 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Enhanced 7-Point Checklist for Melanoma Detection Using Clinical Knowledge Graphs and Data-Driven Quantification
Jul 23, 2024



The 7-point checklist (7PCL) is widely used in dermoscopy to identify malignant melanoma lesions needing urgent medical attention. It assigns point values to seven attributes: major attributes are worth two points each, and minor ones are worth one point each. A total score of three or higher prompts further evaluation, often including a biopsy. However, a significant limitation of current methods is the uniform weighting of attributes, which leads to imprecision and neglects their interconnections. Previous deep learning studies have treated the prediction of each attribute with the same importance as predicting melanoma, which fails to recognize the clinical significance of the attributes for melanoma. To address these limitations, we introduce a novel diagnostic method that integrates two innovative elements: a Clinical Knowledge-Based Topological Graph (CKTG) and a Gradient Diagnostic Strategy with Data-Driven Weighting Standards (GD-DDW). The CKTG integrates 7PCL attributes with diagnostic information, revealing both internal and external associations. By employing adaptive receptive domains and weighted edges, we establish connections among melanoma's relevant features. Concurrently, GD-DDW emulates dermatologists' diagnostic processes, who first observe the visual characteristics associated with melanoma and then make predictions. Our model uses two imaging modalities for the same lesion, ensuring comprehensive feature acquisition. Our method shows outstanding performance in predicting malignant melanoma and its features, achieving an average AUC value of 85%. This was validated on the EDRA dataset, the largest publicly available dataset for the 7-point checklist algorithm. Specifically, the integrated weighting system can provide clinicians with valuable data-driven benchmarks for their evaluations.
ESCAPE: Energy-based Selective Adaptive Correction for Out-of-distribution 3D Human Pose Estimation
Jul 19, 2024



Despite recent advances in human pose estimation (HPE), poor generalization to out-of-distribution (OOD) data remains a difficult problem. While previous works have proposed Test-Time Adaptation (TTA) to bridge the train-test domain gap by refining network parameters at inference, the absence of ground-truth annotations makes it highly challenging and existing methods typically increase inference times by one or more orders of magnitude. We observe that 1) not every test time sample is OOD, and 2) HPE errors are significantly larger on distal keypoints (wrist, ankle). To this end, we propose ESCAPE: a lightweight correction and selective adaptation framework which applies a fast, forward-pass correction on most data while reserving costly TTA for OOD data. The free energy function is introduced to separate OOD samples from incoming data and a correction network is trained to estimate the errors of pretrained backbone HPE predictions on the distal keypoints. For OOD samples, we propose a novel self-consistency adaptation loss to update the correction network by leveraging the constraining relationship between distal keypoints and proximal keypoints (shoulders, hips), via a second ``reverse" network. ESCAPE improves the distal MPJPE of five popular HPE models by up to 7% on unseen data, achieves state-of-the-art results on two popular HPE benchmarks, and is significantly faster than existing adaptation methods.
CCDM: Continuous Conditional Diffusion Models for Image Generation
May 06, 2024



Continuous Conditional Generative Modeling (CCGM) aims to estimate the distribution of high-dimensional data, typically images, conditioned on scalar continuous variables known as regression labels. While Continuous conditional Generative Adversarial Networks (CcGANs) were initially designed for this task, their adversarial training mechanism remains vulnerable to extremely sparse or imbalanced data, resulting in suboptimal outcomes. To enhance the quality of generated images, a promising alternative is to replace CcGANs with Conditional Diffusion Models (CDMs), renowned for their stable training process and ability to produce more realistic images. However, existing CDMs encounter challenges when applied to CCGM tasks due to several limitations such as inadequate U-Net architectures and deficient model fitting mechanisms for handling regression labels. In this paper, we introduce Continuous Conditional Diffusion Models (CCDMs), the first CDM designed specifically for the CCGM task. CCDMs address the limitations of existing CDMs by introducing specially designed conditional diffusion processes, a modified denoising U-Net with a custom-made conditioning mechanism, a novel hard vicinal loss for model fitting, and an efficient conditional sampling procedure. With comprehensive experiments on four datasets with varying resolutions ranging from 64x64 to 192x192, we demonstrate the superiority of the proposed CCDM over state-of-the-art CCGM models, establishing new benchmarks in CCGM. Extensive ablation studies validate the model design and implementation configuration of the proposed CCDM. Our code is publicly available at https://github.com/UBCDingXin/CCDM.
