 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Features of Music from Scratch
Apr 06, 2017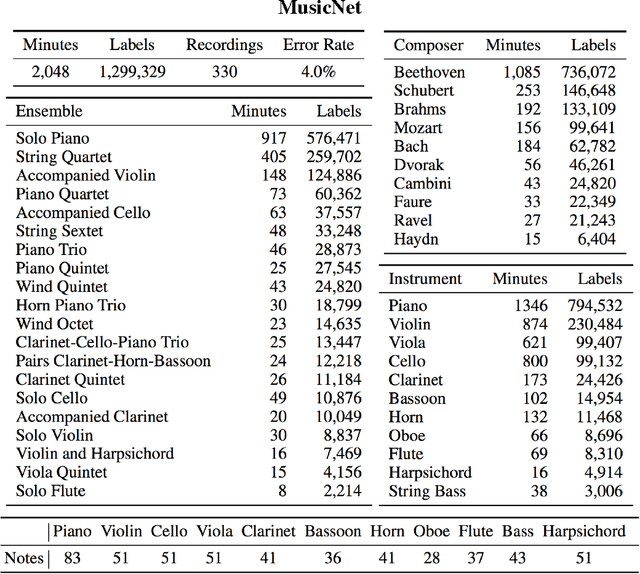
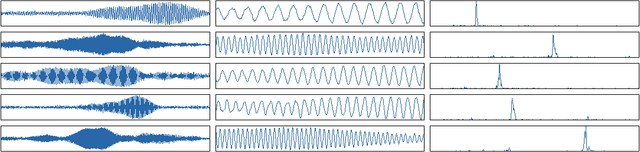
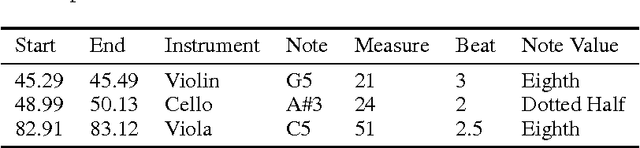
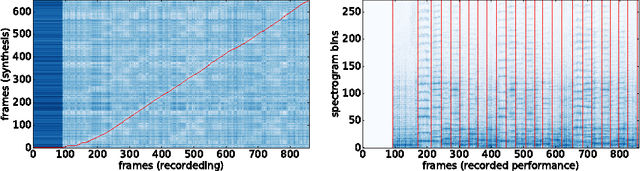
This paper introduces a new large-scale music dataset, MusicNet, to serve as a source of supervision and evaluation of machine learning methods for music research. MusicNet consists of hundreds of freely-licensed classical music recordings by 10 composers, written for 11 instruments, together with instrument/note annotations resulting in over 1 million temporal labels on 34 hours of chamber music performances under various studio and microphone conditions. The paper defines a multi-label classification task to predict notes in musical recordings, along with an evaluation protocol, and benchmarks several machine learning architectures for this task: i) learning from spectrogram features; ii) end-to-end learning with a neural net; iii) end-to-end learning with a convolutional neural net. These experiments show that end-to-end models trained for note prediction learn frequency selective filters as a low-level representation of audio.
