 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Reasoning for Fine-Grained Evidence Disentanglement in VideoQA
Jun 08, 2026Recent advances in video multimodal models have significantly improved VideoQA performance. However, these systems often rely on spurious statistical correlations rather than answer-relevant causal evidence, resulting in unfaithful and brittle reasoning, especially in complex real-world scenarios. Existing methods either rely on cross-modality correlations, costly curated training resources, or insufficient causal assumptions and constraints, and typically operate at the time-interval level. As a result, they fail to explicitly disentangle causal visual cues from confounders and provide limited fine-grained evidence localization. To address this issue, we propose a Counterfactual Reasoning framework for fine-grained Evidence Disentanglement (CREDiT). CREDiT formulates the VideoQA process using a structural causal model and learns cross-modality representations that are explicitly decomposed into causal and non-causal components under independence and minimality constraints. To facilitate faithful disentanglement, we introduce feature-level causal interventions and construct counterfactual inputs that approximate causal effects while suppressing non-causal correlations. Extensive experiments on NExT-GQA, SportsQA, and SPORTU-video demonstrate that CREDiT consistently improves answer accuracy and reasoning reliability across both generic and complex sports scenarios, leading to more trustworthy VideoQA systems.
Disentanglement-Based Equivariant Learning for Compositional VQA
Jun 01, 2026Compositional visual question answering (VQA) represents a challenging yet fundamental task that requires models to comprehend novel combinations of previously learned concepts. The current methods often overlook the disentanglement of underlying concepts and are restricted in terms of their ability to effectively capture the compositional variation mechanism. Moreover, the state-of-the-art techniques depend on additional clues for training, which is not feasible in real-world VQA scenarios. To address these issues, in this paper, we introduce a novel Disentanglement-based EquivAriant Learning (DEAL) framework for compositional VQA, which is guided exclusively by ground-truth answers. In DEAL, we employ causality-inspired interventions to disentangle concepts derived from visual and textual inputs within a re-encoding framework. Based on the principle of equivariance, we subsequently perform a compositional transformation on the inference input and impose the equivariant constraint on the output to augment the compositional reasoning capacity of the model. Comprehensive experiments conducted on the benchmark CLEVR-CoGenT and GQA-SGL datasets validate the superiority of our proposed DEAL approach over the existing state-of-the-art methods for compositional VQA tasks in both visual and linguistic generalization settings.
* Accepted by IEEE Transactions on Multimedia
Adversarial Multimodal Network for Movie Question Answering
Jun 24, 2019

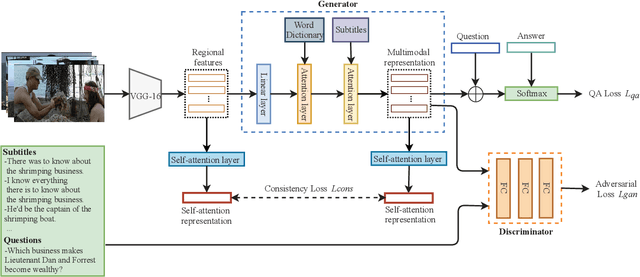
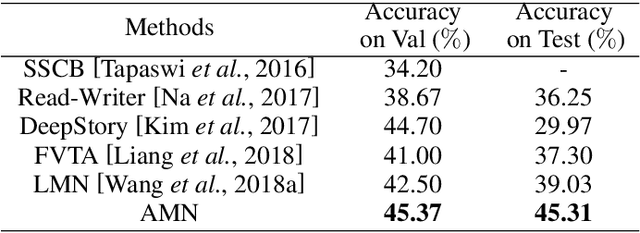
Visual question answering by using information from multiple modalities has attracted more and more attention in recent years. However, it is a very challenging task, as the visual content and natural language have quite different statistical properties. In this work, we present a method called Adversarial Multimodal Network (AMN) to better understand video stories for question answering. In AMN, as inspired by generative adversarial networks, we propose to learn multimodal feature representations by finding a more coherent subspace for video clips and the corresponding texts (e.g., subtitles and questions). Moreover, we introduce a self-attention mechanism to enforce the so-called consistency constraints in order to preserve the self-correlation of visual cues of the original video clips in the learned multimodal representations. Extensive experiments on the MovieQA dataset show the effectiveness of our proposed AMN over other published state-of-the-art methods.