 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAM: Continuous Latent Action Models for Robot Learning from Unlabeled Demonstrations
May 08, 2025



Learning robot policies using imitation learning requires collecting large amounts of costly action-labeled expert demonstrations, which fundamentally limits the scale of training data. A promising approach to address this bottleneck is to harness the abundance of unlabeled observations-e.g., from video demonstrations-to learn latent action labels in an unsupervised way. However, we find that existing methods struggle when applied to complex robot tasks requiring fine-grained motions. We design continuous latent action models (CLAM) which incorporate two key ingredients we find necessary for learning to solve complex continuous control tasks from unlabeled observation data: (a) using continuous latent action labels instead of discrete representations, and (b) jointly training an action decoder to ensure that the latent action space can be easily grounded to real actions with relatively few labeled examples. Importantly, the labeled examples can be collected from non-optimal play data, enabling CLAM to learn performant policies without access to any action-labeled expert data. We demonstrate on continuous control benchmarks in DMControl (locomotion) and MetaWorld (manipulation), as well as on a real WidowX robot arm that CLAM significantly outperforms prior state-of-the-art methods, remarkably with a 2-3x improvement in task success rate compared to the best baseline. Videos and code can be found at clamrobot.github.io.
Evaluation of Human-AI Teams for Learned and Rule-Based Agents in Hanabi
Jul 20, 2021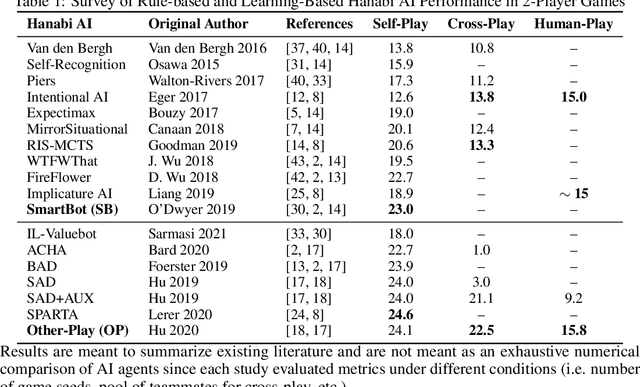
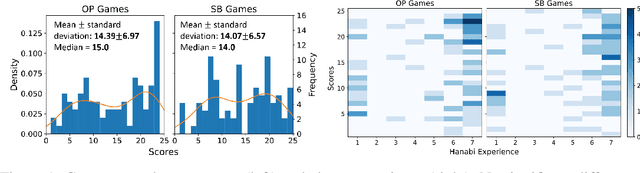
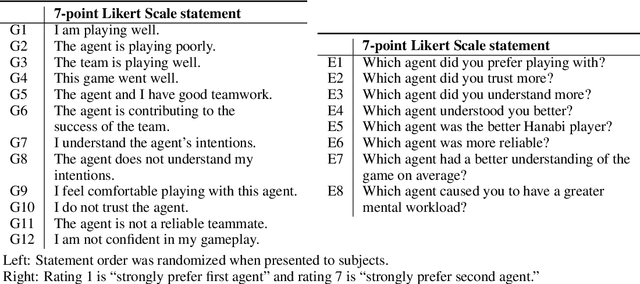
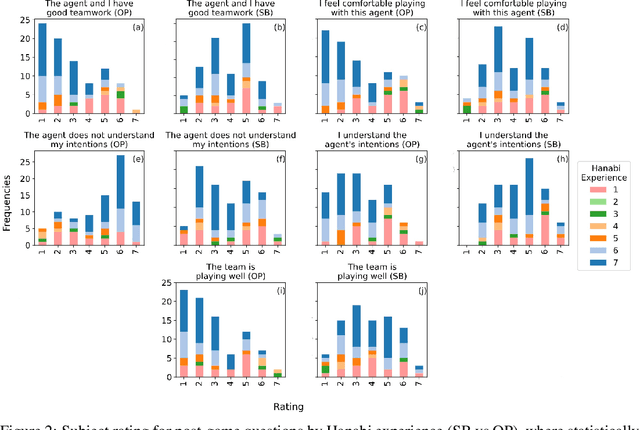
Deep reinforcement learning has generated superhuman AI in competitive games such as Go and StarCraft. Can similar learning techniques create a superior AI teammate for human-machine collaborative games? Will humans prefer AI teammates that improve objective team performance or those that improve subjective metrics of trust? In this study, we perform a single-blind evaluation of teams of humans and AI agents in the cooperative card game Hanabi, with both rule-based and learning-based agents. In addition to the game score, used as an objective metric of the human-AI team performance, we also quantify subjective measures of the human's perceived performance, teamwork, interpretability, trust, and overall preference of AI teammate. We find that humans have a clear preference toward a rule-based AI teammate (SmartBot) over a state-of-the-art learning-based AI teammate (Other-Play) across nearly all subjective metrics, and generally view the learning-based agent negatively, despite no statistical difference in the game score. This result has implications for future AI design and reinforcement learning benchmarking, highlighting the need to incorporate subjective metrics of human-AI teaming rather than a singular focus on objective task performance.
