 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangevin Diffusion Approximation to Same Marginal Schrödinger Bridge
May 12, 2025We introduce a novel approximation to the same marginal Schr\"{o}dinger bridge using the Langevin diffusion. As $\varepsilon \downarrow 0$, it is known that the barycentric projection (also known as the entropic Brenier map) of the Schr\"{o}dinger bridge converges to the Brenier map, which is the identity. Our diffusion approximation is leveraged to show that, under suitable assumptions, the difference between the two is $\varepsilon$ times the gradient of the marginal log density (i.e., the score function), in $\mathbf{L}^2$. More generally, we show that the family of Markov operators, indexed by $\varepsilon > 0$, derived from integrating test functions against the conditional density of the static Schr\"{o}dinger bridge at temperature $\varepsilon$, admits a derivative at $\varepsilon=0$ given by the generator of the Langevin semigroup. Hence, these operators satisfy an approximate semigroup property at low temperatures.
Spectral Differential Network Analysis for High-Dimensional Time Series
Dec 10, 2024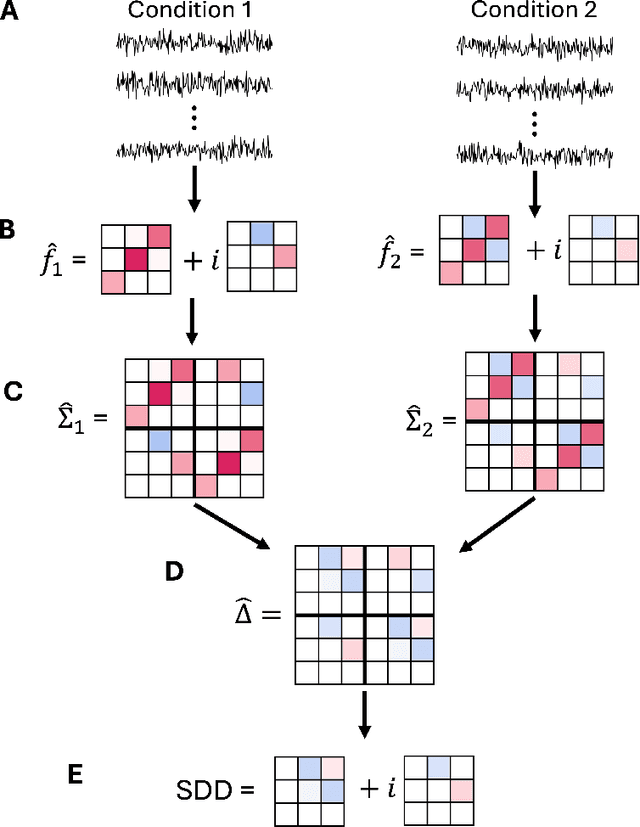
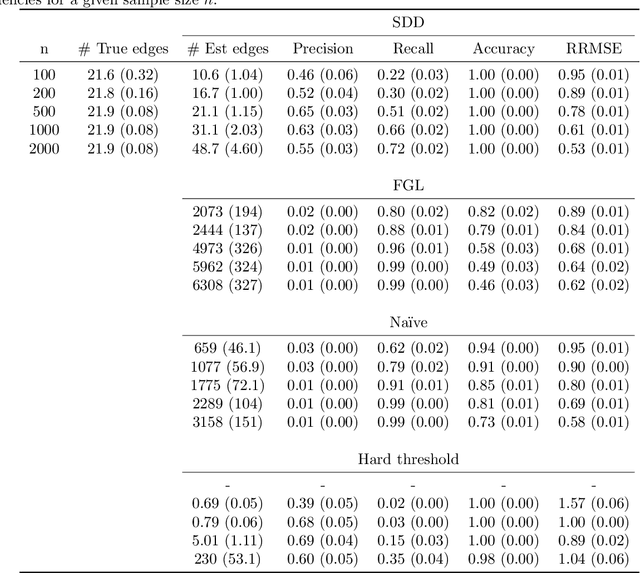
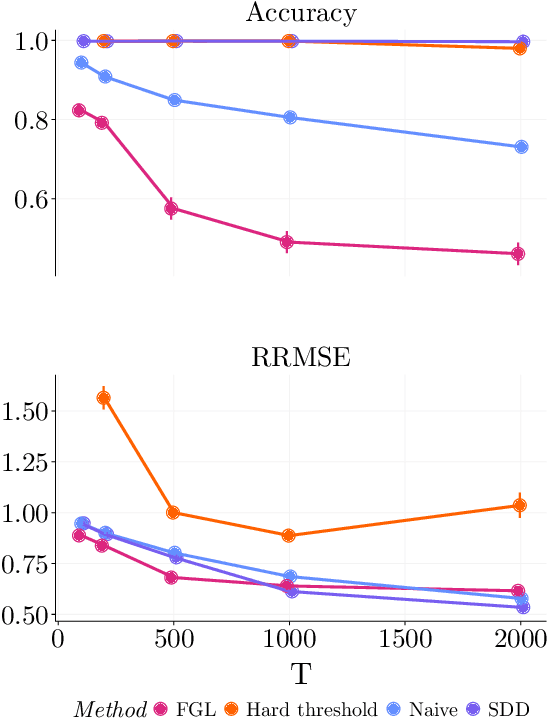
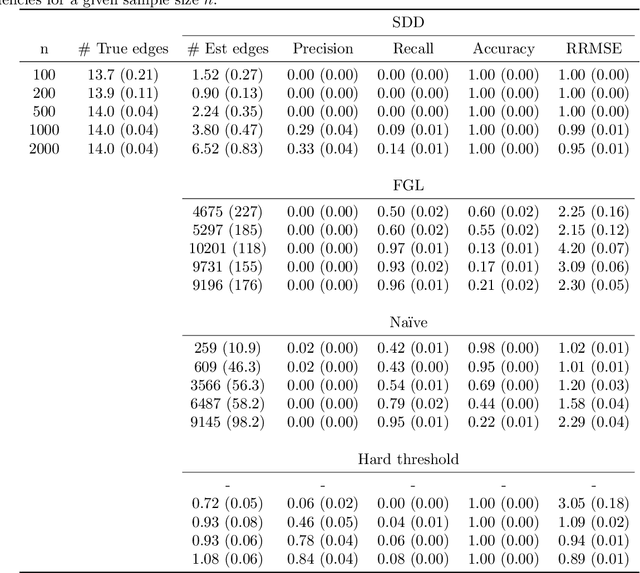
Spectral networks derived from multivariate time series data arise in many domains, from brain science to Earth science. Often, it is of interest to study how these networks change under different conditions. For instance, to better understand epilepsy, it would be interesting to capture the changes in the brain connectivity network as a patient experiences a seizure, using electroencephalography data. A common approach relies on estimating the networks in each condition and calculating their difference. Such estimates may behave poorly in high dimensions as the networks themselves may not be sparse in structure while their difference may be. We build upon this observation to develop an estimator of the difference in inverse spectral densities across two conditions. Using an L1 penalty on the difference, consistency is established by only requiring the difference to be sparse. We illustrate the method on synthetic data experiments, on experiments with electroencephalography data, and on experiments with optogentic stimulation and micro-electrocorticography data.
StyleRemix: Interpretable Authorship Obfuscation via Distillation and Perturbation of Style Elements
Aug 28, 2024



