 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Soft Actor Critic for Risk Sensitive Learning
Apr 30, 2020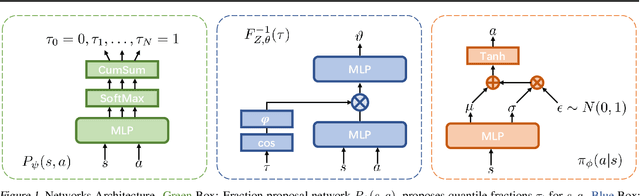
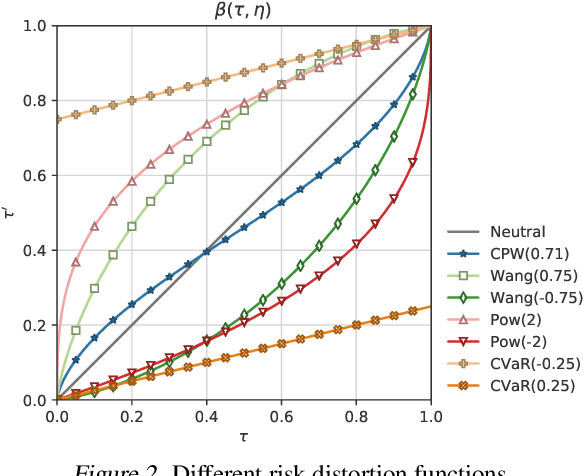

Most of reinforcement learning (RL) algorithms aim at maximizing the expectation of accumulated discounted returns. Since the accumulated discounted return is a random variable, its distribution includes more information than its expectation. Meanwhile, entropy of policy indicates its diversity and it can help improve the exploration capability of algorithms. In this paper, we present a new RL algorithm named Distributional Soft Actor Critic (DSAC), combining distributional RL and maximum entropy RL together. Taking the randomness both in action and discounted return into consideration, DSAC over performs the state-of-the-art baselines with more stability in several continuous control benchmarks. Moreover, distributional information of returns can also be used to measure metrics other than expectation, such as risk-related metrics. With a fully parameterized quantile function, DSAC is easily adopted to optimize policy under different risk preferences. Our experiments demonstrate that with distribution modeling in RL the agent performs better both for risk-averse and risk-seeking control tasks.
Sequential Batch Learning in Finite-Action Linear Contextual Bandits
Apr 14, 2020We study the sequential batch learning problem in linear contextual bandits with finite action sets, where the decision maker is constrained to split incoming individuals into (at most) a fixed number of batches and can only observe outcomes for the individuals within a batch at the batch's end. Compared to both standard online contextual bandits learning or offline policy learning in contexutal bandits, this sequential batch learning problem provides a finer-grained formulation of many personalized sequential decision making problems in practical applications, including medical treatment in clinical trials, product recommendation in e-commerce and adaptive experiment design in crowdsourcing. We study two settings of the problem: one where the contexts are arbitrarily generated and the other where the contexts are \textit{iid} drawn from some distribution. In each setting, we establish a regret lower bound and provide an algorithm, whose regret upper bound nearly matches the lower bound. As an important insight revealed therefrom, in the former setting, we show that the number of batches required to achieve the fully online performance is polynomial in the time horizon, while for the latter setting, a pure-exploitation algorithm with a judicious batch partition scheme achieves the fully online performance even when the number of batches is less than logarithmic in the time horizon. Together, our results provide a near-complete characterization of sequential decision making in linear contextual bandits when batch constraints are present.
Optimal No-regret Learning in Repeated First-price Auctions
Apr 14, 2020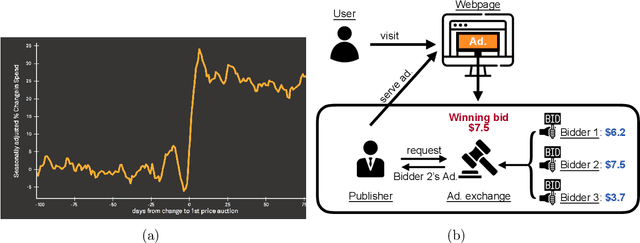
We study online learning in repeated first-price auctions with censored feedback, where a bidder, only observing the winning bid at the end of each auction, learns to adaptively bid in order to maximize her cumulative payoff. To achieve this goal, the bidder faces a challenging dilemma: if she wins the bid--the only way to achieve positive payoffs--then she is not able to observe the highest bid of the other bidders, which we assume is iid drawn from an unknown distribution. This dilemma, despite being reminiscent of the exploration-exploitation trade-off in contextual bandits, cannot directly be addressed by the existing UCB or Thompson sampling algorithms in that literature, mainly because contrary to the standard bandits setting, when a positive reward is obtained here, nothing about the environment can be learned. In this paper, by exploiting the structural properties of first-price auctions, we develop the first learning algorithm that achieves $O(\sqrt{T}\log^2 T)$ regret bound when the bidder's private values are stochastically generated. We do so by providing an algorithm on a general class of problems, which we call monotone group contextual bandits, where the same regret bound is established under stochastically generated contexts. Further, by a novel lower bound argument, we characterize an $\Omega(T^{2/3})$ lower bound for the case where the contexts are adversarially generated, thus highlighting the impact of the contexts generation mechanism on the fundamental learning limit. Despite this, we further exploit the structure of first-price auctions and develop a learning algorithm that operates sample-efficiently (and computationally efficiently) in the presence of adversarially generated private values. We establish an $O(\sqrt{T}\log^3 T)$ regret bound for this algorithm, hence providing a complete characterization of optimal learning guarantees for this problem.
