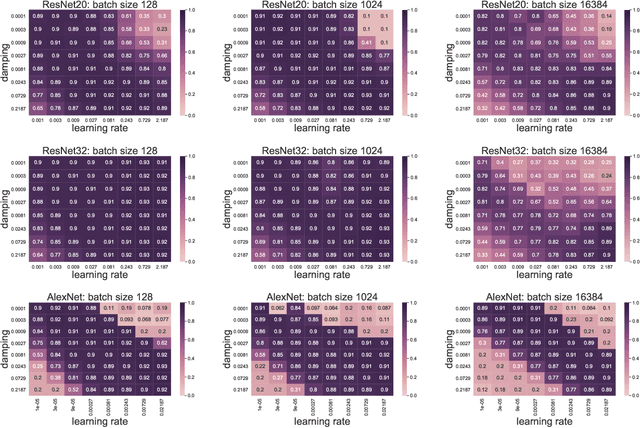
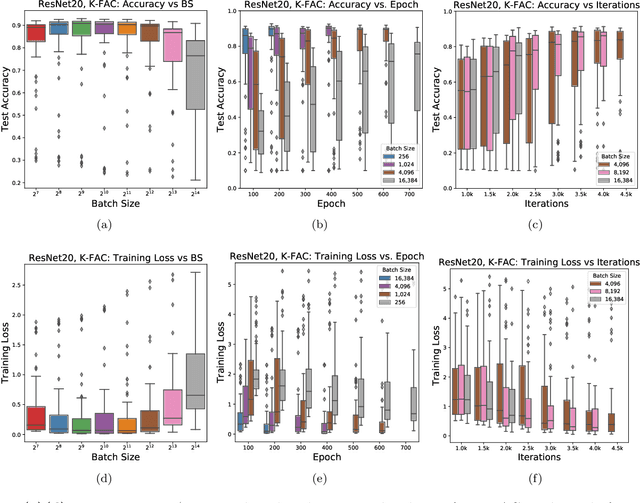
In stochastic optimization, large batch training can leverage parallel resources to produce faster wall-clock training times per epoch. However, for both training loss and testing error, recent results analyzing large batch Stochastic Gradient Descent (SGD) have found sharp diminishing returns beyond a certain critical batch size. In the hopes of addressing this, the Kronecker-Factored Approximate Curvature (\mbox{K-FAC}) method has been hypothesized to allow for greater scalability to large batch sizes for non-convex machine learning problems, as well as greater robustness to variation in hyperparameters. Here, we perform a detailed empirical analysis of these two hypotheses, evaluating performance in terms of both wall-clock time and aggregate computational cost. Our main results are twofold: first, we find that \mbox{K-FAC} does not exhibit improved large-batch scalability behavior, as compared to SGD; and second, we find that \mbox{K-FAC}, in addition to requiring more hyperparameters to tune, suffers from the same hyperparameter sensitivity patterns as SGD. We discuss extensive results using residual networks on \mbox{CIFAR-10}, as well as more general implications of our findings.