 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Boosting: Joint Feature Selection and Analysis Dictionary Learning in Hierarchy
Aug 11, 2015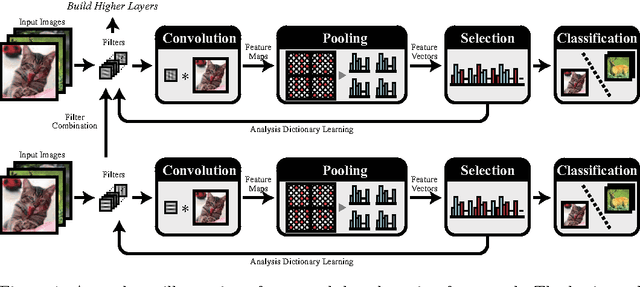
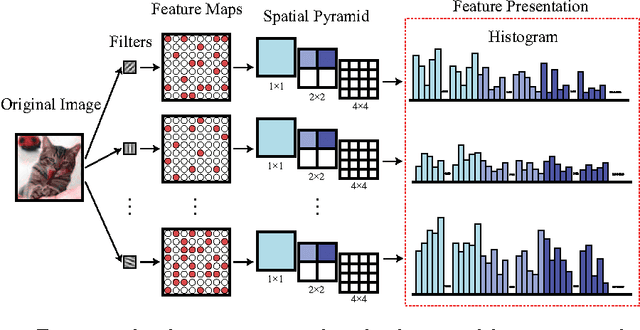

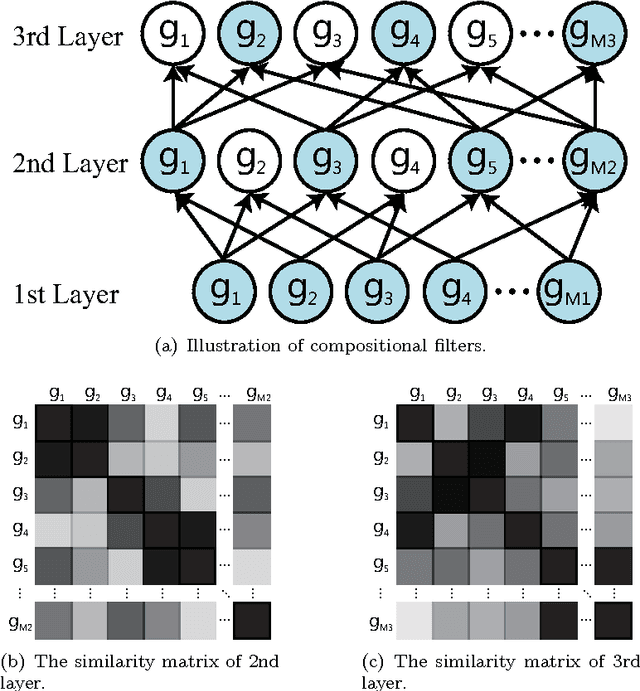
This work investigates how the traditional image classification pipelines can be extended into a deep architecture, inspired by recent successes of deep neural networks. We propose a deep boosting framework based on layer-by-layer joint feature boosting and dictionary learning. In each layer, we construct a dictionary of filters by combining the filters from the lower layer, and iteratively optimize the image representation with a joint discriminative-generative formulation, i.e. minimization of empirical classification error plus regularization of analysis image generation over training images. For optimization, we perform two iterating steps: i) to minimize the classification error, select the most discriminative features using the gentle adaboost algorithm; ii) according to the feature selection, update the filters to minimize the regularization on analysis image representation using the gradient descent method. Once the optimization is converged, we learn the higher layer representation in the same way. Our model delivers several distinct advantages. First, our layer-wise optimization provides the potential to build very deep architectures. Second, the generated image representation is compact and meaningful. In several visual recognition tasks, our framework outperforms existing state-of-the-art approaches.
Data-Driven Scene Understanding with Adaptively Retrieved Exemplars
Feb 03, 2015
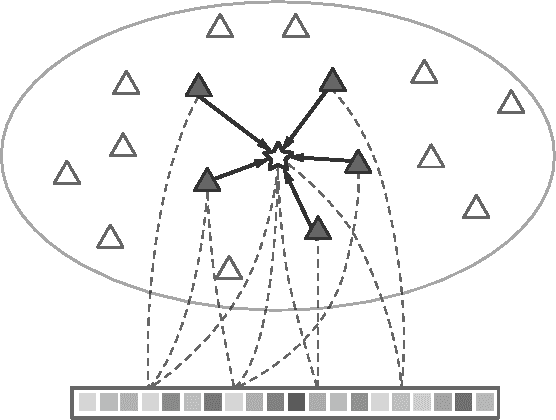

This article investigates a data-driven approach for semantically scene understanding, without pixelwise annotation and classifier training. Our framework parses a target image with two steps: (i) retrieving its exemplars (i.e. references) from an image database, where all images are unsegmented but annotated with tags; (ii) recovering its pixel labels by propagating semantics from the references. We present a novel framework making the two steps mutually conditional and bootstrapped under the probabilistic Expectation-Maximization (EM) formulation. In the first step, the references are selected by jointly matching their appearances with the target as well as the semantics (i.e. the assigned labels of the target and the references). We process the second step via a combinatorial graphical representation, in which the vertices are superpixels extracted from the target and its selected references. Then we derive the potentials of assigning labels to one vertex of the target, which depend upon the graph edges that connect the vertex to its spatial neighbors of the target and to its similar vertices of the references. Besides, the proposed framework can be naturally applied to perform image annotation on new test images. In the experiments, we validate our approach on two public databases, and demonstrate superior performances over the state-of-the-art methods in both semantic segmentation and image annotation tasks.
* 8 pages, 5 figures