GOLD: Generalized Knowledge Distillation via Out-of-Distribution-Guided Language Data Generation
Mar 28, 2024



Knowledge distillation from LLMs is essential for the efficient deployment of language models. Prior works have proposed data generation using LLMs for preparing distilled models. We argue that generating data with LLMs is prone to sampling mainly from the center of original content distribution. This limitation hinders the distilled model from learning the true underlying data distribution and to forget the tails of the distributions (samples with lower probability). To this end, we propose GOLD, a task-agnostic data generation and knowledge distillation framework, which employs an iterative out-of-distribution-guided feedback mechanism for the LLM. As a result, the generated data improves the generalizability of distilled models. An energy-based OOD evaluation approach is also introduced to deal with noisy generated data. Our extensive experiments on 10 different classification and sequence-to-sequence tasks in NLP show that GOLD respectively outperforms prior arts and the LLM with an average improvement of 5% and 14%. We will also show that the proposed method is applicable to less explored and novel tasks. The code is available.
PoseGen: Learning to Generate 3D Human Pose Dataset with NeRF
Dec 22, 2023This paper proposes an end-to-end framework for generating 3D human pose datasets using Neural Radiance Fields (NeRF). Public datasets generally have limited diversity in terms of human poses and camera viewpoints, largely due to the resource-intensive nature of collecting 3D human pose data. As a result, pose estimators trained on public datasets significantly underperform when applied to unseen out-of-distribution samples. Previous works proposed augmenting public datasets by generating 2D-3D pose pairs or rendering a large amount of random data. Such approaches either overlook image rendering or result in suboptimal datasets for pre-trained models. Here we propose PoseGen, which learns to generate a dataset (human 3D poses and images) with a feedback loss from a given pre-trained pose estimator. In contrast to prior art, our generated data is optimized to improve the robustness of the pre-trained model. The objective of PoseGen is to learn a distribution of data that maximizes the prediction error of a given pre-trained model. As the learned data distribution contains OOD samples of the pre-trained model, sampling data from such a distribution for further fine-tuning a pre-trained model improves the generalizability of the model. This is the first work that proposes NeRFs for 3D human data generation. NeRFs are data-driven and do not require 3D scans of humans. Therefore, using NeRF for data generation is a new direction for convenient user-specific data generation. Our extensive experiments show that the proposed PoseGen improves two baseline models (SPIN and HybrIK) on four datasets with an average 6% relative improvement.
Optimal Time of Arrival Estimation for MIMO Backscatter Channels
Nov 22, 2023In this paper, we propose a novel time of arrival (TOA) estimator for multiple-input-multiple-output (MIMO) backscatter channels in closed form. The proposed estimator refines the estimation precision from the topological structure of the MIMO backscatter channels, and can considerably enhance the estimation accuracy. Particularly, we show that for the general $M \times N$ bistatic topology, the mean square error (MSE) is $\frac{M+N-1}{MN}\sigma^2_0$, and for the general $M \times M$ monostatic topology, it is $\frac{2M-1}{M^2}\sigma^2_0$ for the diagonal subchannels, and $\frac{M-1}{M^2}\sigma^2_0$ for the off-diagonal subchannels, where $\sigma^2_0$ is the MSE of the conventional least square estimator. In addition, we derive the Cramer-Rao lower bound (CRLB) for MIMO backscatter TOA estimation which indicates that the proposed estimator is optimal. Simulation results verify that the proposed TOA estimator can considerably improve both estimation and positioning accuracy, especially when the MIMO scale is large.
