 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveform Boundary Detection for Partially Spoofed Audio
Nov 01, 2022



The present paper proposes a waveform boundary detection system for audio spoofing attacks containing partially manipulated segments. Partially spoofed/fake audio, where part of the utterance is replaced, either with synthetic or natural audio clips, has recently been reported as one scenario of audio deepfakes. As deepfakes can be a threat to social security, the detection of such spoofing audio is essential. Accordingly, we propose to address the problem with a deep learning-based frame-level detection system that can detect partially spoofed audio and locate the manipulated pieces. Our proposed method is trained and evaluated on data provided by the ADD2022 Challenge. We evaluate our detection model concerning various acoustic features and network configurations. As a result, our detection system achieves an equal error rate (EER) of 6.58% on the ADD2022 challenge test set, which is the best performance in partially spoofed audio detection systems that can locate manipulated clips.
Identifying Source Speakers for Voice Conversion based Spoofing Attacks on Speaker Verification Systems
Jun 18, 2022
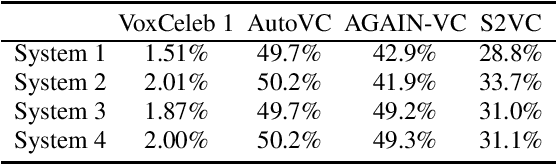


An automatic speaker verification system aims to verify the speaker identity of a speech signal. However, a voice conversion system manipulates the original person's speech signal to make it sound like the target speaker's voice and deceive the speaker verification system. Most countermeasures for voice conversion-based spoofing attacks are designed to discriminate bona fide speech from spoofed speech for speaker verification systems. In this paper, we investigate the problem of source speaker identification -- inferring the identity of the source speaker given the voice converted speech. To perform source speaker identification, we simply add voice-converted speech data with the label of source speaker identity to the genuine speech dataset during speaker embedding network training. Experimental results show the feasibility of source speaker identification when training and testing with converted speeches from the same voice conversion model(s). When testing on converted speeches from an unseen voice conversion algorithm, the performance of source speaker identification improves when more voice conversion models are used during training.
Invertible Voice Conversion
Jan 26, 2022In this paper, we propose an invertible deep learning framework called INVVC for voice conversion. It is designed against the possible threats that inherently come along with voice conversion systems. Specifically, we develop an invertible framework that makes the source identity traceable. The framework is built on a series of invertible $1\times1$ convolutions and flows consisting of affine coupling layers. We apply the proposed framework to one-to-one voice conversion and many-to-one conversion using parallel training data. Experimental results show that this approach yields impressive performance on voice conversion and, moreover, the converted results can be reversed back to the source inputs utilizing the same parameters as in forwarding.
The DKU System Description for The Interspeech 2021 Auto-KWS Challenge
Apr 11, 2021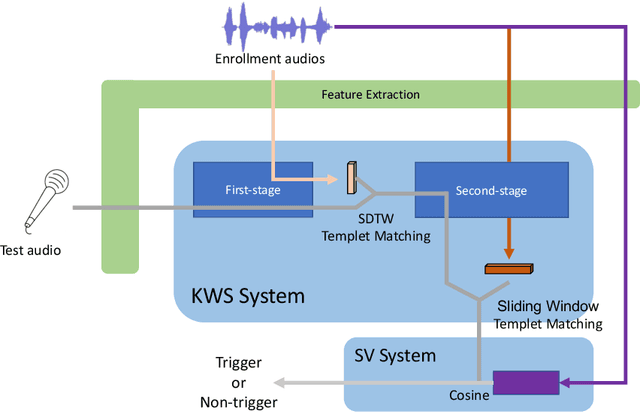
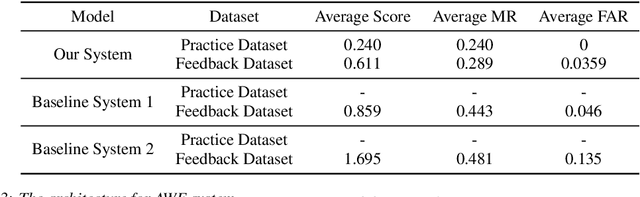
This paper introduces the system submitted by the DKU-SMIIP team for the Auto-KWS 2021 Challenge. Our implementation consists of a two-stage keyword spotting system based on query-by-example spoken term detection and a speaker verification system. We employ two different detection algorithms in our proposed keyword spotting system. The first stage adopts subsequence dynamic time warping for template matching based on frame-level language-independent bottleneck feature and phoneme posterior probability. We use a sliding window template matching algorithm based on acoustic word embeddings to further verify the detection from the first stage. As a result, our KWS system achieves an average score of 0.61 on the feedback dataset, which outperforms the baseline1 system by 0.25.