Learning Emergent Discrete Message Communication for Cooperative Reinforcement Learning
Feb 24, 2021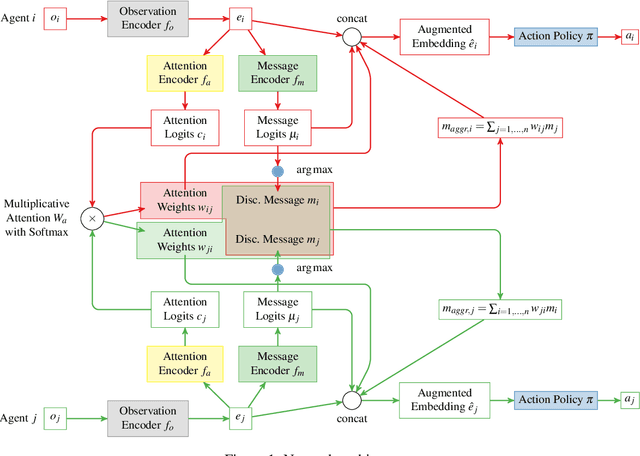
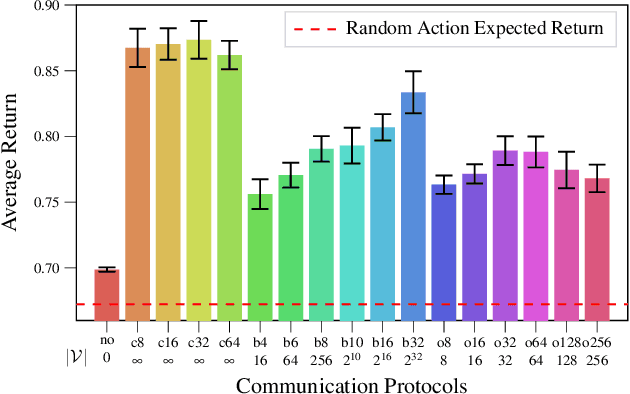
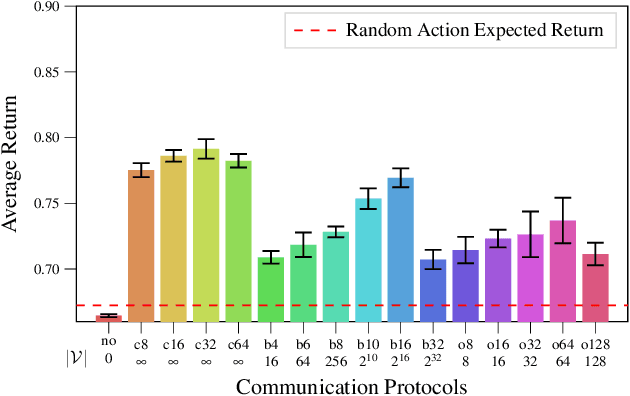
Communication is a important factor that enables agents work cooperatively in multi-agent reinforcement learning (MARL). Most previous work uses continuous message communication whose high representational capacity comes at the expense of interpretability. Allowing agents to learn their own discrete message communication protocol emerged from a variety of domains can increase the interpretability for human designers and other agents.This paper proposes a method to generate discrete messages analogous to human languages, and achieve communication by a broadcast-and-listen mechanism based on self-attention. We show that discrete message communication has performance comparable to continuous message communication but with much a much smaller vocabulary size.Furthermore, we propose an approach that allows humans to interactively send discrete messages to agents.