 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning with Multi-Structure Commonsense Knowledge in Visual Dialog
Apr 10, 2022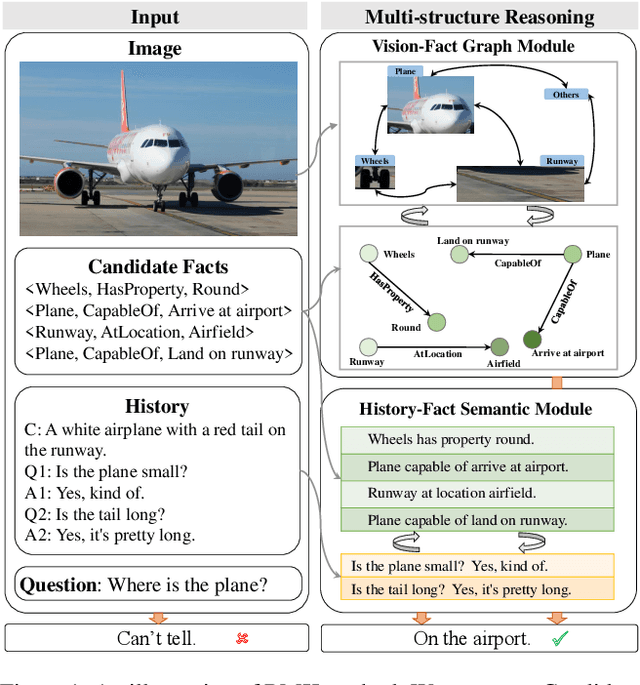
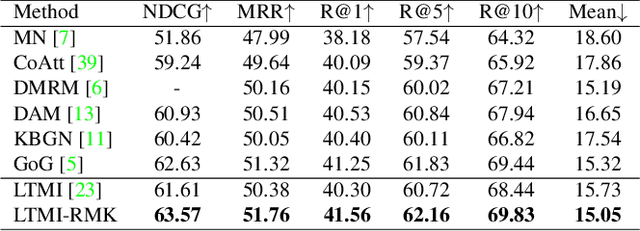
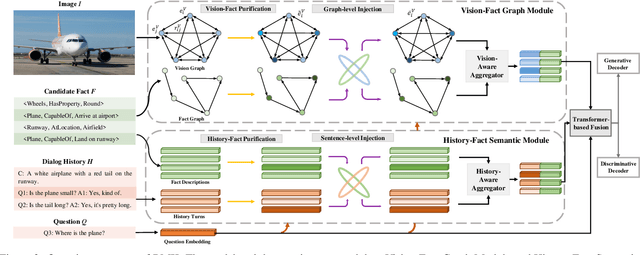
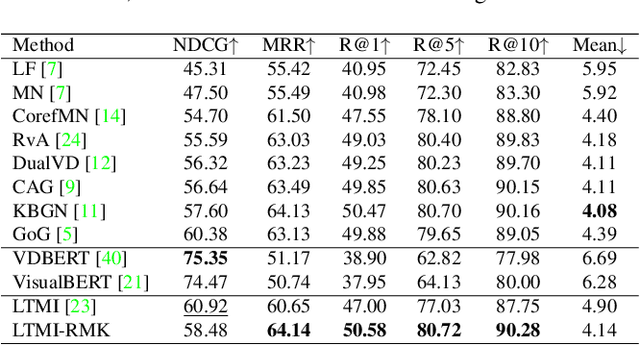
Visual Dialog requires an agent to engage in a conversation with humans grounded in an image. Many studies on Visual Dialog focus on the understanding of the dialog history or the content of an image, while a considerable amount of commonsense-required questions are ignored. Handling these scenarios depends on logical reasoning that requires commonsense priors. How to capture relevant commonsense knowledge complementary to the history and the image remains a key challenge. In this paper, we propose a novel model by Reasoning with Multi-structure Commonsense Knowledge (RMK). In our model, the external knowledge is represented with sentence-level facts and graph-level facts, to properly suit the scenario of the composite of dialog history and image. On top of these multi-structure representations, our model can capture relevant knowledge and incorporate them into the vision and semantic features, via graph-based interaction and transformer-based fusion. Experimental results and analysis on VisDial v1.0 and VisDialCK datasets show that our proposed model effectively outperforms comparative methods.
