 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Object Detection by Sequential Risk Control
May 29, 2025



Recent advances in object detectors have led to their adoption for industrial uses. However, their deployment in critical applications is hindered by the inherent lack of reliability of neural networks and the complex structure of object detection models. To address these challenges, we turn to Conformal Prediction, a post-hoc procedure which offers statistical guarantees that are valid for any dataset size, without requiring prior knowledge on the model or data distribution. Our contribution is manifold: first, we formally define the problem of Conformal Object Detection (COD) and introduce a novel method, Sequential Conformal Risk Control (SeqCRC), that extends the statistical guarantees of Conformal Risk Control (CRC) to two sequential tasks with two parameters, as required in the COD setting. Then, we propose loss functions and prediction sets suited to applying CRC to different applications and certification requirements. Finally, we present a conformal toolkit, enabling replication and further exploration of our methods. Using this toolkit, we perform extensive experiments, yielding a benchmark that validates the investigated methods and emphasizes trade-offs and other practical consequences.
Conformal Prediction for Trustworthy Detection of Railway Signals
Jan 26, 2023We present an application of conformal prediction, a form of uncertainty quantification with guarantees, to the detection of railway signals. State-of-the-art architectures are tested and the most promising one undergoes the process of conformalization, where a correction is applied to the predicted bounding boxes (i.e. to their height and width) such that they comply with a predefined probability of success. We work with a novel exploratory dataset of images taken from the perspective of a train operator, as a first step to build and validate future trustworthy machine learning models for the detection of railway signals.
Learning Domain Invariant Representations by Joint Wasserstein Distance Minimization
Jun 09, 2021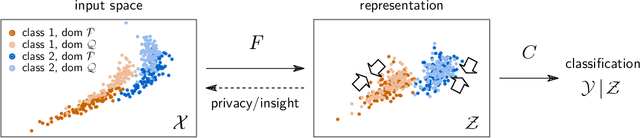
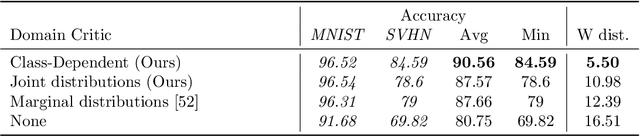
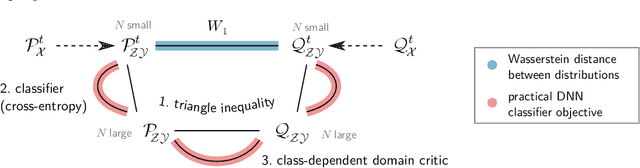
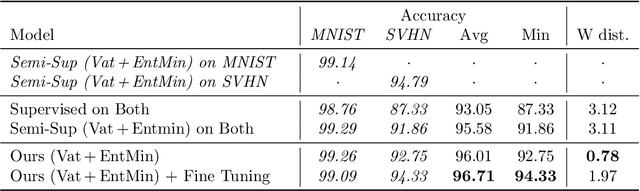
Domain shifts in the training data are common in practical applications of machine learning, they occur for instance when the data is coming from different sources. Ideally, a ML model should work well independently of these shifts, for example, by learning a domain-invariant representation. Moreover, privacy concerns regarding the source also require a domain-invariant representation. In this work, we provide theoretical results that link domain invariant representations -- measured by the Wasserstein distance on the joint distributions -- to a practical semi-supervised learning objective based on a cross-entropy classifier and a novel domain critic. Quantitative experiments demonstrate that the proposed approach is indeed able to practically learn such an invariant representation (between two domains), and the latter also supports models with higher predictive accuracy on both domains, comparing favorably to existing techniques.