Training Wake Word Detection with Synthesized Speech Data on Confusion Words
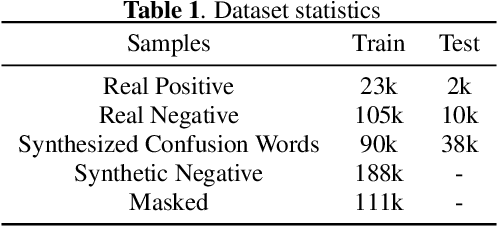
Nov 03, 2020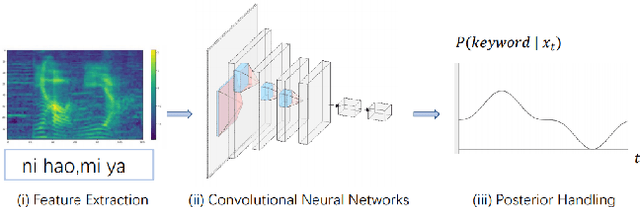
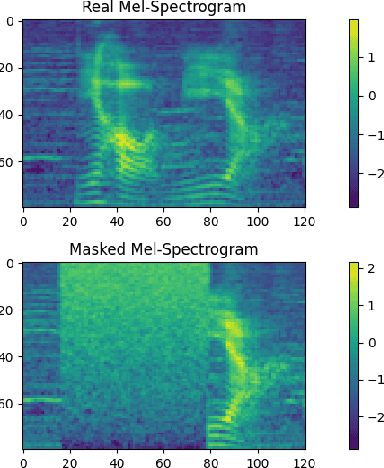
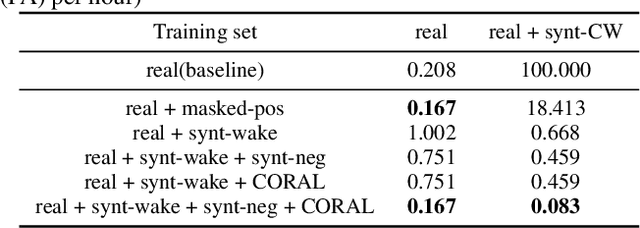
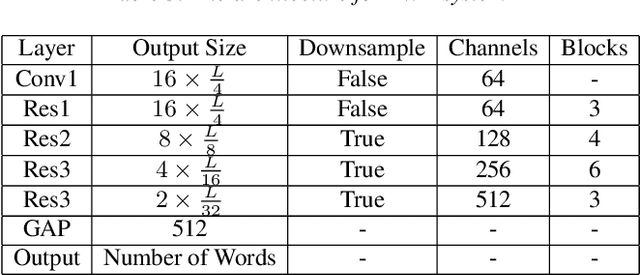
Confusing-words are commonly encountered in real-life keyword spotting applications, which causes severe degradation of performance due to complex spoken terms and various kinds of words that sound similar to the predefined keywords. To enhance the wake word detection system's robustness on such scenarios, we investigate two data augmentation setups for training end-to-end KWS systems. One is involving the synthesized data from a multi-speaker speech synthesis system, and the other augmentation is performed by adding random noise to the acoustic feature. Experimental results show that augmentations help improve the system's robustness. Moreover, by augmenting the training set with the synthetic data generated by the multi-speaker text-to-speech system, we achieve a significant improvement regarding confusing words scenario.