KBGN: Knowledge-Bridge Graph Network for Adaptive Vision-Text Reasoning in Visual Dialogue
Aug 28, 2020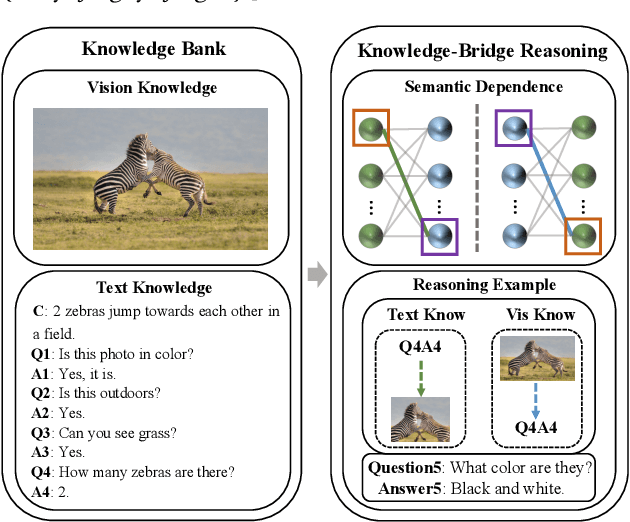
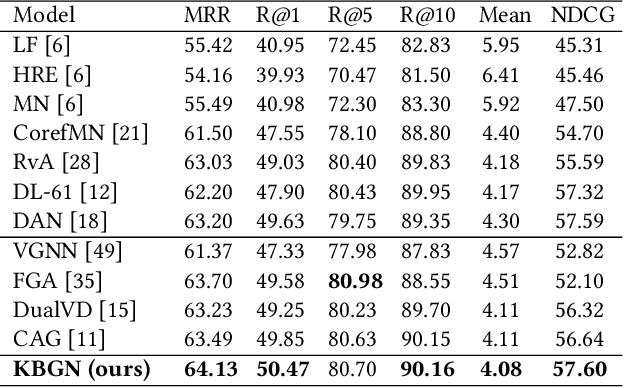
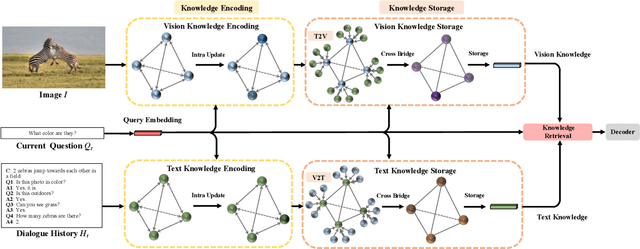
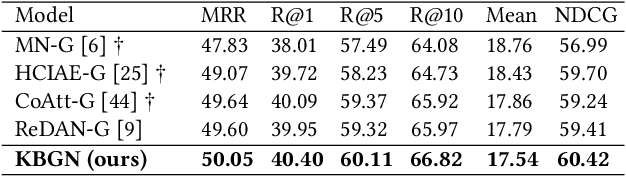
Visual dialogue is a challenging task that needs to extract implicit information from both visual (image) and textual (dialogue history) contexts. Classical approaches pay more attention to the integration of the current question, vision knowledge and text knowledge, despising the heterogeneous semantic gaps between the cross-modal information. In the meantime, the concatenation operation has become de-facto standard to the cross-modal information fusion, which has a limited ability in information retrieval. In this paper, we propose a novel Knowledge-Bridge Graph Network (KBGN) model by using graph to bridge the cross-modal semantic relations between vision and text knowledge in fine granularity, as well as retrieving required knowledge via an adaptive information selection mode. Moreover, the reasoning clues for visual dialogue can be clearly drawn from intra-modal entities and inter-modal bridges. Experimental results on VisDial v1.0 and VisDial-Q datasets demonstrate that our model outperforms existing models with state-of-the-art results.