Authorship obfuscation, rewriting a text to intentionally obscure the identity of the author, is an important but challenging task. Current methods using large language models (LLMs) lack interpretability and controllability, often ignoring author-specific stylistic features, resulting in less robust performance overall. To address this, we develop StyleRemix, an adaptive and interpretable obfuscation method that perturbs specific, fine-grained style elements of the original input text. StyleRemix uses pre-trained Low Rank Adaptation (LoRA) modules to rewrite an input specifically along various stylistic axes (e.g., formality and length) while maintaining low computational cost. StyleRemix outperforms state-of-the-art baselines and much larger LLMs in a variety of domains as assessed by both automatic and human evaluation. Additionally, we release AuthorMix, a large set of 30K high-quality, long-form texts from a diverse set of 14 authors and 4 domains, and DiSC, a parallel corpus of 1,500 texts spanning seven style axes in 16 unique directions
The Benefits of Balance: From Information Projections to Variance Reduction
Aug 27, 2024



Data balancing across multiple modalities/sources appears in various forms in several foundation models (e.g., CLIP and DINO) achieving universal representation learning. We show that this iterative algorithm, usually used to avoid representation collapse, enjoys an unsuspected benefit: reducing the variance of estimators that are functionals of the empirical distribution over these sources. We provide non-asymptotic bounds quantifying this variance reduction effect and relate them to the eigendecays of appropriately defined Markov operators. We explain how various forms of data balancing in contrastive multimodal learning and self-supervised clustering can be interpreted as instances of this variance reduction scheme.
From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models
Jun 24, 2024One of the most striking findings in modern research on large language models (LLMs) is that scaling up compute during training leads to better results. However, less attention has been given to the benefits of scaling compute during inference. This survey focuses on these inference-time approaches. We explore three areas under a unified mathematical formalism: token-level generation algorithms, meta-generation algorithms, and efficient generation. Token-level generation algorithms, often called decoding algorithms, operate by sampling a single token at a time or constructing a token-level search space and then selecting an output. These methods typically assume access to a language model's logits, next-token distributions, or probability scores. Meta-generation algorithms work on partial or full sequences, incorporating domain knowledge, enabling backtracking, and integrating external information. Efficient generation methods aim to reduce token costs and improve the speed of generation. Our survey unifies perspectives from three research communities: traditional natural language processing, modern LLMs, and machine learning systems.
Iterated Schrödinger bridge approximation to Wasserstein Gradient Flows
Jun 16, 2024
We introduce a novel discretization scheme for Wasserstein gradient flows that involves successively computing Schr\"{o}dinger bridges with the same marginals. This is different from both the forward/geodesic approximation and the backward/Jordan-Kinderlehrer-Otto (JKO) approximations. The proposed scheme has two advantages: one, it avoids the use of the score function, and, two, it is amenable to particle-based approximations using the Sinkhorn algorithm. Our proof hinges upon showing that relative entropy between the Schr\"{o}dinger bridge with the same marginals at temperature $\epsilon$ and the joint distribution of a stationary Langevin diffusion at times zero and $\epsilon$ is of the order $o(\epsilon^2)$ with an explicit dependence given by Fisher information. Owing to this inequality, we can show, using a triangular approximation argument, that the interpolated iterated application of the Schr\"{o}dinger bridge approximation converge to the Wasserstein gradient flow, for a class of gradient flows, including the heat flow. The results also provide a probabilistic and rigorous framework for the convergence of the self-attention mechanisms in transformer networks to the solutions of heat flows, first observed in the inspiring work SABP22 in machine learning research.
A Primal-Dual Algorithm for Faster Distributionally Robust Optimization
Mar 16, 2024