Cross-lingual Multispeaker Text-to-Speech under Limited-Data Scenario
May 21, 2020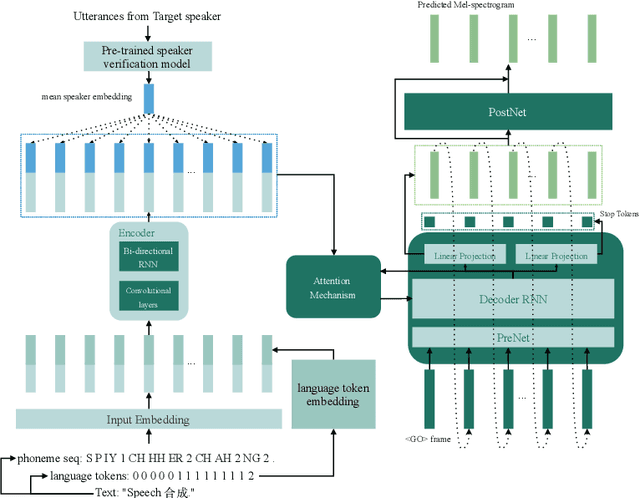
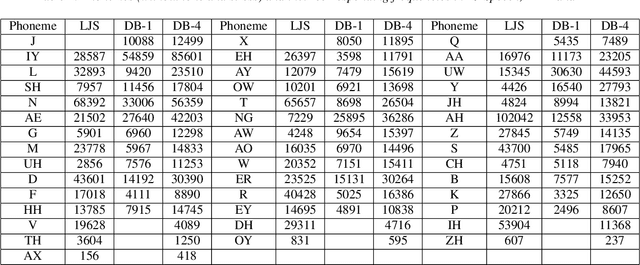

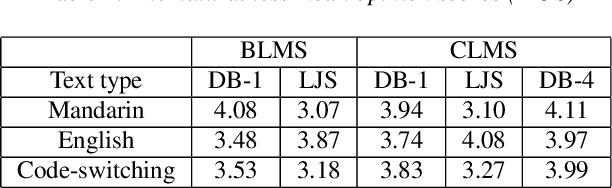
Modeling voices for multiple speakers and multiple languages in one text-to-speech system has been a challenge for a long time. This paper presents an extension on Tacotron2 to achieve bilingual multispeaker speech synthesis when there are limited data for each language. We achieve cross-lingual synthesis, including code-switching cases, between English and Mandarin for monolingual speakers. The two languages share the same phonemic representations for input, while the language attribute and the speaker identity are independently controlled by language tokens and speaker embeddings, respectively. In addition, we investigate the model's performance on the cross-lingual synthesis, with and without a bilingual dataset during training. With the bilingual dataset, not only can the model generate high-fidelity speech for all speakers concerning the language they speak, but also can generate accented, yet fluent and intelligible speech for monolingual speakers regarding non-native language. For example, the Mandarin speaker can speak English fluently. Furthermore, the model trained with bilingual dataset is robust for code-switching text-to-speech, as shown in our results and provided samples.{https://caizexin.github.io/mlms-syn-samples/index.html}.
From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint
May 15, 2020
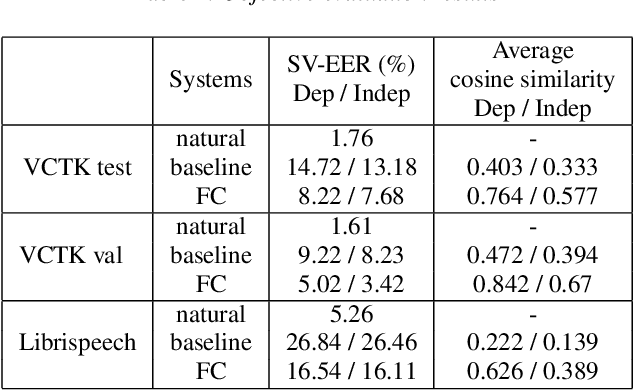
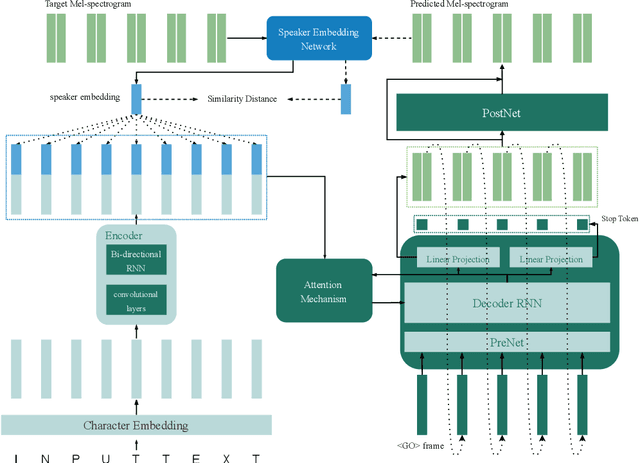
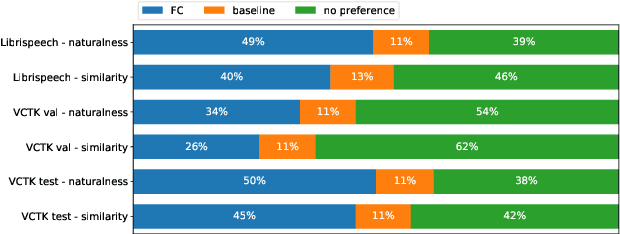
High-fidelity speech can be synthesized by end-to-end text-to-speech models in recent years. However, accessing and controlling speech attributes such as speaker identity, prosody, and emotion in a text-to-speech system remains a challenge. This paper presents a system involving feedback constraint for multispeaker speech synthesis. We