DAM: Deliberation, Abandon and Memory Networks for Generating Detailed and Non-repetitive Responses in Visual Dialogue
Jul 07, 2020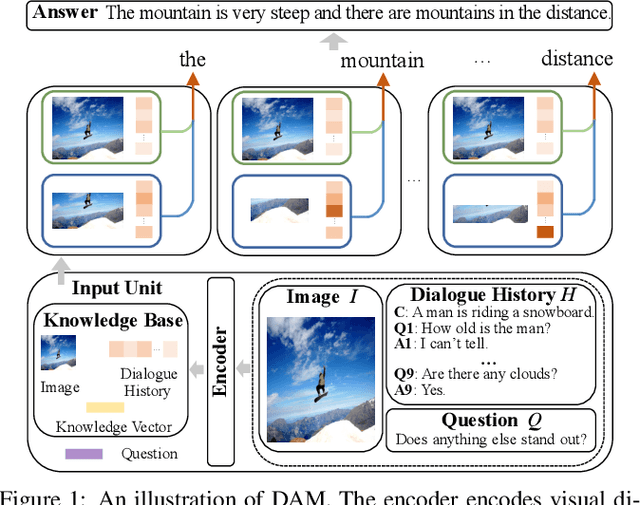
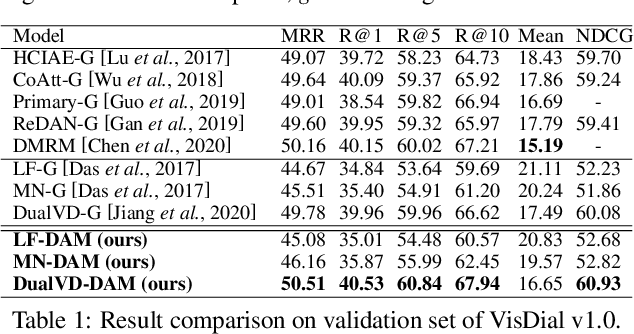
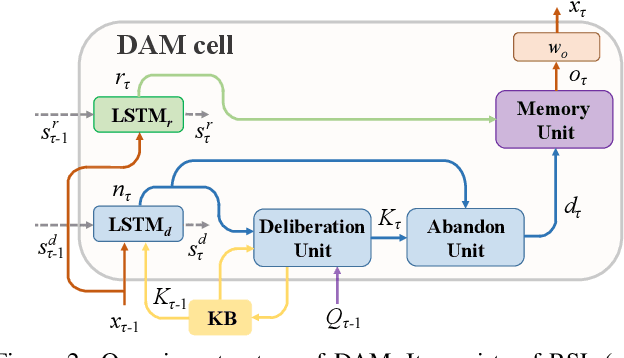
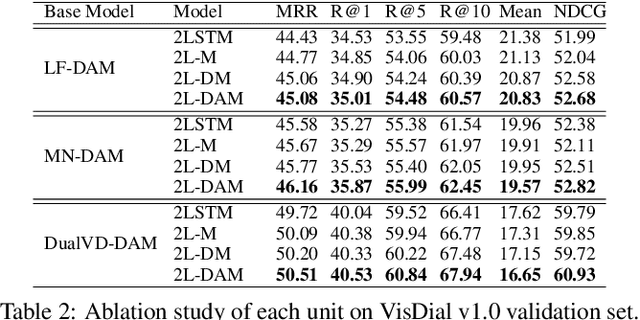
Visual Dialogue task requires an agent to be engaged in a conversation with human about an image. The ability of generating detailed and non-repetitive responses is crucial for the agent to achieve human-like conversation. In this paper, we propose a novel generative decoding architecture to generate high-quality responses, which moves away from decoding the whole encoded semantics towards the design that advocates both transparency and flexibility. In this architecture, word generation is decomposed into a series of attention-based information selection steps, performed by the novel recurrent Deliberation, Abandon and Memory (DAM) module. Each DAM module performs an adaptive combination of the response-level semantics captured from the encoder and the word-level semantics specifically selected for generating each word. Therefore, the responses contain more detailed and non-repetitive descriptions while maintaining the semantic accuracy. Furthermore, DAM is flexible to cooperate with existing visual dialogue encoders and adaptive to the encoder structures by constraining the information selection mode in DAM. We apply DAM to three typical encoders and verify the performance on the VisDial v1.0 dataset. Experimental results show that the proposed models achieve new state-of-the-art performance with high-quality responses. The code is available at https://github.com/JXZe/DAM.
