 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoBot: Transfer and Exploration via the Information Bottleneck
Apr 04, 2019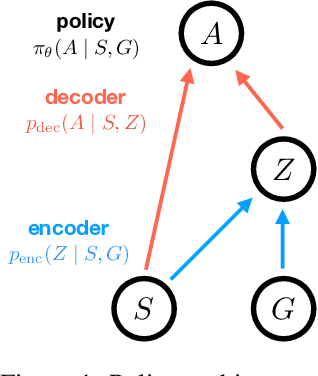



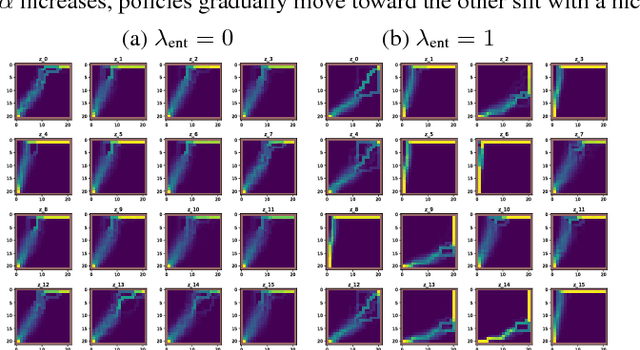
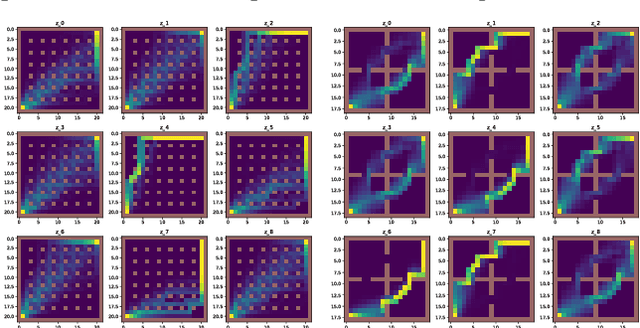
A central challenge in reinforcement learning is discovering effective policies for tasks where rewards are sparsely distributed. We postulate that in the absence of useful reward signals, an effective exploration strategy should seek out {\it decision states}. These states lie at critical junctions in the state space from where the agent can transition to new, potentially unexplored regions. We propose to learn about decision states from prior experience. By training a goal-conditioned policy with an information bottleneck, we can identify decision states by examining where the model actually leverages the goal state. We find that this simple mechanism effectively identifies decision states, even in partially observed settings. In effect, the model learns the sensory cues that correlate with potential subgoals. In new environments, this model can then identify novel subgoals for further exploration, guiding the agent through a sequence of potential decision states and through new regions of the state space.
Understanding the impact of entropy on policy optimization
Nov 29, 2018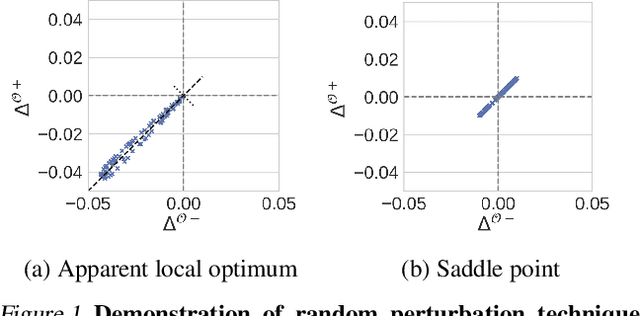
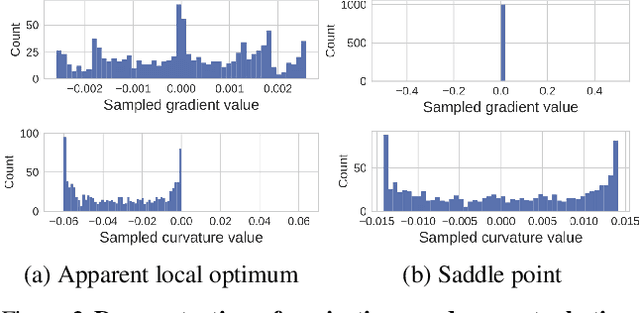
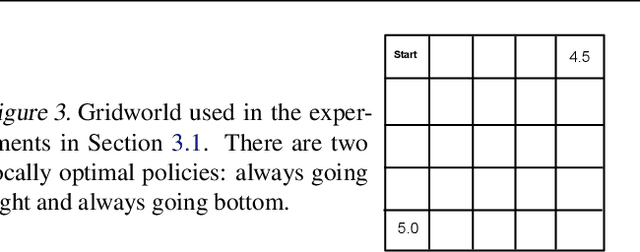
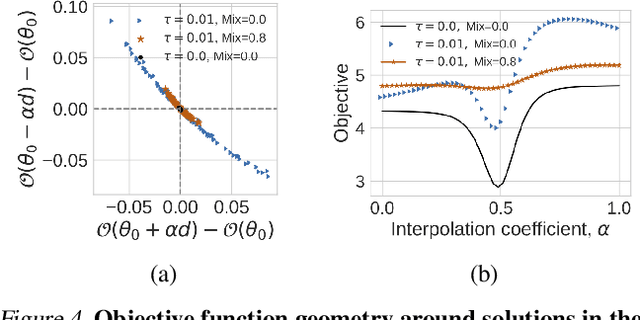