manage to enhance the knowledge transfer from the speaker verification to the speech synthesis by engaging the speaker verification network. The constraint is taken by an added loss related to the speaker identity, which is centralized to improve the speaker similarity between the synthesized speech and its natural reference audio. The model is trained and evaluated on publicly available datasets. Experimental results, including visualization on speaker embedding space, show significant improvement in terms of speaker identity cloning in the spectrogram level. Synthesized samples are available online for listening. (https://caizexin.github.io/mlspk-syn-samples/index.html)
Polyphone Disambiguation for Mandarin Chinese Using Conditional Neural Network with Multi-level Embedding Features
Jul 03, 2019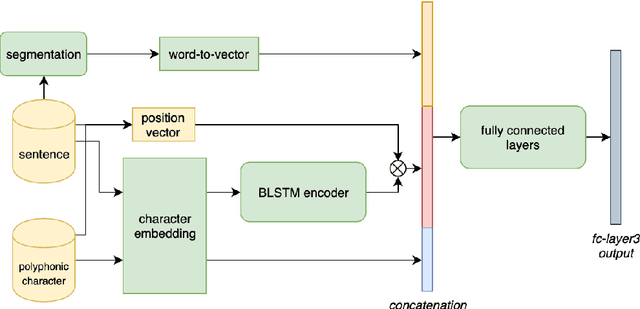
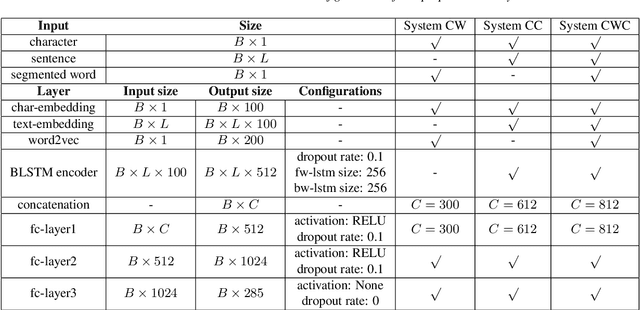
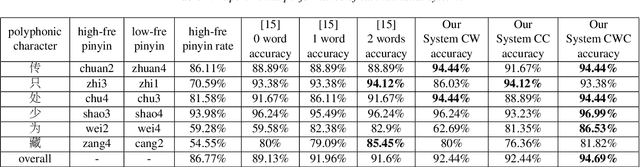
This paper describes a conditional neural network architecture for Mandarin Chinese polyphone disambiguation. The system is composed of a bidirectional recurrent neural network component acting as a sentence encoder to accumulate the context correlations, followed by a prediction network that maps the polyphonic character embeddings along with the conditions to corresponding pronunciations. We obtain the word-level condition from a pre-trained word-to-vector lookup table. One goal of polyphone disambiguation is to address the homograph problem existing in the front-end processing of Mandarin Chinese text-to-speech system. Our system achieves an accuracy of 94.69\% on a publicly available polyphonic character dataset. To further validate our choices on the conditional feature, we investigate polyphone disambiguation systems with multi-level conditions respectively. The experimental results show that both the sentence-level and the word-level conditional embedding features are able to attain good performance for Mandarin Chinese polyphone disambiguation.