Multi-Level Network for High-Speed Multi-Person Pose Estimation
Nov 26, 2019
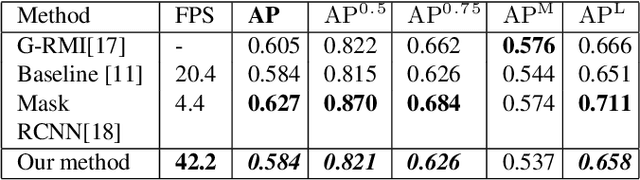
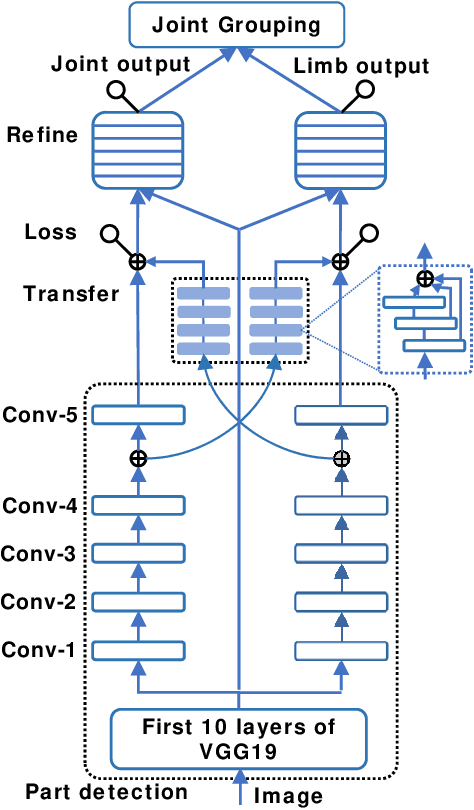

In multi-person pose estimation, the left/right joint type discrimination is always a hard problem because of the similar appearance. Traditionally, we solve this problem by stacking multiple refinement modules to increase network's receptive fields and capture more global context, which can also increase a great amount of computation. In this paper, we propose a Multi-level Network (MLN) that learns to aggregate features from lower-level (left/right information), upper-level (localization information), joint-limb level (complementary information) and global-level (context) information for discrimination of joint type. Through feature reuse and its intra-relation, MLN can attain comparable performance to other conventional methods while runtime speed retains at 42.2 FPS.
FollowMeUp Sports: New Benchmark for 2D Human Keypoint Recognition
Nov 19, 2019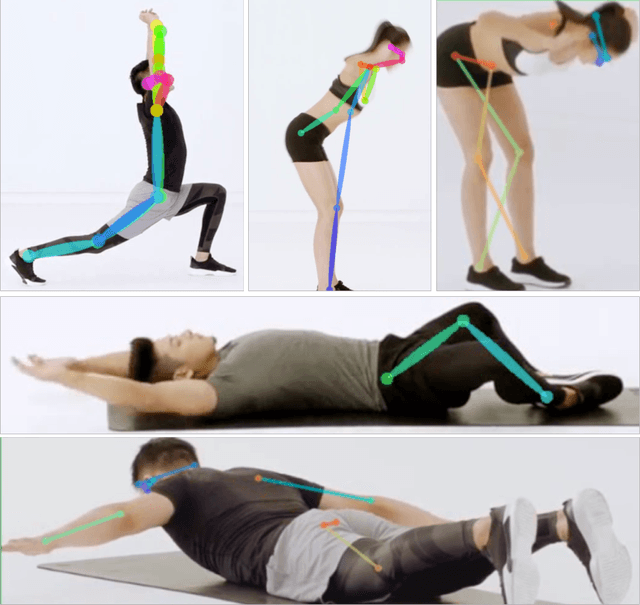

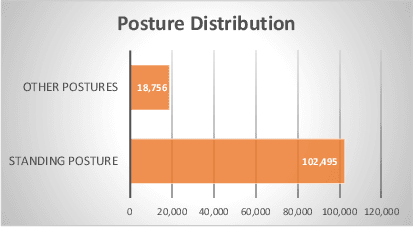
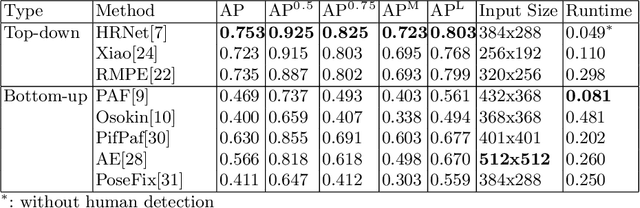
Human pose estimation has made significant advancement in recent years. However, the existing datasets are limited in their coverage of pose variety. In this paper, we introduce a novel benchmark FollowMeUp Sports that makes an important advance in terms of specific postures, self-occlusion and class balance, a contribution that we feel is required for future development in human body models. This comprehensive dataset was collected using an established taxonomy of over 200 standard workout activities with three different shot angles. The collected videos cover a wider variety of specific workout activities than previous datasets including push-up, squat and body moving near the ground with severe self-occlusion or occluded by some sport equipment and outfits. Given these rich images, we perform a detailed analysis of the leading human pose estimation approaches gaining insights for the success and failures of these methods.