Fast and Simple Optimization for Poisson Likelihood Models
Aug 03, 2016
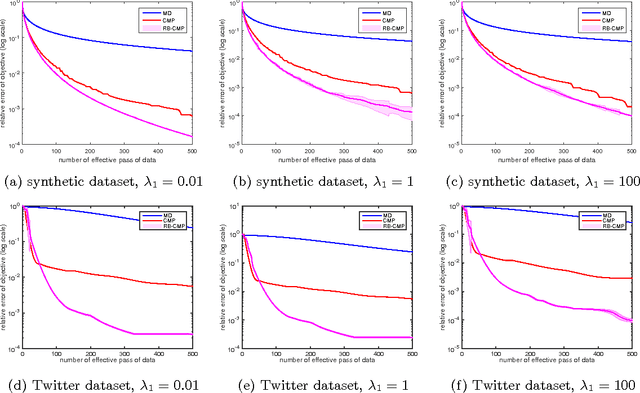
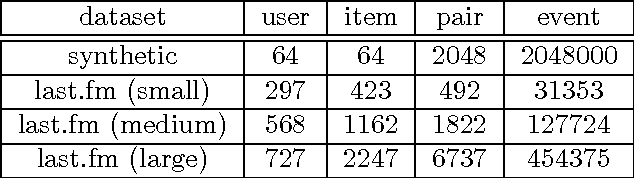
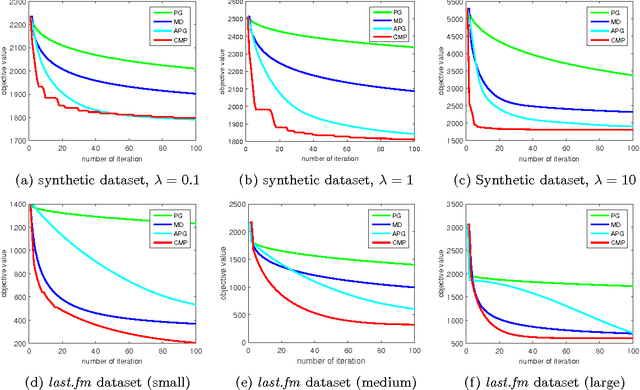
Poisson likelihood models have been prevalently used in imaging, social networks, and time series analysis. We propose fast, simple, theoretically-grounded, and versatile, optimization algorithms for Poisson likelihood modeling. The Poisson log-likelihood is concave but not Lipschitz-continuous. Since almost all gradient-based optimization algorithms rely on Lipschitz-continuity, optimizing Poisson likelihood models with a guarantee of convergence can be challenging, especially for large-scale problems. We present a new perspective allowing to efficiently optimize a wide range of penalized Poisson likelihood objectives. We show that an appropriate saddle point reformulation enjoys a favorable geometry and a smooth structure. Therefore, we can design a new gradient-based optimization algorithm with $O(1/t)$ convergence rate, in contrast to the usual $O(1/\sqrt{t})$ rate of non-smooth minimization alternatives. Furthermore, in order to tackle problems with large samples, we also develop a randomized block-decomposition variant that enjoys the same convergence rate yet more efficient iteration cost. Experimental results on several point process applications including social network estimation and temporal recommendation show that the proposed algorithm and its randomized block variant outperform existing methods both on synthetic and real-world datasets.
Convolutional Patch Representations for Image Retrieval: an Unsupervised Approach
Mar 01, 2016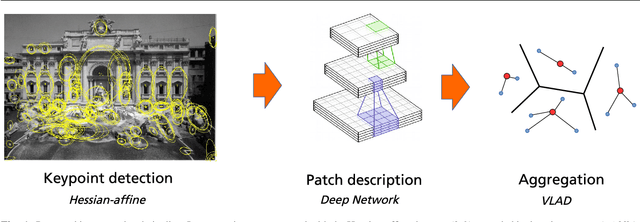

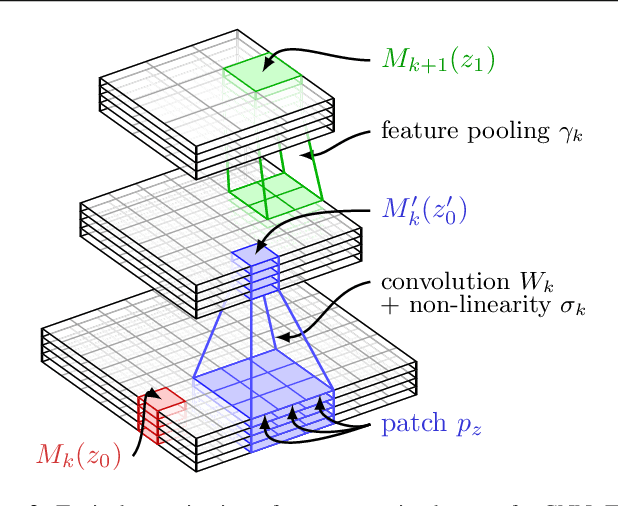
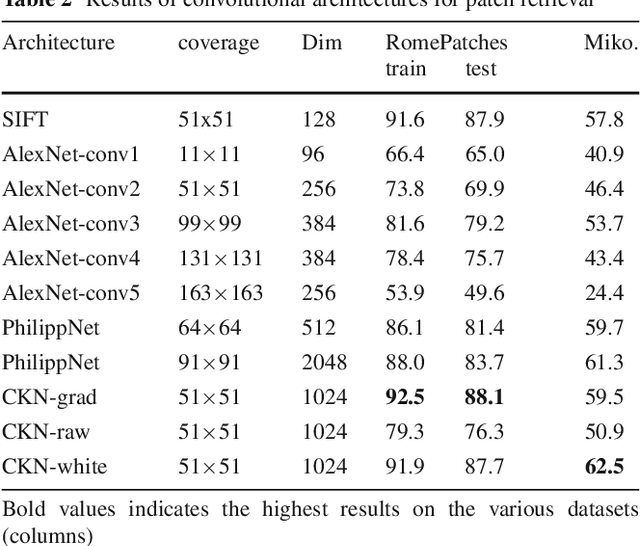
