 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoEcho: Exploiting Side-Channel Attacks to Compromise User Privacy in Mixture-of-Experts LLMs
Aug 20, 2025



The transformer architecture has become a cornerstone of modern AI, fueling remarkable progress across applications in natural language processing, computer vision, and multimodal learning. As these models continue to scale explosively for performance, implementation efficiency remains a critical challenge. Mixture of Experts (MoE) architectures, selectively activating specialized subnetworks (experts), offer a unique balance between model accuracy and computational cost. However, the adaptive routing in MoE architectures, where input tokens are dynamically directed to specialized experts based on their semantic meaning inadvertently opens up a new attack surface for privacy breaches. These input-dependent activation patterns leave distinctive temporal and spatial traces in hardware execution, which adversaries could exploit to deduce sensitive user data. In this work, we propose MoEcho, discovering a side channel analysis based attack surface that compromises user privacy on MoE based systems. Specifically, in MoEcho, we introduce four novel architectural side channels on different computing platforms, including Cache Occupancy Channels and Pageout+Reload on CPUs, and Performance Counter and TLB Evict+Reload on GPUs, respectively. Exploiting these vulnerabilities, we propose four attacks that effectively breach user privacy in large language models (LLMs) and vision language models (VLMs) based on MoE architectures: Prompt Inference Attack, Response Reconstruction Attack, Visual Inference Attack, and Visual Reconstruction Attack. MoEcho is the first runtime architecture level security analysis of the popular MoE structure common in modern transformers, highlighting a serious security and privacy threat and calling for effective and timely safeguards when harnessing MoE based models for developing efficient large scale AI services.
Graph in the Vault: Protecting Edge GNN Inference with Trusted Execution Environment
Feb 20, 2025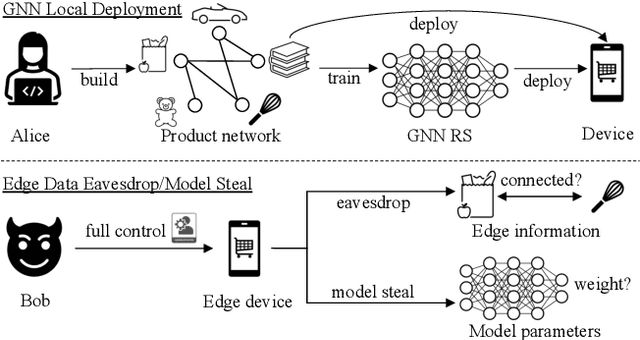

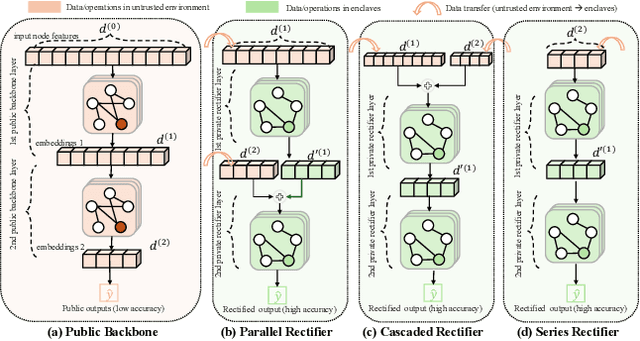
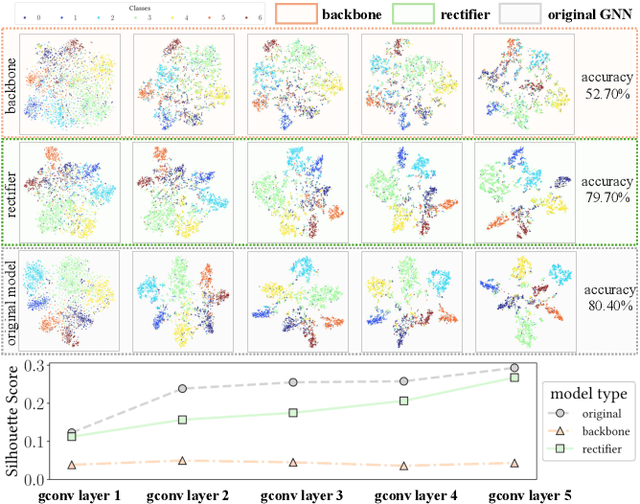
Wide deployment of machine learning models on edge devices has rendered the model intellectual property (IP) and data privacy vulnerable. We propose GNNVault, the first secure Graph Neural Network (GNN) deployment strategy based on Trusted Execution Environment (TEE). GNNVault follows the design of 'partition-before-training' and includes a private GNN rectifier to complement with a public backbone model. This way, both critical GNN model parameters and the private graph used during inference are protected within secure TEE compartments. Real-world implementations with Intel SGX demonstrate that GNNVault safeguards GNN inference against state-of-the-art link stealing attacks with negligible accuracy degradation (<2%).
Non-transferable Pruning
Oct 10, 2024