DualVD: An Adaptive Dual Encoding Model for Deep Visual Understanding in Visual Dialogue
Nov 17, 2019
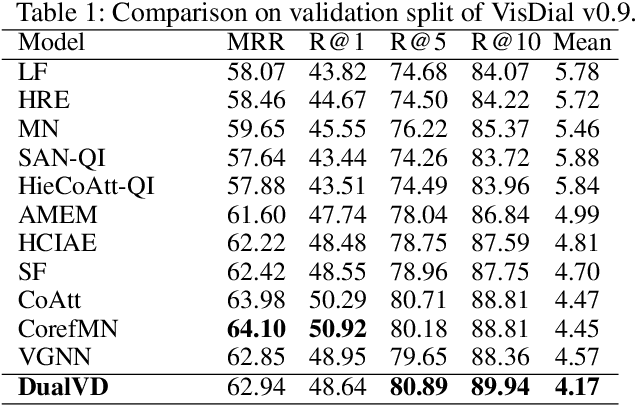
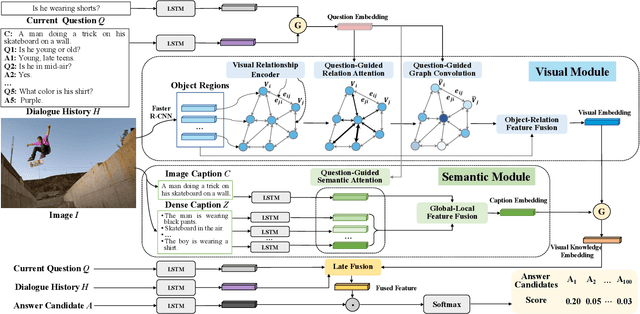
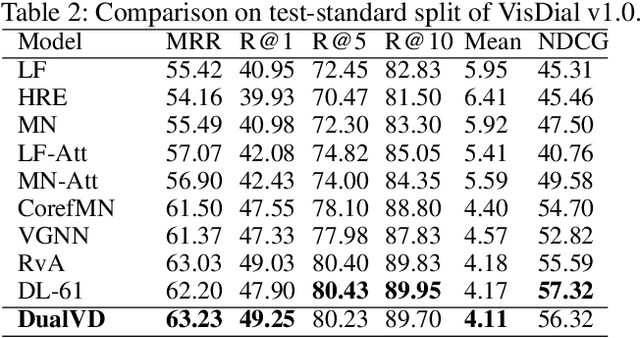
Different from Visual Question Answering task that requires to answer only one question about an image, Visual Dialogue involves multiple questions which cover a broad range of visual content that could be related to any objects, relationships or semantics. The key challenge in Visual Dialogue task is thus to learn a more comprehensive and semantic-rich image representation which may have adaptive attentions on the image for variant questions. In this research, we propose a novel model to depict an image from both visual and semantic perspectives. Specifically, the visual view helps capture the appearance-level information, including objects and their relationships, while the semantic view enables the agent to understand high-level visual semantics from the whole image to the local regions. Futhermore, on top of such multi-view image features, we propose a feature selection framework which is able to adaptively capture question-relevant information hierarchically in fine-grained level. The proposed method achieved state-of-the-art results on benchmark Visual Dialogue datasets. More importantly, we can tell which modality (visual or semantic) has more contribution in answering the current question by visualizing the gate values. It gives us insights in understanding of human cognition in Visual Dialogue.