Convolutional neural networks (CNNs) have recently received a lot of attention due to their ability to model local stationary structures in natural images in a multi-scale fashion, when learning all model parameters with supervision. While excellent performance was achieved for image classification when large amounts of labeled visual data are available, their success for un-supervised tasks such as image retrieval has been moderate so far. Our paper focuses on this latter setting and explores several methods for learning patch descriptors without supervision with application to matching and instance-level retrieval. To that effect, we propose a new family of convolutional descriptors for patch representation , based on the recently introduced convolutional kernel networks. We show that our descriptor, named Patch-CKN, performs better than SIFT as well as other convolutional networks learned by artificially introducing supervision and is significantly faster to train. To demonstrate its effectiveness, we perform an extensive evaluation on standard benchmarks for patch and image retrieval where we obtain state-of-the-art results. We also introduce a new dataset called RomePatches, which allows to simultaneously study descriptor performance for patch and image retrieval.
DeepMatching: Hierarchical Deformable Dense Matching
Oct 08, 2015
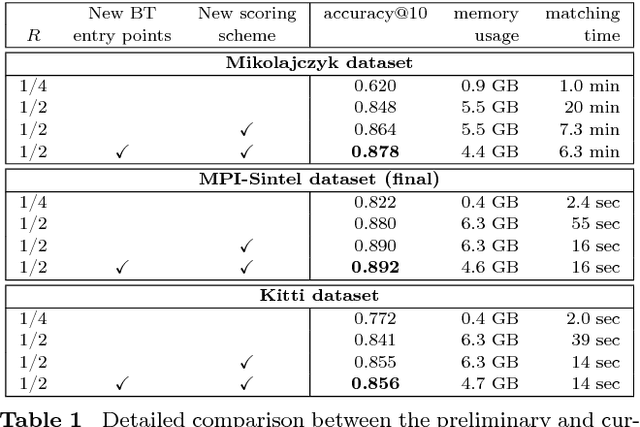
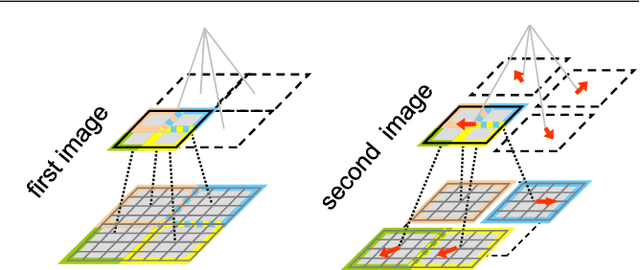

We introduce a novel matching algorithm, called DeepMatching, to compute dense correspondences between images. DeepMatching relies on a hierarchical, multi-layer, correlational architecture designed for matching images and was inspired by deep convolutional approaches. The proposed matching algorithm can handle non-rigid deformations and repetitive textures and efficiently determines dense correspondences in the presence of significant changes between images. We evaluate the performance of DeepMatching, in comparison with state-of-the-art matching algorithms, on the Mikolajczyk (Mikolajczyk et al 2005), the MPI-Sintel (Butler et al 2012) and the Kitti (Geiger et al 2013) datasets. DeepMatching outperforms the state-of-the-art algorithms and shows excellent results in particular for repetitive textures.We also propose a method for estimating optical flow, called DeepFlow, by integrating DeepMatching in the large displacement optical flow (LDOF) approach of Brox and Malik (2011). Compared to existing matching algorithms, additional robustness to large displacements and complex motion is obtained thanks to our matching approach. DeepFlow obtains competitive performance on public benchmarks for optical flow estimation.
Label-Embedding for Image Classification
Oct 01, 2015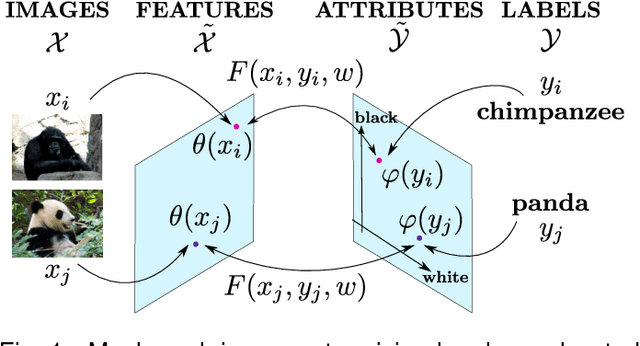
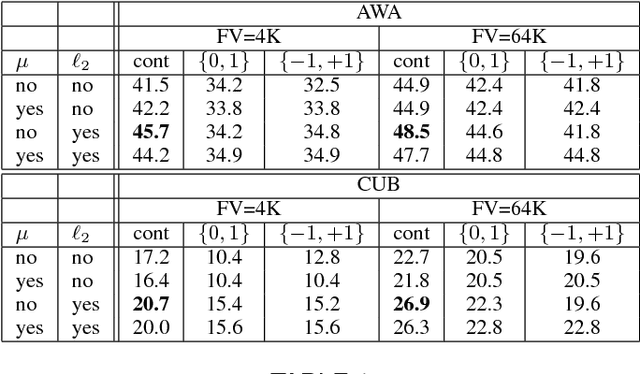
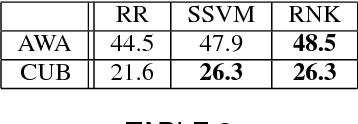
Attributes act as intermediate representations that enable parameter sharing between classes, a must when training data is scarce. We propose to view attribute-based image classification as a label-embedding problem: each class is embedded in the space of attribute vectors. We introduce a function that measures the compatibility between an image and a label embedding. The parameters of this function are learned on a training set of labeled samples to ensure that, given an image, the correct classes rank higher than the incorrect ones. Results on the Animals With Attributes and Caltech-UCSD-Birds datasets show that the proposed framework outperforms the standard Direct Attribute Prediction baseline in a zero-shot learning scenario. Label embedding enjoys a built-in ability to leverage alternative sources of information instead of or in addition to attributes, such as e.g. class hierarchies or textual descriptions. Moreover, label embedding encompasses the whole range of learning settings from zero-shot learning to regular learning with a large number of labeled examples.