Occlusion-Robust FAU Recognition by Mining Latent Space of Masked Autoencoders
Dec 08, 2022Facial action units (FAUs) are critical for fine-grained facial expression analysis. Although FAU detection has been actively studied using ideally high quality images, it was not thoroughly studied under heavily occluded conditions. In this paper, we propose the first occlusion-robust FAU recognition method to maintain FAU detection performance under heavy occlusions. Our novel approach takes advantage of rich information from the latent space of masked autoencoder (MAE) and transforms it into FAU features. Bypassing the occlusion reconstruction step, our model efficiently extracts FAU features of occluded faces by mining the latent space of a pretrained masked autoencoder. Both node and edge-level knowledge distillation are also employed to guide our model to find a mapping between latent space vectors and FAU features. Facial occlusion conditions, including random small patches and large blocks, are thoroughly studied. Experimental results on BP4D and DISFA datasets show that our method can achieve state-of-the-art performances under the studied facial occlusion, significantly outperforming existing baseline methods. In particular, even under heavy occlusion, the proposed method can achieve comparable performance as state-of-the-art methods under normal conditions.
Multi-modal Streaming 3D Object Detection
Sep 12, 2022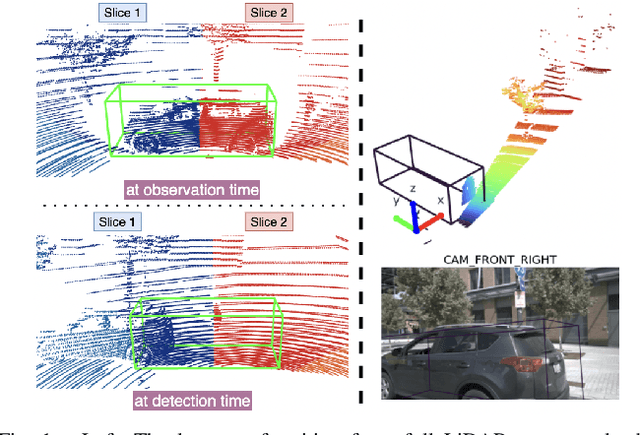
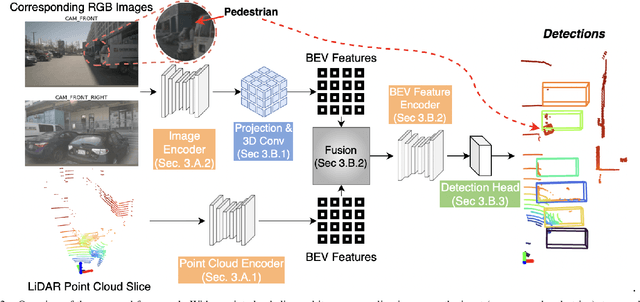
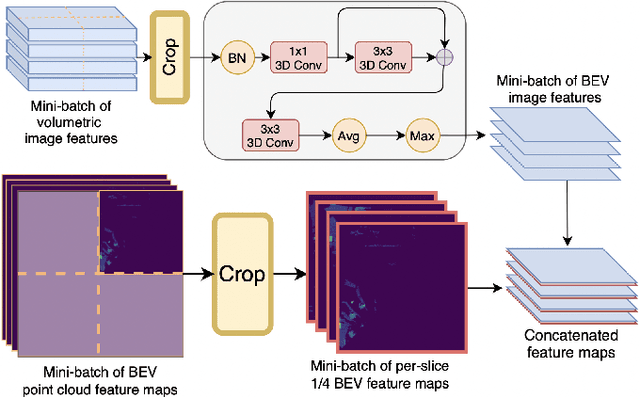

Modern autonomous vehicles rely heavily on mechanical LiDARs for perception. Current perception methods generally require 360{\deg} point clouds, collected sequentially as the LiDAR scans the azimuth and acquires consecutive wedge-shaped slices. The acquisition latency of a full scan (~ 100ms) may lead to outdated perception which is detrimental to safe operation. Recent streaming perception works proposed directly processing LiDAR slices and compensating for the narrow field of view (FOV) of a slice by reusing features from preceding slices. These works, however, are all based on a single modality and require past information which may be outdated. Meanwhile, images from high-frequency cameras can support streaming models as they provide a larger FoV compared to a LiDAR slice. However, this difference in FoV complicates sensor fusion. To address this research gap, we propose an innovative camera-LiDAR streaming 3D object detection framework that uses camera images instead of past LiDAR slices to provide an up-to-date, dense, and wide context for streaming perception. The proposed method outperforms prior streaming models on the challenging NuScenes benchmark. It also outperforms powerful full-scan detectors while being much faster. Our method is shown to be robust to missing camera images, narrow LiDAR slices, and small camera-LiDAR miscalibration.