Structured Knowledge Distillation for Semantic Segmentation
Mar 12, 2019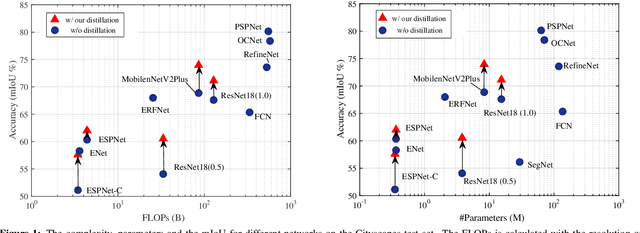
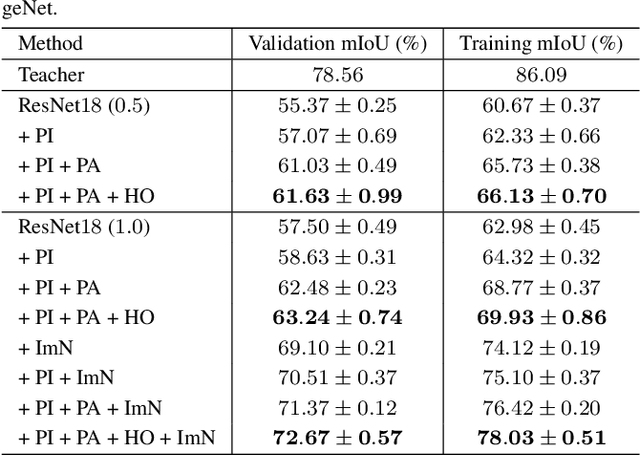
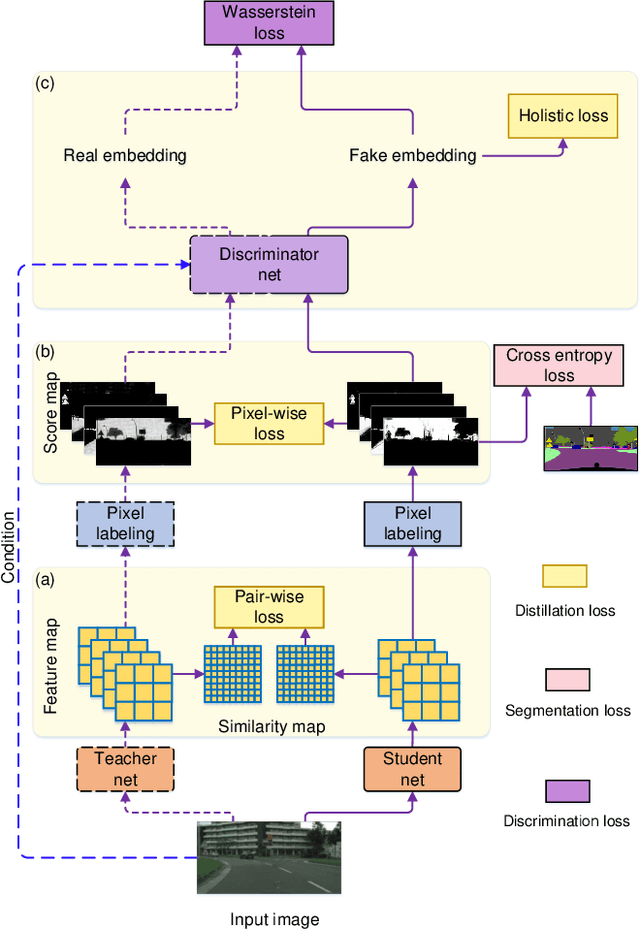
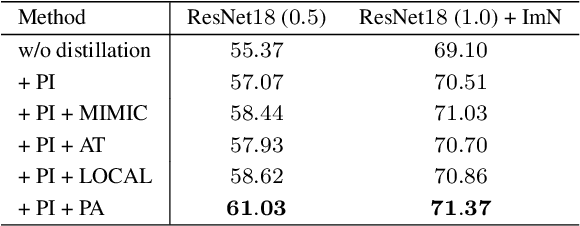
In this paper, we investigate the knowledge distillation strategy for training small semantic segmentation networks by making use of large networks. We start from the straightforward scheme, pixel-wise distillation, which applies the distillation scheme adopted for image classification and performs knowledge distillation for each pixel separately. We further propose to distill the structured knowledge from large networks to small networks, which is motivated by that semantic segmentation is a structured prediction problem. We study two structured distillation schemes: (i) pair-wise distillation that distills the pairwise similarities, and (ii) holistic distillation that uses GAN to distill holistic knowledge. The effectiveness of our knowledge distillation approaches is demonstrated by extensive experiments on three scene parsing datasets: Cityscapes, Camvid and ADE20K.
