 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Loss to Rule Them All: Marked Time-to-Event for Structured EHR Foundation Models
Jan 31, 2026Clinical events captured in Electronic Health Records (EHR) are irregularly sampled and may consist of a mixture of discrete events and numerical measurements, such as laboratory values or treatment dosages. The sequential nature of EHR, analogous to natural language, has motivated the use of next-token prediction to train prior EHR Foundation Models (FMs) over events. However, this training fails to capture the full structure of EHR. We propose ORA, a marked time-to-event pretraining objective that jointly models event timing and associated measurements. Across multiple datasets, downstream tasks, and model architectures, this objective consistently yields more generalizable representations than next-token prediction and pretraining losses that ignore continuous measurements. Importantly, the proposed objective yields improvements beyond traditional classification evaluation, including better regression and time-to-event prediction. Beyond introducing a new family of FMs, our results suggest a broader takeaway: pretraining objectives that account for EHR structure are critical for expanding downstream capabilities and generalizability
Learning-To-Measure: In-context Active Feature Acquisition
Oct 14, 2025



Active feature acquisition (AFA) is a sequential decision-making problem where the goal is to improve model performance for test instances by adaptively selecting which features to acquire. In practice, AFA methods often learn from retrospective data with systematic missingness in the features and limited task-specific labels. Most prior work addresses acquisition for a single predetermined task, limiting scalability. To address this limitation, we formalize the meta-AFA problem, where the goal is to learn acquisition policies across various tasks. We introduce Learning-to-Measure (L2M), which consists of i) reliable uncertainty quantification over unseen tasks, and ii) an uncertainty-guided greedy feature acquisition agent that maximizes conditional mutual information. We demonstrate a sequence-modeling or autoregressive pre-training approach that underpins reliable uncertainty quantification for tasks with arbitrary missingness. L2M operates directly on datasets with retrospective missingness and performs the meta-AFA task in-context, eliminating per-task retraining. Across synthetic and real-world tabular benchmarks, L2M matches or surpasses task-specific baselines, particularly under scarce labels and high missingness.
FoMoH: A clinically meaningful foundation model evaluation for structured electronic health records
May 22, 2025Foundation models hold significant promise in healthcare, given their capacity to extract meaningful representations independent of downstream tasks. This property has enabled state-of-the-art performance across several clinical applications trained on structured electronic health record (EHR) data, even in settings with limited labeled data, a prevalent challenge in healthcare. However, there is little consensus on these models' potential for clinical utility due to the lack of desiderata of comprehensive and meaningful tasks and sufficiently diverse evaluations to characterize the benefit over conventional supervised learning. To address this gap, we propose a suite of clinically meaningful tasks spanning patient outcomes, early prediction of acute and chronic conditions, including desiderata for robust evaluations. We evaluate state-of-the-art foundation models on EHR data consisting of 5 million patients from Columbia University Irving Medical Center (CUMC), a large urban academic medical center in New York City, across 14 clinically relevant tasks. We measure overall accuracy, calibration, and subpopulation performance to surface tradeoffs based on the choice of pre-training, tokenization, and data representation strategies. Our study aims to advance the empirical evaluation of structured EHR foundation models and guide the development of future healthcare foundation models.