Pretrained Deep Neural Networks (DNNs), developed from extensive datasets to integrate multifaceted knowledge, are increasingly recognized as valuable intellectual property (IP). To safeguard these models against IP infringement, strategies for ownership verification and usage authorization have emerged. Unlike most existing IP protection strategies that concentrate on restricting direct access to the model, our study addresses an extended DNN IP issue: applicability authorization, aiming to prevent the misuse of learned knowledge, particularly in unauthorized transfer learning scenarios. We propose Non-Transferable Pruning (NTP), a novel IP protection method that leverages model pruning to control a pretrained DNN's transferability to unauthorized data domains. Selective pruning can deliberately diminish a model's suitability on unauthorized domains, even with full fine-tuning. Specifically, our framework employs the alternating direction method of multipliers (ADMM) for optimizing both the model sparsity and an innovative non-transferable learning loss, augmented with Fisher space discriminative regularization, to constrain the model's generalizability to the target dataset. We also propose a novel effective metric to measure the model non-transferability: Area Under the Sample-wise Learning Curve (SLC-AUC). This metric facilitates consideration of full fine-tuning across various sample sizes. Experimental results demonstrate that NTP significantly surpasses the state-of-the-art non-transferable learning methods, with an average SLC-AUC at $-0.54$ across diverse pairs of source and target domains, indicating that models trained with NTP do not suit for transfer learning to unauthorized target domains. The efficacy of NTP is validated in both supervised and self-supervised learning contexts, confirming its applicability in real-world scenarios.
GraphCroc: Cross-Correlation Autoencoder for Graph Structural Reconstruction
Oct 04, 2024



Graph-structured data is integral to many applications, prompting the development of various graph representation methods. Graph autoencoders (GAEs), in particular, reconstruct graph structures from node embeddings. Current GAE models primarily utilize self-correlation to represent graph structures and focus on node-level tasks, often overlooking multi-graph scenarios. Our theoretical analysis indicates that self-correlation generally falls short in accurately representing specific graph features such as islands, symmetrical structures, and directional edges, particularly in smaller or multiple graph contexts. To address these limitations, we introduce a cross-correlation mechanism that significantly enhances the GAE representational capabilities. Additionally, we propose GraphCroc, a new GAE that supports flexible encoder architectures tailored for various downstream tasks and ensures robust structural reconstruction, through a mirrored encoding-decoding process. This model also tackles the challenge of representation bias during optimization by implementing a loss-balancing strategy. Both theoretical analysis and numerical evaluations demonstrate that our methodology significantly outperforms existing self-correlation-based GAEs in graph structure reconstruction.
VertexSerum: Poisoning Graph Neural Networks for Link Inference
Aug 02, 2023



Graph neural networks (GNNs) have brought superb performance to various applications utilizing graph structural data, such as social analysis and fraud detection. The graph links, e.g., social relationships and transaction history, are sensitive and valuable information, which raises privacy concerns when using GNNs. To exploit these vulnerabilities, we propose VertexSerum, a novel graph poisoning attack that increases the effectiveness of graph link stealing by amplifying the link connectivity leakage. To infer node adjacency more accurately, we propose an attention mechanism that can be embedded into the link detection network. Our experiments demonstrate that VertexSerum significantly outperforms the SOTA link inference attack, improving the AUC scores by an average of $9.8\%$ across four real-world datasets and three different GNN structures. Furthermore, our experiments reveal the effectiveness of VertexSerum in both black-box and online learning settings, further validating its applicability in real-world scenarios.
EMShepherd: Detecting Adversarial Samples via Side-channel Leakage
Mar 27, 2023