Diagonal Preconditioning: Theory and Algorithms
Mar 25, 2020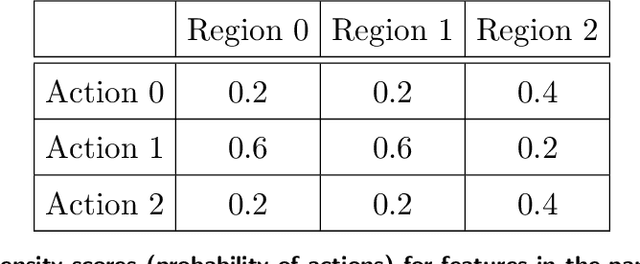
Diagonal preconditioning has been a staple technique in optimization and machine learning. It often reduces the condition number of the design or Hessian matrix it is applied to, thereby speeding up convergence. However, rigorous analyses of how well various diagonal preconditioning procedures improve the condition number of the preconditioned matrix and how that translates into improvements in optimization are rare. In this paper, we first provide an analysis of a popular diagonal preconditioning technique based on column standard deviation and its effect on the condition number using random matrix theory. Then we identify a class of design matrices whose condition numbers can be reduced significantly by this procedure. We then study the problem of optimal diagonal preconditioning to improve the condition number of any full-rank matrix and provide a bisection algorithm and a potential reduction algorithm with $O(\log(\frac{1}{\epsilon}))$ iteration complexity, where each iteration consists of an SDP feasibility problem and a Newton update using the Nesterov-Todd direction, respectively. Finally, we extend the optimal diagonal preconditioning algorithm to an adaptive setting and compare its empirical performance at reducing the condition number and speeding up convergence for regression and classification problems with that of another adaptive preconditioning technique, namely batch normalization, that is essential in training machine learning models.
Finite-Time Last-Iterate Convergence for Multi-Agent Learning in Games
Mar 18, 2020We consider multi-agent learning via online gradient descent (OGD) in a class of games called $\lambda$-cocoercive games, a broad class of games that admits many Nash equilibria and that properly includes strongly monotone games. We characterize the finite-time last-iterate convergence rate for joint OGD learning on $\lambda$-cocoercive games; further, building on this result, we develop a fully adaptive OGD learning algorithm that does not require any knowledge of the problem parameter (e.g., the cocoercive constant $\lambda$) and show, via a novel double-stopping-time technique, that this adaptive algorithm achieves the same finite-time last-iterate convergence rate as its non-adaptive counterpart. Subsequently, we extend OGD learning to the noisy gradient feedback case and establish last-iterate convergence results---first qualitative almost sure convergence, then quantitative finite-time convergence rates---all under non-decreasing step-sizes. These results fill in several gaps in the existing multi-agent online learning literature, where three aspects---finite-time convergence rates, non-decreasing step-sizes, and fully adaptive algorithms---have not been previously explored.
Delay-Adaptive Learning in Generalized Linear Contextual Bandits
Mar 11, 2020
In this paper, we consider online learning in generalized linear contextual bandits where rewards are not immediately observed. Instead, rewards are available to the decision-maker only after some delay, which is unknown and stochastic. We study the performance of two well-known algorithms adapted to this delayed setting: one based on upper confidence bounds, and the other based on Thompson sampling. We describe modifications on how these two algorithms should be adapted to handle delays and give regret characterizations for both algorithms. Our results contribute to the broad landscape of contextual bandits literature by establishing that both algorithms can be made to be robust to delays, thereby helping clarify and reaffirm the empirical success of these two algorithms, which are widely deployed in modern recommendation engines.