Multi-modal Learning with Prior Visual Relation Reasoning
Dec 23, 2018
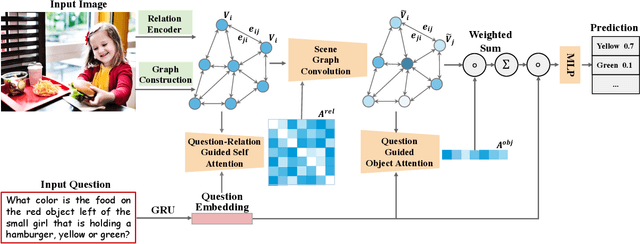

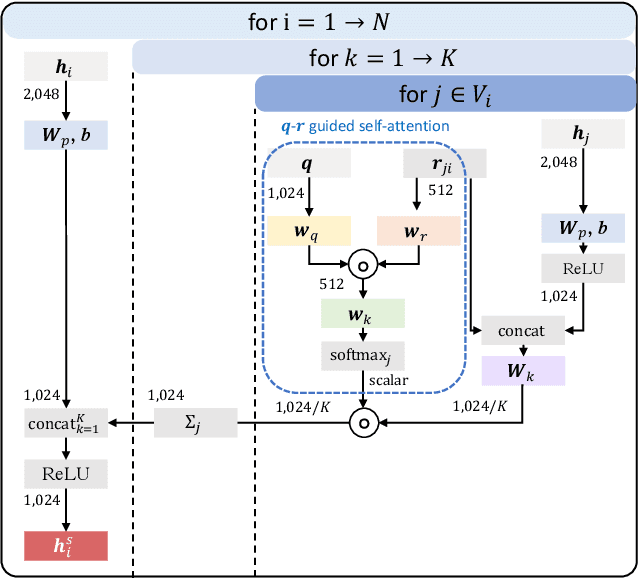
Visual relation reasoning is a central component in recent cross-modal analysis tasks, which aims at reasoning about the visual relationships between objects and their properties. These relationships convey rich semantics and help to enhance the visual representation for improving cross-modal analysis. Previous works have succeeded in designing strategies for modeling latent relations or rigid-categorized relations and achieving the lift of performance. However, this kind of methods leave out the ambiguity inherent in the relations because of the diverse relational semantics of different visual appearances. In this work, we explore to model relations by contextual-sensitive embeddings based on human priori knowledge. We novelly propose a plug-and-play relation reasoning module injected with the relation embeddings to enhance image encoder. Specifically, we design upgraded Graph Convolutional Networks (GCN) to utilize the information of relation embeddings and relation directionality between objects for generating relation-aware image representations. We demonstrate the effectiveness of the relation reasoning module by applying it to both Visual Question Answering (VQA) and Cross-Modal Information Retrieval (CMIR) tasks. Extensive experiments are conducted on VQA 2.0 and CMPlaces datasets and superior performance is reported when comparing with state-of-the-art work.
A sequential guiding network with attention for image captioning
Nov 01, 2018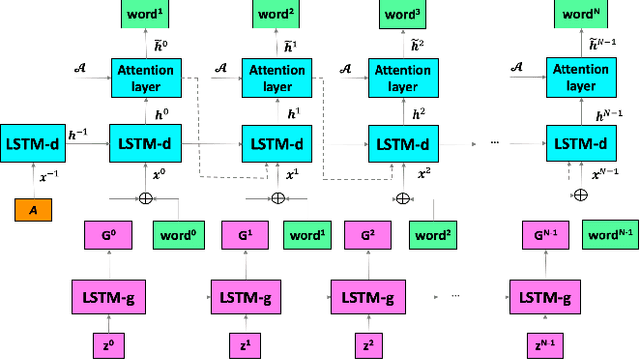
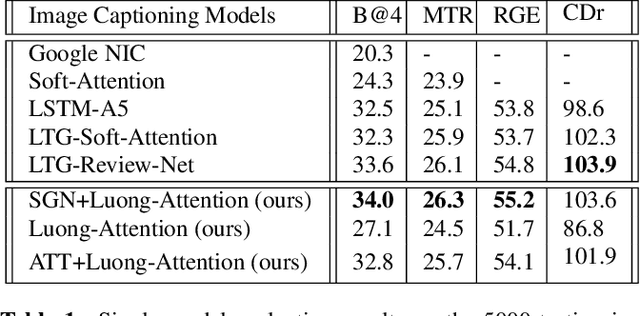
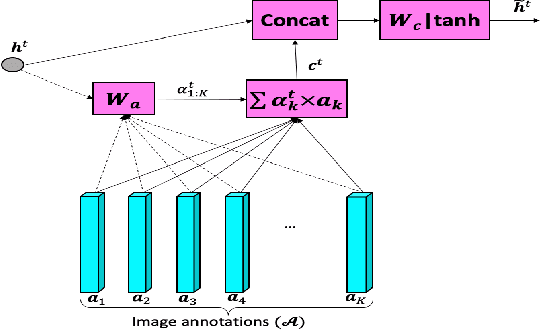
The recent advances of deep learning in both computer vision (CV)and natural language processing (NLP) provide us a new way of un-derstanding semantics, by which we can deal with more challeng-ing tasks such as automatic description generation from natural im-ages. In this challenge, the encoder-decoder framework has achievedpromising performance when a convolutional neural network (CNN)is used as image encoder and a recurrent neural network (RNN) asdecoder. In this paper, we introduce a sequential guiding networkthat guides the decoder during word generation. The new model is anextension of the encoder-decoder framework with attention that hasan additional guiding long short-term memory (LSTM) and can betrained in an end-to-end manner by using image/descriptions pairs.We validate our approach by conducting extensive experiments on abenchmark dataset, i.e., MS COCO Captions. The proposed model achieves significant improvement comparing to the other state-of-the-art deep learning models.