Deep Neural Networks (DNN) are vulnerable to adversarial perturbations-small changes crafted deliberately on the input to mislead the model for wrong predictions. Adversarial attacks have disastrous consequences for deep learning-empowered critical applications. Existing defense and detection techniques both require extensive knowledge of the model, testing inputs, and even execution details. They are not viable for general deep learning implementations where the model internal is unknown, a common 'black-box' scenario for model users. Inspired by the fact that electromagnetic (EM) emanations of a model inference are dependent on both operations and data and may contain footprints of different input classes, we propose a framework, EMShepherd, to capture EM traces of model execution, perform processing on traces and exploit them for adversarial detection. Only benign samples and their EM traces are used to train the adversarial detector: a set of EM classifiers and class-specific unsupervised anomaly detectors. When the victim model system is under attack by an adversarial example, the model execution will be different from executions for the known classes, and the EM trace will be different. We demonstrate that our air-gapped EMShepherd can effectively detect different adversarial attacks on a commonly used FPGA deep learning accelerator for both Fashion MNIST and CIFAR-10 datasets. It achieves a 100% detection rate on most types of adversarial samples, which is comparable to the state-of-the-art 'white-box' software-based detectors.
Sensitive Samples Revisited: Detecting Neural Network Attacks Using Constraint Solvers
Sep 07, 2021
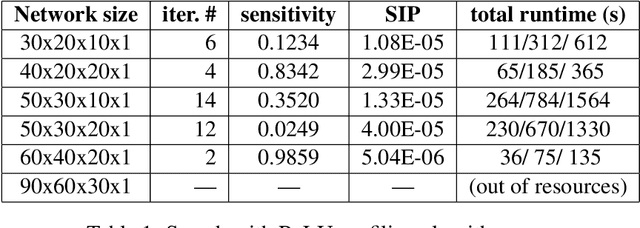
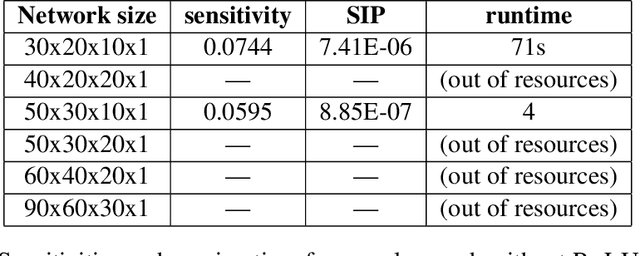
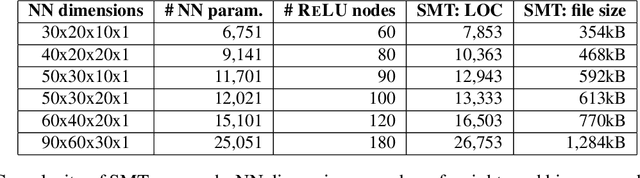
Neural Networks are used today in numerous security- and safety-relevant domains and are, as such, a popular target of attacks that subvert their classification capabilities, by manipulating the network parameters. Prior work has introduced sensitive samples -- inputs highly sensitive to parameter changes -- to detect such manipulations, and proposed a gradient ascent-based approach to compute them. In this paper we offer an alternative, using symbolic constraint solvers. We model the network and a formal specification of a sensitive sample in the language of the solver and ask for a solution. This approach supports a rich class of queries, corresponding, for instance, to the presence of certain types of attacks. Unlike earlier techniques, our approach does not depend on convex search domains, or on the suitability of a starting point for the search. We address the performance limitations of constraint solvers by partitioning the search space for the solver, and exploring the partitions according to a balanced schedule that still retains completeness of the search. We demonstrate the impact of the use of solvers in terms of functionality and search efficiency, using a case study for the detection of Trojan attacks on Neural Networks.
* In Proceedings SCSS 2021, arXiv:2109.02501
Fault Sneaking Attack: a Stealthy Framework for Misleading Deep Neural Networks
May 28, 2019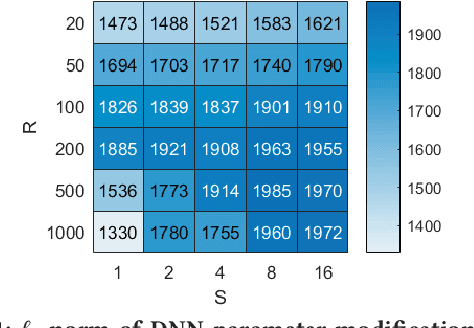
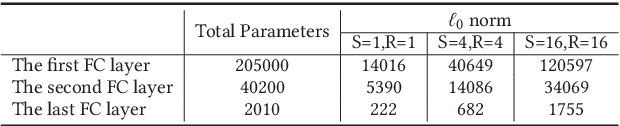
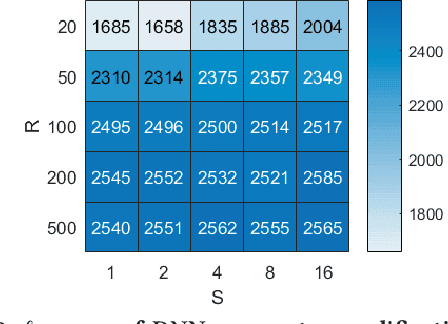

Despite the great achievements of deep neural networks (DNNs), the vulnerability of state-of-the-art DNNs raises security concerns of DNNs in many application domains requiring high reliability.We propose the fault sneaking attack on DNNs, where the adversary aims to misclassify certain input images into any target labels by modifying the DNN parameters. We apply ADMM (alternating direction method of multipliers) for solving the optimization problem of the fault sneaking attack with two constraints: 1) the classification of the other images should be unchanged and 2) the parameter modifications should be minimized. Specifically, the first constraint requires us not only to inject designated faults (misclassifications), but also to hide the faults for stealthy or sneaking considerations by maintaining model accuracy. The second constraint requires us to minimize the parameter modifications (using L0 norm to measure the number of modifications and L2 norm to measure the magnitude of modifications). Comprehensive experimental evaluation demonstrates that the proposed framework can inject multiple sneaking faults without losing the overall test accuracy performance.