Provably Efficient Reinforcement Learning with Aggregated States
Dec 13, 2019We establish that an optimistic variant of Q-learning applied to a finite-horizon episodic Markov decision process with an aggregated state representation incurs regret $\tilde{\mathcal{O}}(\sqrt{H^5 M K} + \epsilon HK)$, where $H$ is the horizon, $M$ is the number of aggregate states, $K$ is the number of episodes, and $\epsilon$ is the largest difference between any pair of optimal state-action values associated with a common aggregate state. Notably, this regret bound does not depend on the number of states or actions. To the best of our knowledge, this is the first such result pertaining to a reinforcement learning algorithm applied with nontrivial value function approximation without any restrictions on the Markov decision process.
Balanced Linear Contextual Bandits
Dec 15, 2018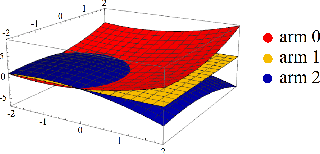
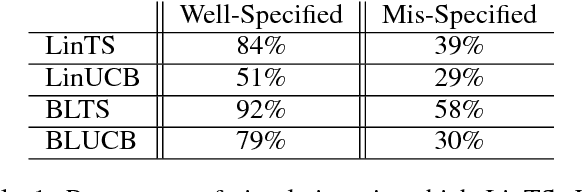
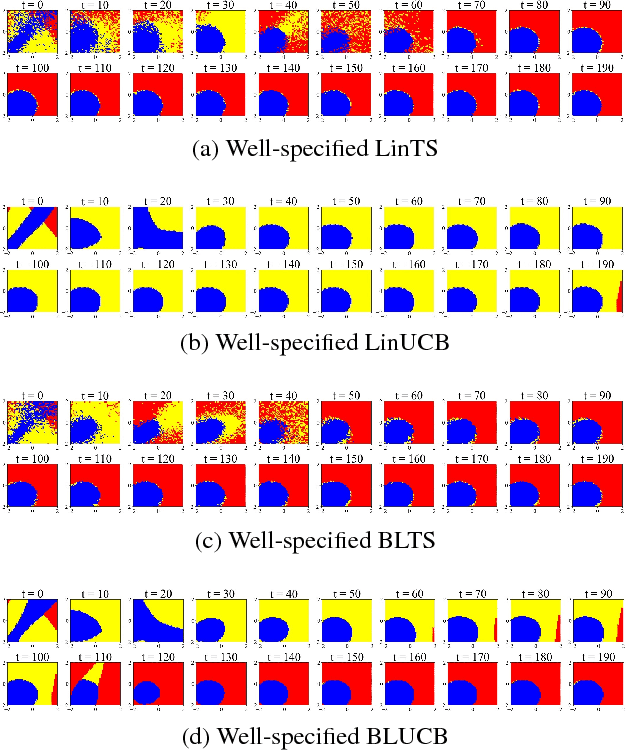
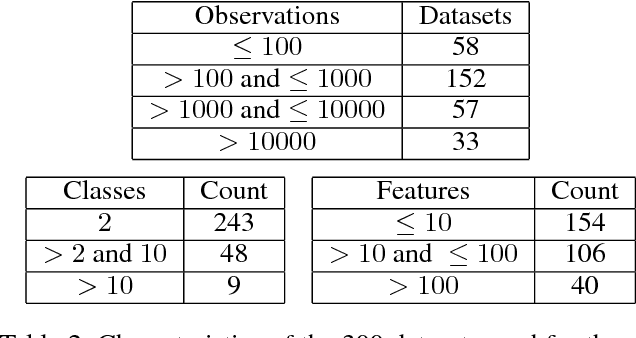
Contextual bandit algorithms are sensitive to the estimation method of the outcome model as well as the exploration method used, particularly in the presence of rich heterogeneity or complex outcome models, which can lead to difficult estimation problems along the path of learning. We develop algorithms for contextual bandits with linear payoffs that integrate balancing methods from the causal inference literature in their estimation to make it less prone to problems of estimation bias. We provide the first regret bound analyses for linear contextual bandits with balancing and show that our algorithms match the state of the art theoretical guarantees. We demonstrate the strong practical advantage of balanced contextual bandits on a large number of supervised learning datasets and on a synthetic example that simulates model misspecification and prejudice in the initial training data.