Joint Precoding for Active Intelligent Transmitting Surface Empowered Outdoor-to-Indoor Communication in mmWave Cellular Networks
Jun 28, 2022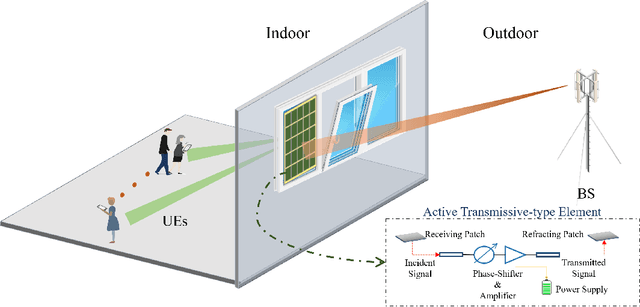
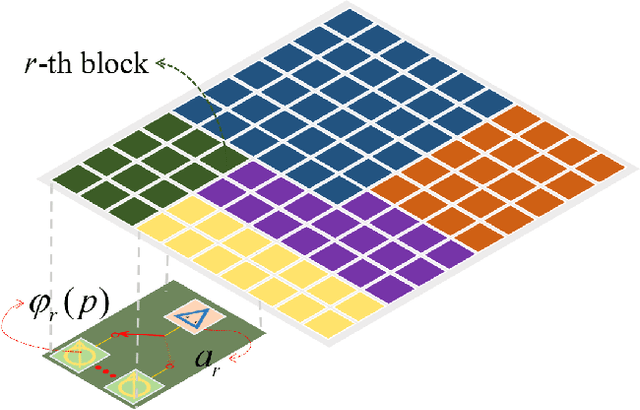
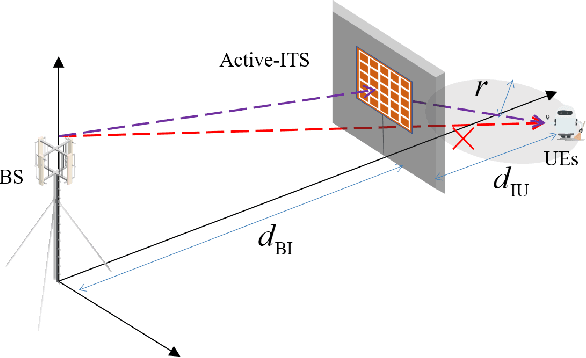
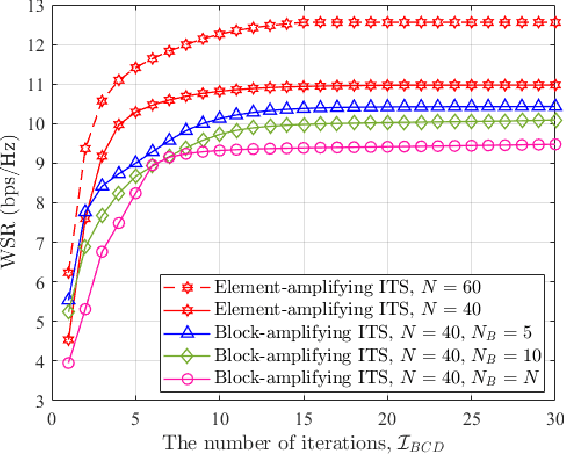
Outdoor-to-indoor communications in millimeter-wave (mmWave) cellular networks have been one challenging research problem due to the severe attenuation and the high penetration loss caused by the propagation characteristics of mmWave signals. We propose a viable solution to implement the outdoor-to-indoor mmWave communication system with the aid of an active intelligent transmitting surface (active-ITS), where the active-ITS allows the incoming signal from an outdoor base station (BS) to pass through the surface and be received by the indoor user-equipments (UEs) after shifting its phase and magnifying its amplitude. Then, the problem of joint precoding of the BS and active-ITS is investigated to maximize the weighted sum-rate (WSR) of the communication system. An efficient block coordinate descent (BCD) based algorithm is developed to solve it with the suboptimal solutions in nearly closed-forms. In addition, to reduce the size and hardware cost of an active-ITS, we provide a block-amplifying architecture to partially remove the circuit components for power-amplifying, where multiple transmissive-type elements (TEs) in each block share a same power amplifier. Simulations indicate that active-ITS has the potential of achieving a given performance with much fewer TEs compared to the passive-ITS under the same total system power consumption, which makes it suitable for application to the size-limited and aesthetic-needed scenario, and the inevitable performance degradation caused by the block-amplifying architecture is acceptable.
