 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneComp: One-Line Revolution for Generative AI Model Compression
Mar 30, 2026Deploying foundation models is increasingly constrained by memory footprint, latency, and hardware costs. Post-training compression can mitigate these bottlenecks by reducing the precision of model parameters without significantly degrading performance; however, its practical implementation remains challenging as practitioners navigate a fragmented landscape of quantization algorithms, precision budgets, data-driven calibration strategies, and hardware-dependent execution regimes. We present OneComp, an open-source compression framework that transforms this expert workflow into a reproducible, resource-adaptive pipeline. Given a model identifier and available hardware, OneComp automatically inspects the model, plans mixed-precision assignments, and executes progressive quantization stages, ranging from layer-wise compression to block-wise refinement and global refinement. A key architectural choice is treating the first quantized checkpoint as a deployable pivot, ensuring that each subsequent stage improves the same model and that quality increases as more compute is invested. By converting state-of-the-art compression research into an extensible, open-source, hardware-aware pipeline, OneComp bridges the gap between algorithmic innovation and production-grade model deployment.
Learning Domain Invariant Representations by Joint Wasserstein Distance Minimization
Jun 09, 2021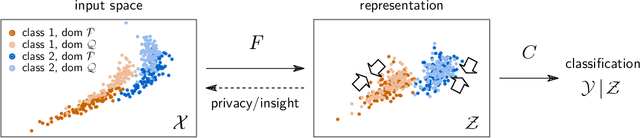
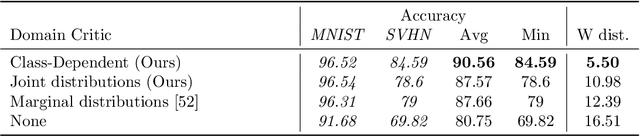
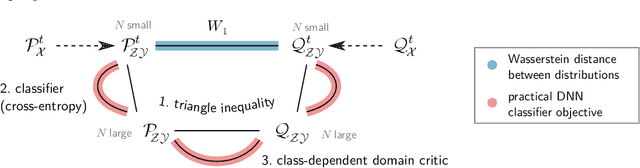
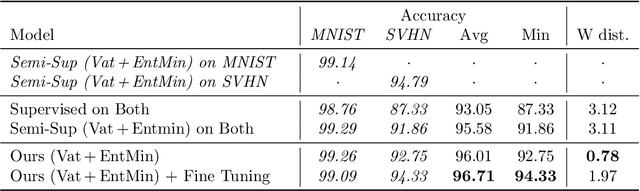
Domain shifts in the training data are common in practical applications of machine learning, they occur for instance when the data is coming from different sources. Ideally, a ML model should work well independently of these shifts, for example, by learning a domain-invariant representation. Moreover, privacy concerns regarding the source also require a domain-invariant representation. In this work, we provide theoretical results that link domain invariant representations -- measured by the Wasserstein distance on the joint distributions -- to a practical semi-supervised learning objective based on a cross-entropy classifier and a novel domain critic. Quantitative experiments demonstrate that the proposed approach is indeed able to practically learn such an invariant representation (between two domains), and the latter also supports models with higher predictive accuracy on both domains, comparing favorably to existing techniques.