Offline Multi-Action Policy Learning: Generalization and Optimization
Oct 10, 2018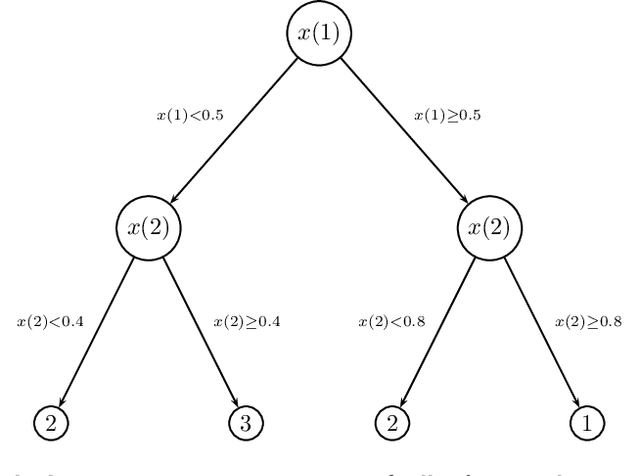
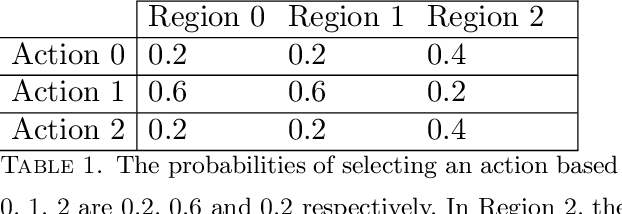
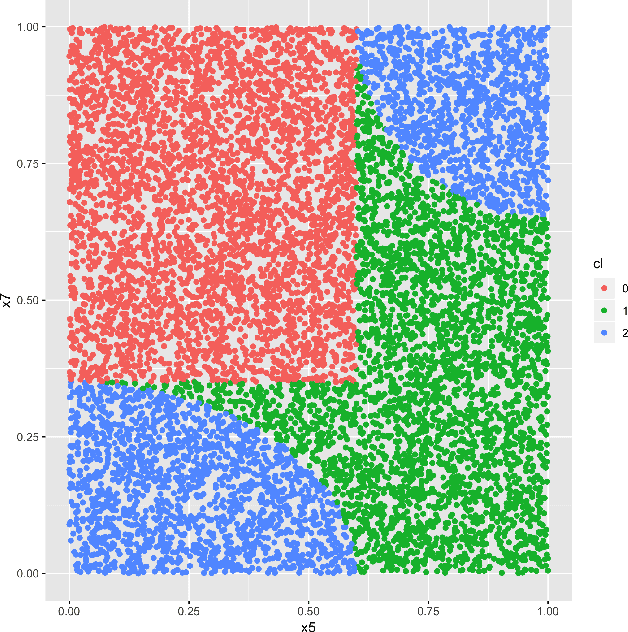
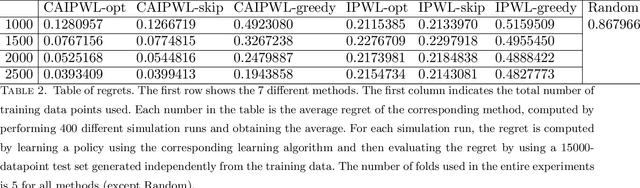
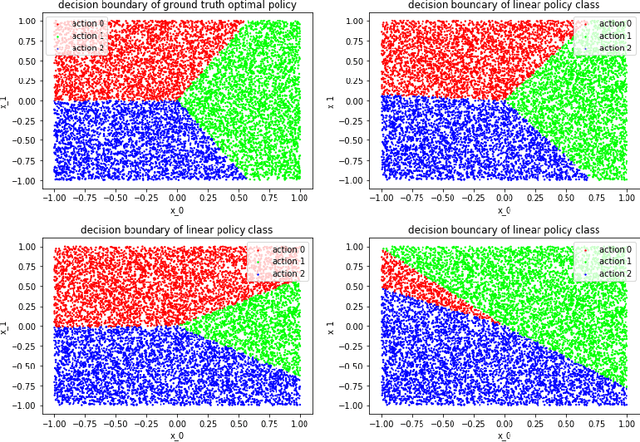
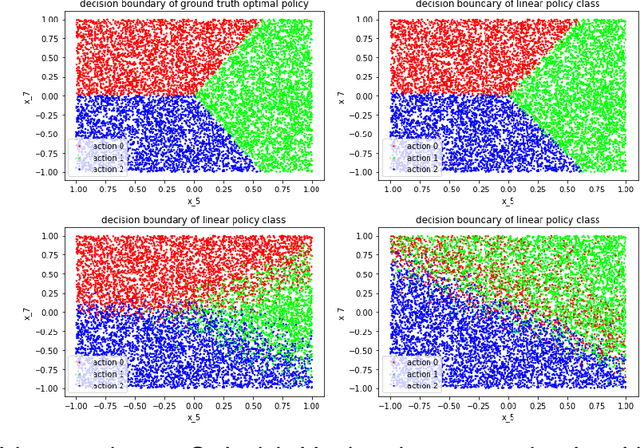
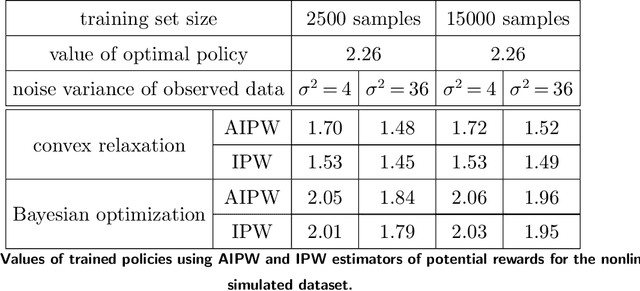
In many settings, a decision-maker wishes to learn a rule, or policy, that maps from observable characteristics of an individual to an action. Examples include selecting offers, prices, advertisements, or emails to send to consumers, as well as the problem of determining which medication to prescribe to a patient. While there is a growing body of literature devoted to this problem, most existing results are focused on the case where data comes from a randomized experiment, and further, there are only two possible actions, such as giving a drug to a patient or not. In this paper, we study the offline multi-action policy learning problem with observational data and where the policy may need to respect budget constraints or belong to a restricted policy class such as decision trees. We build on the theory of efficient semi-parametric inference in order to propose and implement a policy learning algorithm that achieves asymptotically minimax-optimal regret. To the best of our knowledge, this is the first result of this type in the multi-action setup, and it provides a substantial performance improvement over the existing