Entropy regularization is commonly used to improve policy optimization in reinforcement learning. It is believed to help with exploration by encouraging the selection of more stochastic policies. In this work, we analyze this claim and, through new visualizations of the optimization landscape, we observe that incorporating entropy in policy optimization serves as a regularizer. We show that even with access to the exact gradient, policy optimization is difficult due to the geometry of the objective function. We qualitatively show that, in some environments, entropy regularization can make the optimization landscape smoother, thereby connecting local optima and enabling the use of larger learning rates. This manuscript presents new tools for understanding the underlying optimization landscape and highlights the challenge of designing general-purpose policy optimization algorithms in reinforcement learning.
VFunc: a Deep Generative Model for Functions
Jul 11, 2018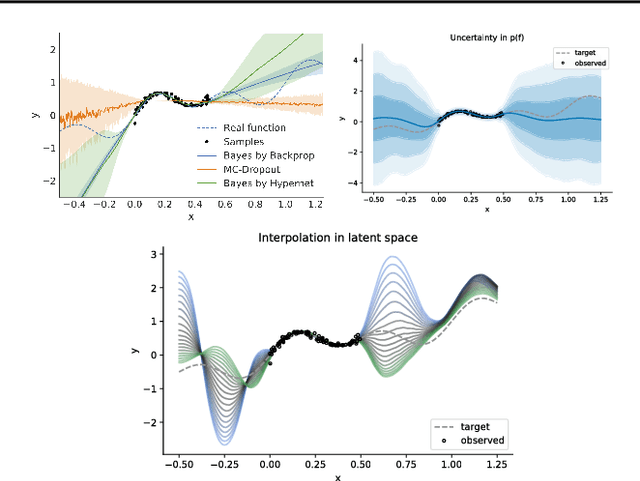

We introduce a deep generative model for functions. Our model provides a joint distribution p(f, z) over functions f and latent variables z which lets us efficiently sample from the marginal p(f) and maximize a variational lower bound on the entropy H(f). We can thus maximize objectives of the form E_{f~p(f)}[R(f)] + c*H(f), where R(f) denotes, e.g., a data log-likelihood term or an expected reward. Such objectives encompass Bayesian deep learning in function space, rather than parameter space, and Bayesian deep RL with representations of uncertainty that offer benefits over bootstrapping and parameter noise. In this short paper we describe our model, situate it in the context of prior work, and present proof-of-concept experiments for regression and RL.