MOEA/D with Adaptative Number of Weight Vectors
Sep 13, 2021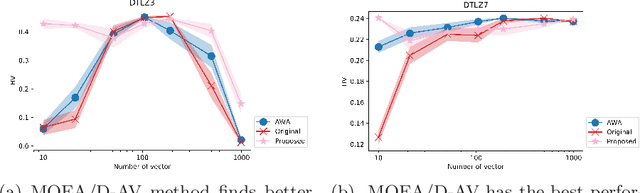
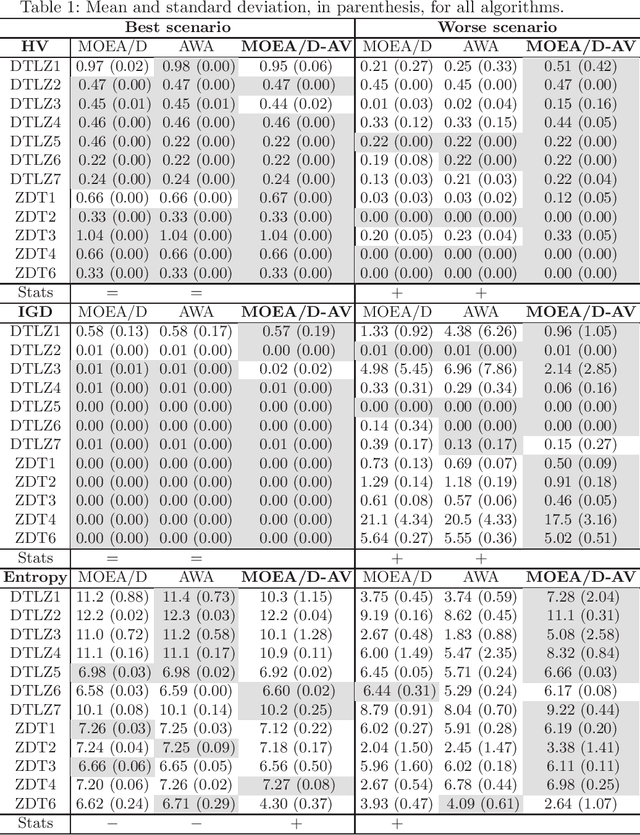
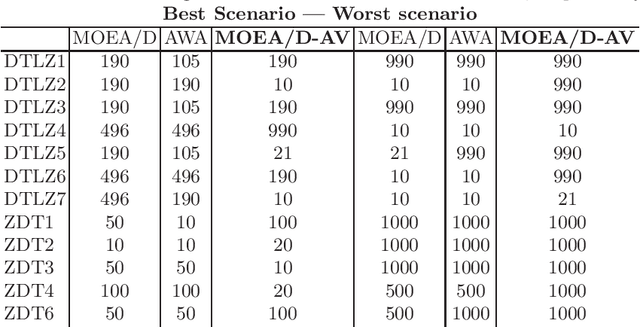
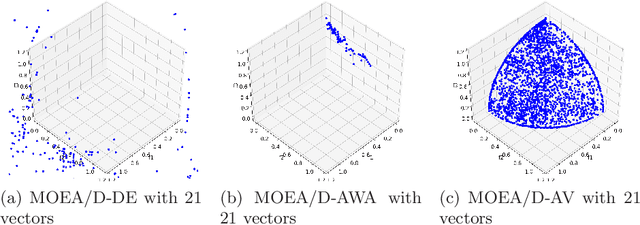
The Multi-Objective Evolutionary Algorithm based on Decomposition (MOEA/D) is a popular algorithm for solving Multi-Objective Problems (MOPs). The main component of MOEA/D is to decompose a MOP into easier sub-problems using a set of weight vectors. The choice of the number of weight vectors significantly impacts the performance of MOEA/D. However, the right choice for this number varies, given different MOPs and search stages. Here we adaptively change the number of vectors by removing unnecessary vectors and adding new ones in empty areas of the objective space. Our MOEA/D variant uses the Consolidation Ratio to decide when to change the number of vectors, and then it decides where to add or remove these weighted vectors. We investigate the effects of this adaptive MOEA/D against MOEA/D with a poorly chosen set of vectors, a MOEA/D with fine-tuned vectors and MOEA/D-AWA on the DTLZ and ZDT benchmark functions. We analyse the algorithms in terms of hypervolume, IGD and entropy performance. Our results show that the proposed method is equivalent to MOEA/D with fine-tuned vectors and superior to MOEA/D with poorly defined vectors. Thus, our adaptive mechanism mitigates problems related to the choice of the number of weight vectors in MOEA/D, increasing the final performance of MOEA/D by filling empty areas of the objective space while avoiding premature stagnation of the search progress.