Learning to track for spatio-temporal action localization
Sep 27, 2015
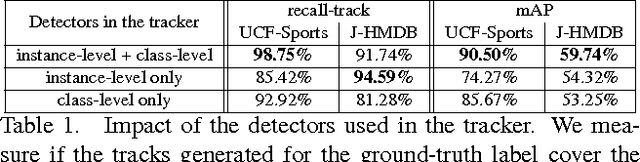
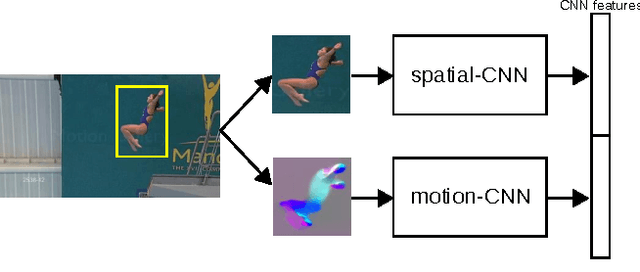
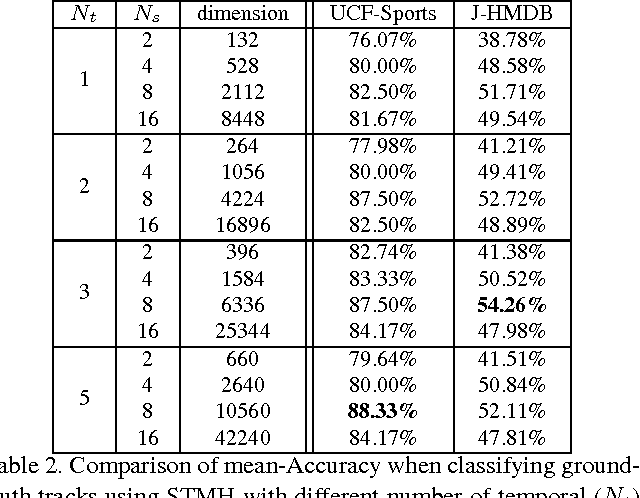
We propose an effective approach for spatio-temporal action localization in realistic videos. The approach first detects proposals at the frame-level and scores them with a combination of static and motion CNN features. It then tracks high-scoring proposals throughout the video using a tracking-by-detection approach. Our tracker relies simultaneously on instance-level and class-level detectors. The tracks are scored using a spatio-temporal motion histogram, a descriptor at the track level, in combination with the CNN features. Finally, we perform temporal localization of the action using a sliding-window approach at the track level. We present experimental results for spatio-temporal localization on the UCF-Sports, J-HMDB and UCF-101 action localization datasets, where our approach outperforms the state of the art with a margin of 15%, 7% and 12% respectively in mAP.
Beat-Event Detection in Action Movie Franchises
Aug 15, 2015
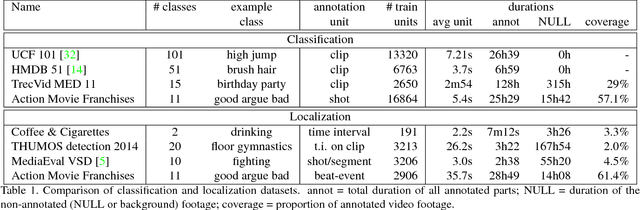
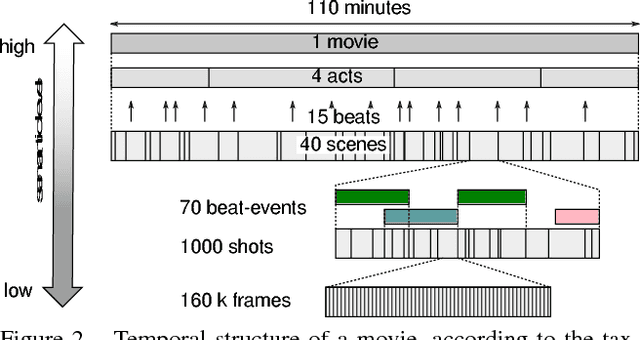
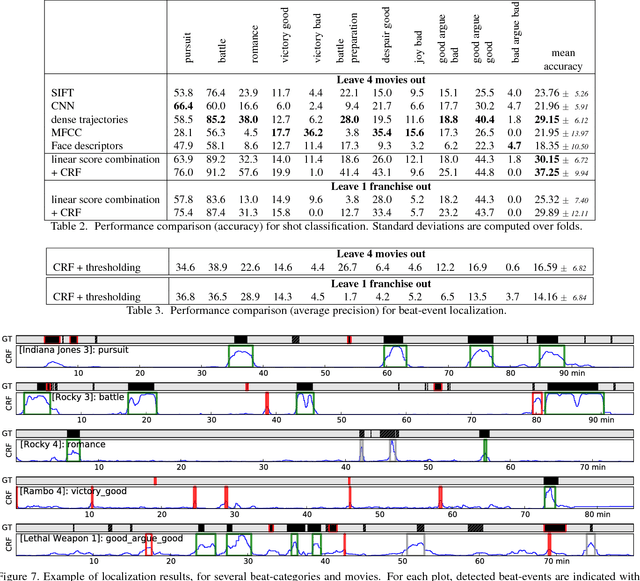
While important advances were recently made towards temporally localizing and recognizing specific human actions or activities in videos, efficient detection and classification of long video chunks belonging to semantically defined categories such as "pursuit" or "romance" remains challenging.We introduce a new dataset, Action Movie Franchises, consisting of a collection of Hollywood action movie franchises. We define 11 non-exclusive semantic categories - called beat-categories - that are broad enough to cover most of the movie footage. The corresponding beat-events are annotated as groups of video shots, possibly overlapping.We propose an approach for localizing beat-events based on classifying shots into beat-categories and learning the temporal constraints between shots. We show that temporal constraints significantly improve the classification performance. We set up an evaluation protocol for beat-event localization as well as for shot classification, depending on whether movies from the same franchise are present or not in the training data.
Semi-proximal Mirror-Prox for Nonsmooth Composite Minimization
Jul 06, 2015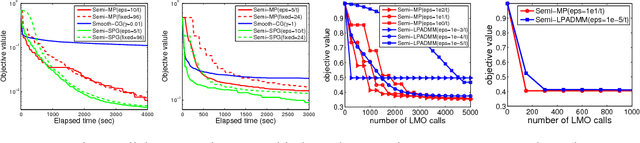
We propose a new first-order optimisation algorithm to solve high-dimensional non-smooth composite minimisation problems. Typical examples of such problems have an objective that decomposes into a non-smooth empirical risk part and a non-smooth regularisation penalty. The proposed algorithm, called Semi-Proximal Mirror-Prox, leverages the Fenchel-type representation of one part of the objective while handling the other part of the objective via linear minimization over the domain. The algorithm stands in contrast with more classical proximal gradient algorithms with smoothing, which require the computation of proximal operators at each iteration and can therefore be impractical for high-dimensional problems. We establish the theoretical convergence rate of Semi-Proximal Mirror-Prox, which exhibits the optimal complexity bounds, i.e. $O(1/\epsilon^2)$, for the number of calls to linear minimization oracle. We present promising experimental results showing the interest of the approach in comparison to competing methods.