We consider the penalized distributionally robust optimization (DRO) problem with a closed, convex uncertainty set, a setting that encompasses the $f$-DRO, Wasserstein-DRO, and spectral/$L$-risk formulations used in practice. We present Drago, a stochastic primal-dual algorithm that achieves a state-of-the-art linear convergence rate on strongly convex-strongly concave DRO problems. The method combines both randomized and cyclic components with mini-batching, which effectively handles the unique asymmetric nature of the primal and dual problems in DRO. We support our theoretical results with numerical benchmarks in classification and regression.
JAMDEC: Unsupervised Authorship Obfuscation using Constrained Decoding over Small Language Models
Feb 13, 2024



The permanence of online content combined with the enhanced authorship identification techniques calls for stronger computational methods to protect the identity and privacy of online authorship when needed, e.g., blind reviews for scientific papers, anonymous online reviews, or anonymous interactions in the mental health forums. In this paper, we propose an unsupervised inference-time approach to authorship obfuscation to address the unique challenges of authorship obfuscation: lack of supervision data for diverse authorship and domains, and the need for a sufficient level of revision beyond simple paraphrasing to obfuscate the authorship, all the while preserving the original content and fluency. We introduce JAMDEC, a user-controlled, inference-time algorithm for authorship obfuscation that can be in principle applied to any text and authorship. Our approach builds on small language models such as GPT2-XL in order to help avoid disclosing the original content to proprietary LLM's APIs, while also reducing the performance gap between small and large language models via algorithmic enhancement. The key idea behind our approach is to boost the creative power of smaller language models through constrained decoding, while also allowing for user-specified controls and flexibility. Experimental results demonstrate that our approach based on GPT2-XL outperforms previous state-of-the-art methods based on comparably small models, while performing competitively against GPT3.5 175B, a propriety model that is two orders of magnitudes larger.
Distributionally Robust Optimization with Bias and Variance Reduction
Oct 21, 2023



We consider the distributionally robust optimization (DRO) problem with spectral risk-based uncertainty set and $f$-divergence penalty. This formulation includes common risk-sensitive learning objectives such as regularized condition value-at-risk (CVaR) and average top-$k$ loss. We present Prospect, a stochastic gradient-based algorithm that only requires tuning a single learning rate hyperparameter, and prove that it enjoys linear convergence for smooth regularized losses. This contrasts with previous algorithms that either require tuning multiple hyperparameters or potentially fail to converge due to biased gradient estimates or inadequate regularization. Empirically, we show that Prospect can converge 2-3$\times$ faster than baselines such as stochastic gradient and stochastic saddle-point methods on distribution shift and fairness benchmarks spanning tabular, vision, and language domains.
FiLM: Fill-in Language Models for Any-Order Generation
Oct 15, 2023



Language models have become the backbone of today's AI systems. However, their predominant left-to-right generation limits the use of bidirectional context, which is essential for tasks that involve filling text in the middle. We propose the Fill-in Language Model (FiLM), a new language modeling approach that allows for flexible generation at any position without adhering to a specific generation order. Its training extends the masked language modeling objective by adopting varying mask probabilities sampled from the Beta distribution to enhance the generative capabilities of FiLM. During inference, FiLM can seamlessly insert missing phrases, sentences, or paragraphs, ensuring that the outputs are fluent and are coherent with the surrounding context. In both automatic and human evaluations, FiLM outperforms existing infilling methods that rely on left-to-right language models trained on rearranged text segments. FiLM is easy to implement and can be either trained from scratch or fine-tuned from a left-to-right language model. Notably, as the model size grows, FiLM's perplexity approaches that of strong left-to-right language models of similar sizes, indicating FiLM's scalability and potential as a large language model.