End-to-end Language Identification using NetFV and NetVLAD
Sep 09, 2018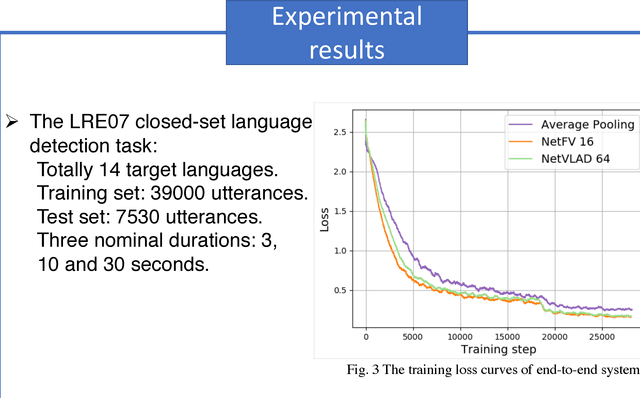
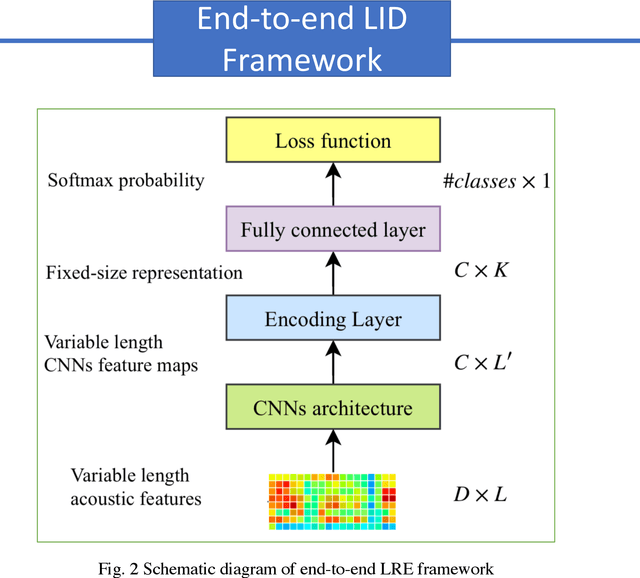
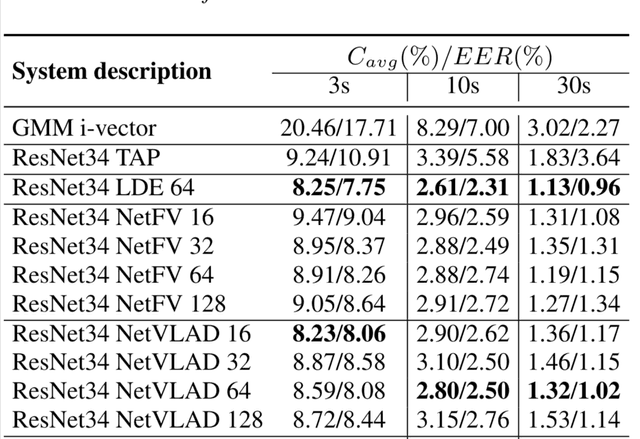
In this paper, we apply the NetFV and NetVLAD layers for the end-to-end language identification task. NetFV and NetVLAD layers are the differentiable implementations of the standard Fisher Vector and Vector of Locally Aggregated Descriptors (VLAD) methods, respectively. Both of them can encode a sequence of feature vectors into a fixed dimensional vector which is very important to process those variable-length utterances. We first present the relevances and differences between the classical i-vector and the aforementioned encoding schemes. Then, we construct a flexible end-to-end framework including a convolutional neural network (CNN) architecture and an encoding layer (NetFV or NetVLAD) for the language identification task. Experimental results on the NIST LRE 2007 close-set task show that the proposed system achieves significant EER reductions against the conventional i-vector baseline and the CNN temporal average pooling system, respectively.
A Novel Learnable Dictionary Encoding Layer for End-to-End Language Identification
Apr 02, 2018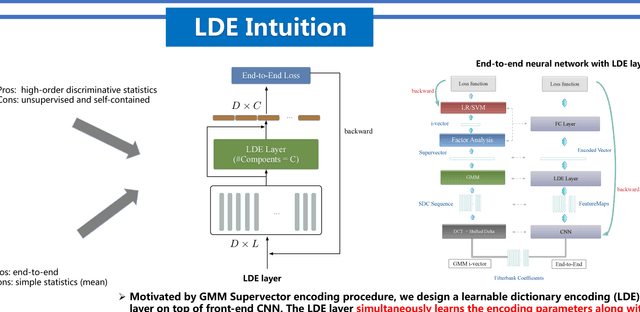
A novel learnable dictionary encoding layer is proposed in this paper for end-to-end language identification. It is inline with the conventional GMM i-vector approach both theoretically and practically. We imitate the mechanism of traditional GMM training and Supervector encoding procedure on the top of CNN. The proposed layer can accumulate high-order statistics from variable-length input sequence and generate an utterance level fixed-dimensional vector representation. Unlike the conventional methods, our new approach provides an end-to-end learning framework, where the inherent dictionary are learned directly from the loss function. The dictionaries and the encoding representation for the classifier are learned jointly. The representation is orderless and therefore appropriate for language identification. We conducted a preliminary experiment on NIST LRE07 closed-set task, and the results reveal that our proposed dictionary encoding layer achieves significant error reduction comparing with the simple average pooling.