EpicFlow: Edge-Preserving Interpolation of Correspondences for Optical Flow
May 19, 2015
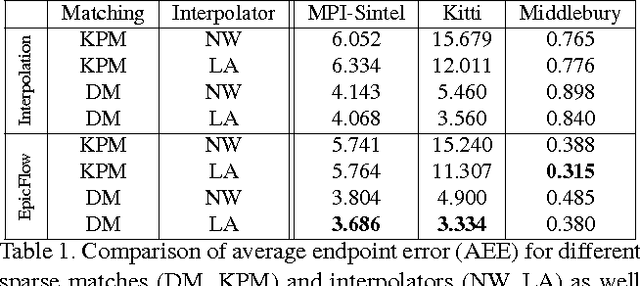

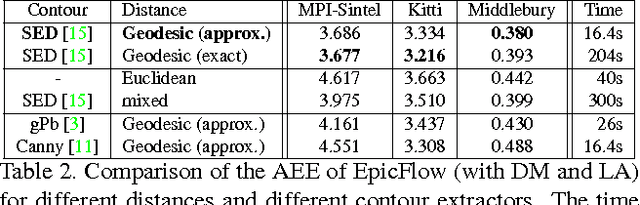
We propose a novel approach for optical flow estimation , targeted at large displacements with significant oc-clusions. It consists of two steps: i) dense matching by edge-preserving interpolation from a sparse set of matches; ii) variational energy minimization initialized with the dense matches. The sparse-to-dense interpolation relies on an appropriate choice of the distance, namely an edge-aware geodesic distance. This distance is tailored to handle occlusions and motion boundaries -- two common and difficult issues for optical flow computation. We also propose an approximation scheme for the geodesic distance to allow fast computation without loss of performance. Subsequent to the dense interpolation step, standard one-level variational energy minimization is carried out on the dense matches to obtain the final flow estimation. The proposed approach, called Edge-Preserving Interpolation of Correspondences (EpicFlow) is fast and robust to large displacements. It significantly outperforms the state of the art on MPI-Sintel and performs on par on Kitti and Middlebury.
Convolutional Kernel Networks
Nov 14, 2014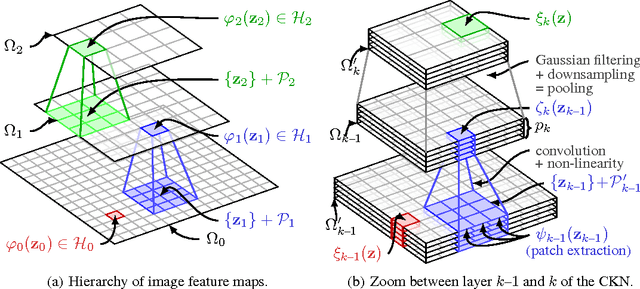
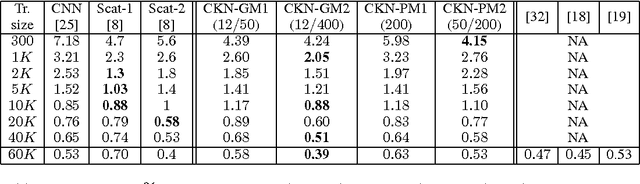
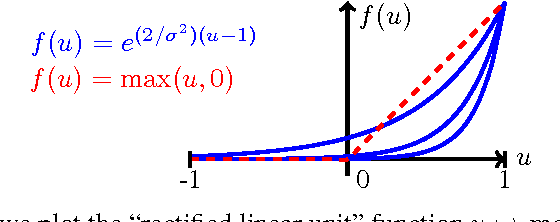

An important goal in visual recognition is to devise image representations that are invariant to particular transformations. In this paper, we address this goal with a new type of convolutional neural network (CNN) whose invariance is encoded by a reproducing kernel. Unlike traditional approaches where neural networks are learned either to represent data or for solving a classification task, our network learns to approximate the kernel feature map on training data. Such an approach enjoys several benefits over classical ones. First, by teaching CNNs to be invariant, we obtain simple network architectures that achieve a similar accuracy to more complex ones, while being easy to train and robust to overfitting. Second, we bridge a gap between the neural network literature and kernels, which are natural tools to model invariance. We evaluate our methodology on visual recognition tasks where CNNs have proven to perform well, e.g., digit recognition with the MNIST dataset, and the more challenging CIFAR-10 and STL-10 datasets, where our accuracy is competitive with the state of the art.