 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multimodal Response Generation with Exemplar Augmentation and Curriculum Optimization
Apr 26, 2020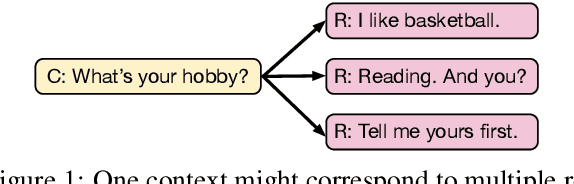
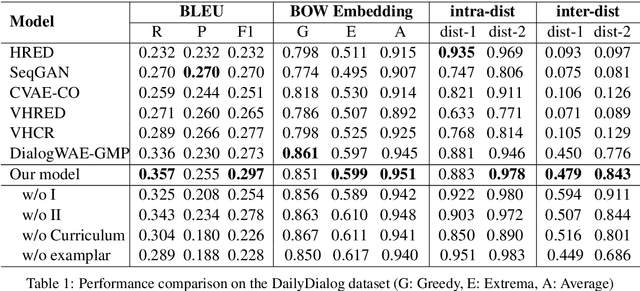
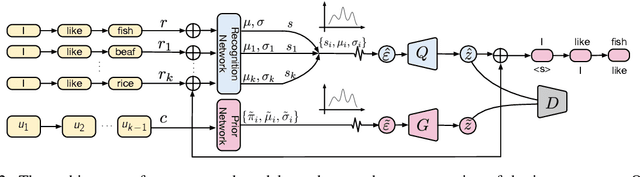
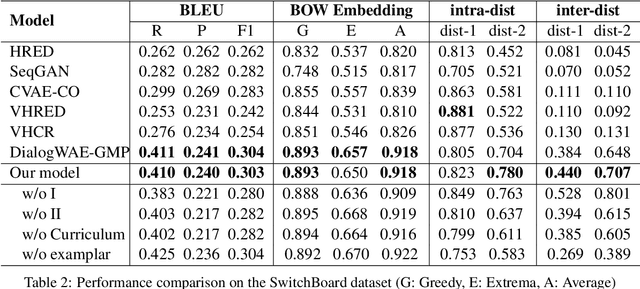
Recently, variational auto-encoder (VAE) based approaches have made impressive progress on improving the diversity of generated responses. However, these methods usually suffer the cost of decreased relevance accompanied by diversity improvements. In this paper, we propose a novel multimodal response generation framework with exemplar augmentation and curriculum optimization to enhance relevance and diversity of generated responses. First, unlike existing VAE-based models that usually approximate a simple Gaussian posterior distribution, we present a Gaussian mixture posterior distribution (i.e, multimodal) to further boost response diversity, which helps capture complex semantics of responses. Then, to ensure that relevance does not decrease while diversity increases, we fully exploit similar examples (exemplars) retrieved from the training data into posterior distribution modeling to augment response relevance. Furthermore, to facilitate the convergence of Gaussian mixture prior and posterior distributions, we devise a curriculum optimization strategy to progressively train the model under multiple training criteria from easy to hard. Experimental results on widely used SwitchBoard and DailyDialog datasets demonstrate that our model achieves significant improvements compared to strong baselines in terms of diversity and relevance.
Bridging Text and Video: A Universal Multimodal Transformer for Video-Audio Scene-Aware Dialog
Feb 01, 2020
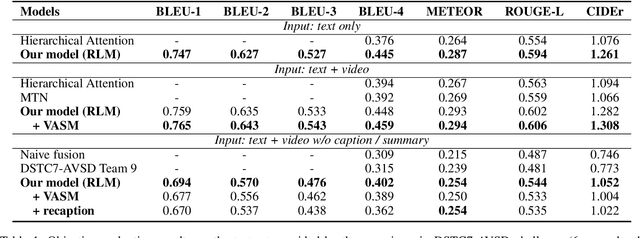
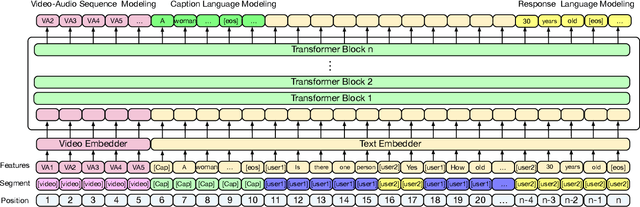
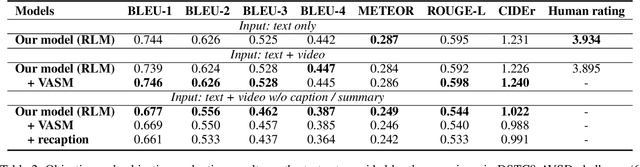
Audio-Visual Scene-Aware Dialog (AVSD) is a task to generate responses when chatting about a given video, which is organized as a track of the 8th Dialog System Technology Challenge (DSTC8). To solve the task, we propose a universal multimodal transformer and introduce the multi-task learning method to learn joint representations among different modalities as well as generate informative and fluent responses. Our method extends the natural language generation pre-trained model to multimodal dialogue generation task. Our system achieves the best performance in both objective and subjective evaluations in the challenge.