Pixel Level Data Augmentation for Semantic Image Segmentation using Generative Adversarial Networks
Nov 01, 2018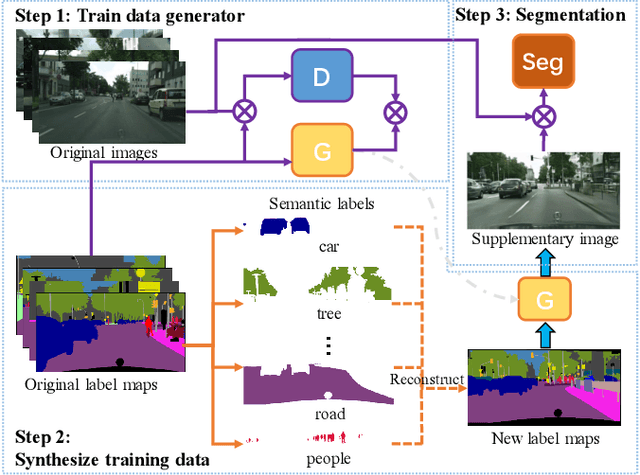

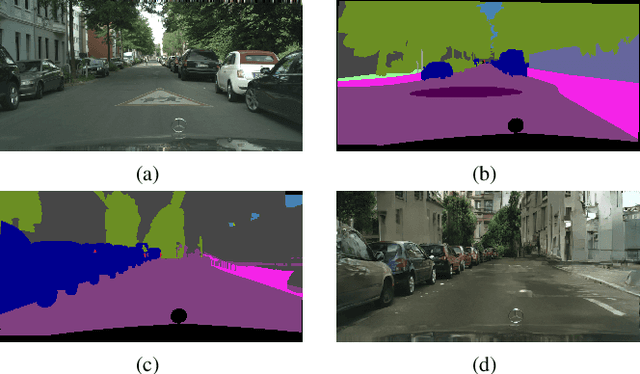
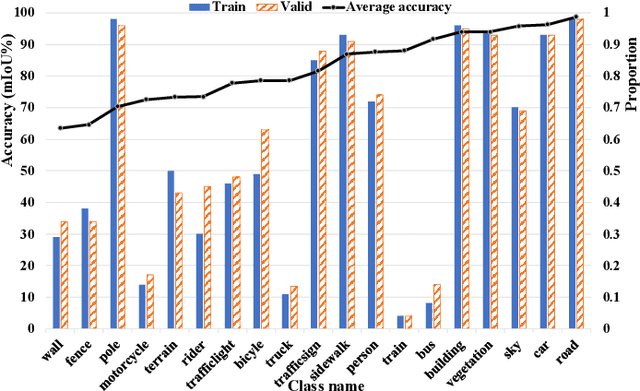
Semantic segmentation is one of the basic topics in computer vision, it aims to assign semantic labels to every pixel of an image. Unbalanced semantic label distribution could have a negative influence on segmentation accuracy. In this paper, we investigate using data augmentation approach to balance the label distribution in order to improve segmentation performance. We propose using generative adversarial networks (GANs) to generate realistic images for improving the performance of semantic segmentation networks. Experimental results show that the proposed method can not only improve segmentation accuracy of those classes with low accuracy, but also obtain 1.3% to 2.1% increase in average segmentation accuracy. It proves that this augmentation method can boost the accuracy and be easily applicable to any other segmentation models.