learning algorithms. We then consider additional computational challenges that arise in implementing our method for the case where the policy is restricted to take the form of a decision tree. We propose two different approaches, one using a mixed integer program formulation and the other using a tree-search based algorithm.
MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels
Aug 13, 2018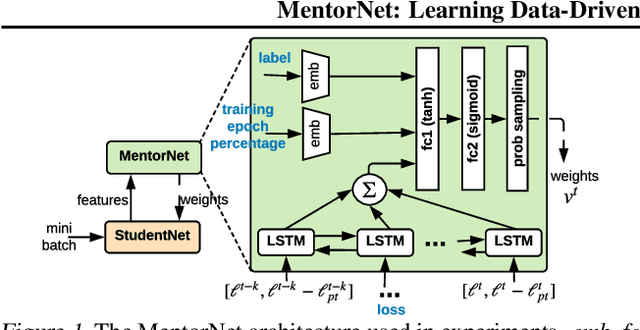
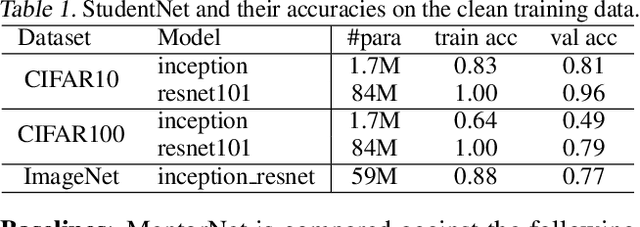

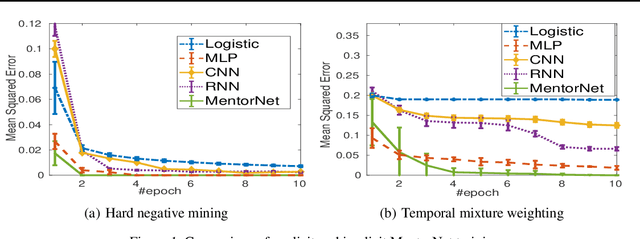
Recent deep networks are capable of memorizing the entire data even when the labels are completely random. To overcome the overfitting on corrupted labels, we propose a novel technique of learning another neural network, called MentorNet, to supervise the training of the base deep networks, namely, StudentNet. During training, MentorNet provides a curriculum (sample weighting scheme) for StudentNet to focus on the sample the label of which is probably correct. Unlike the existing curriculum that is usually predefined by human experts, MentorNet learns a data-driven curriculum dynamically with StudentNet. Experimental results demonstrate that our approach can significantly improve the generalization performance of deep networks trained on corrupted training data. Notably, to the best of our knowledge, we achieve the best-published result on WebVision, a large benchmark containing 2.2 million images of real-world noisy labels. The code are at https://github.com/google/mentornet