Incremental Transformer with Deliberation Decoder for Document Grounded Conversations
Jul 31, 2019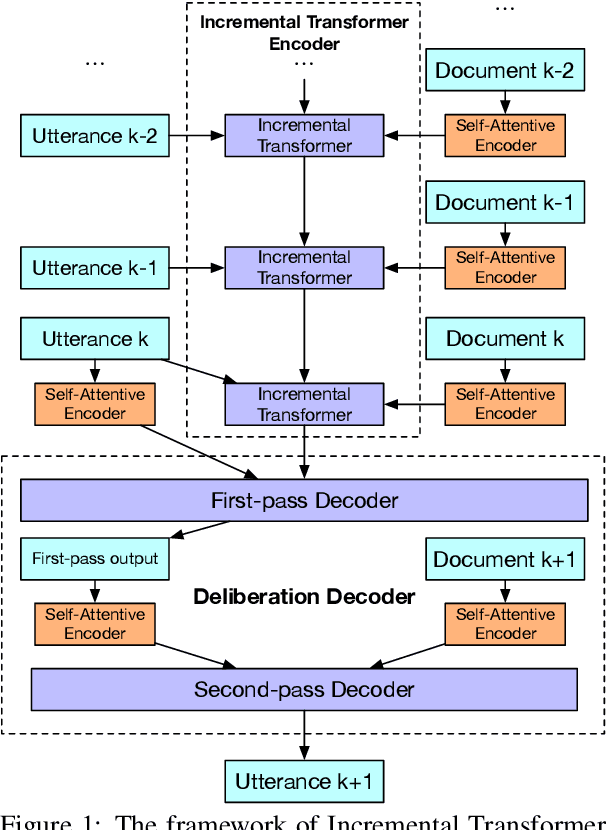
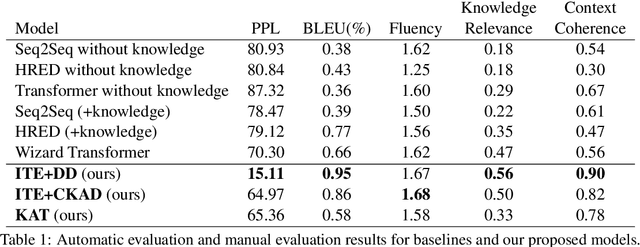
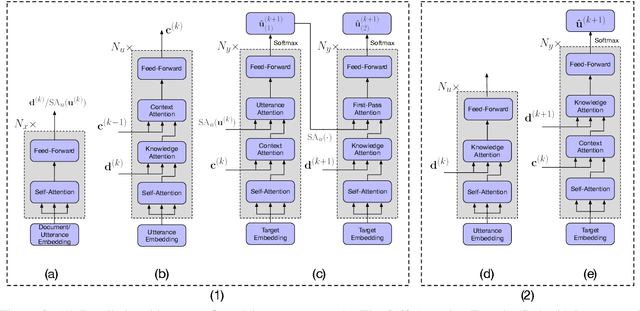
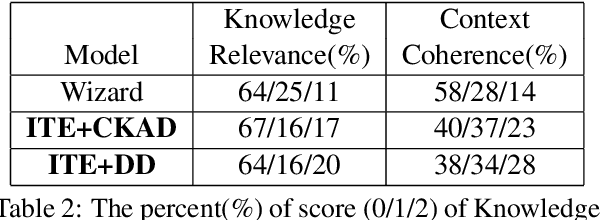
Document Grounded Conversations is a task to generate dialogue responses when chatting about the content of a given document. Obviously, document knowledge plays a critical role in Document Grounded Conversations, while existing dialogue models do not exploit this kind of knowledge effectively enough. In this paper, we propose a novel Transformer-based architecture for multi-turn document grounded conversations. In particular, we devise an Incremental Transformer to encode multi-turn utterances along with knowledge in related documents. Motivated by the human cognitive process, we design a two-pass decoder (Deliberation Decoder) to improve context coherence and knowledge correctness. Our empirical study on a real-world Document Grounded Dataset proves that responses generated by our model significantly outperform competitive baselines on both context coherence and knowledge relevance.