Generalizable Neural Radiance Fields for Novel View Synthesis with Transformer
Jun 10, 2022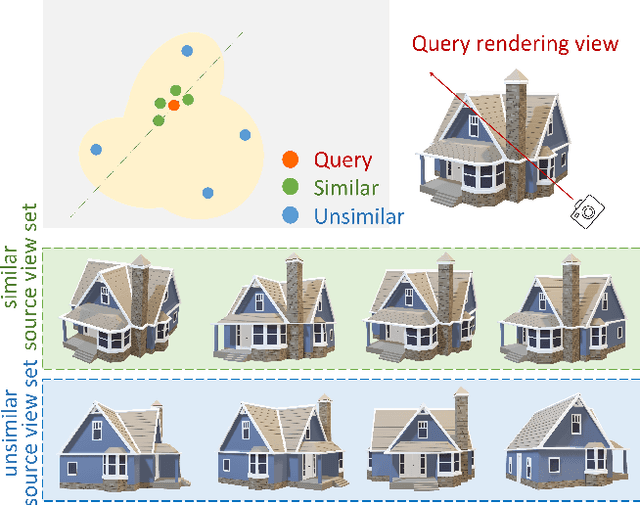

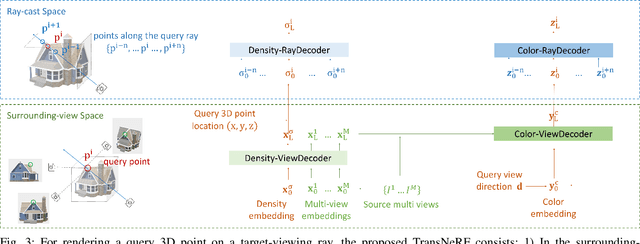

We propose a Transformer-based NeRF (TransNeRF) to learn a generic neural radiance field conditioned on observed-view images for the novel view synthesis task. By contrast, existing MLP-based NeRFs are not able to directly receive observed views with an arbitrary number and require an auxiliary pooling-based operation to fuse source-view information, resulting in the missing of complicated relationships between source views and the target rendering view. Furthermore, current approaches process each 3D point individually and ignore the local consistency of a radiance field scene representation. These limitations potentially can reduce their performance in challenging real-world applications where large differences between source views and a novel rendering view may exist. To address these challenges, our TransNeRF utilizes the attention mechanism to naturally decode deep associations of an arbitrary number of source views into a coordinate-based scene representation. Local consistency of shape and appearance are considered in the ray-cast space and the surrounding-view space within a unified Transformer network. Experiments demonstrate that our TransNeRF, trained on a wide variety of scenes, can achieve better performance in comparison to state-of-the-art image-based neural rendering methods in both scene-agnostic and per-scene finetuning scenarios especially when there is a considerable gap between source views and a rendering view.