 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoEcho: Exploiting Side-Channel Attacks to Compromise User Privacy in Mixture-of-Experts LLMs
Aug 20, 2025



The transformer architecture has become a cornerstone of modern AI, fueling remarkable progress across applications in natural language processing, computer vision, and multimodal learning. As these models continue to scale explosively for performance, implementation efficiency remains a critical challenge. Mixture of Experts (MoE) architectures, selectively activating specialized subnetworks (experts), offer a unique balance between model accuracy and computational cost. However, the adaptive routing in MoE architectures, where input tokens are dynamically directed to specialized experts based on their semantic meaning inadvertently opens up a new attack surface for privacy breaches. These input-dependent activation patterns leave distinctive temporal and spatial traces in hardware execution, which adversaries could exploit to deduce sensitive user data. In this work, we propose MoEcho, discovering a side channel analysis based attack surface that compromises user privacy on MoE based systems. Specifically, in MoEcho, we introduce four novel architectural side channels on different computing platforms, including Cache Occupancy Channels and Pageout+Reload on CPUs, and Performance Counter and TLB Evict+Reload on GPUs, respectively. Exploiting these vulnerabilities, we propose four attacks that effectively breach user privacy in large language models (LLMs) and vision language models (VLMs) based on MoE architectures: Prompt Inference Attack, Response Reconstruction Attack, Visual Inference Attack, and Visual Reconstruction Attack. MoEcho is the first runtime architecture level security analysis of the popular MoE structure common in modern transformers, highlighting a serious security and privacy threat and calling for effective and timely safeguards when harnessing MoE based models for developing efficient large scale AI services.
Graph in the Vault: Protecting Edge GNN Inference with Trusted Execution Environment
Feb 20, 2025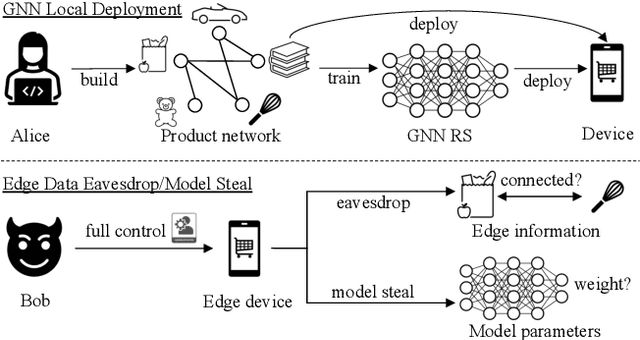

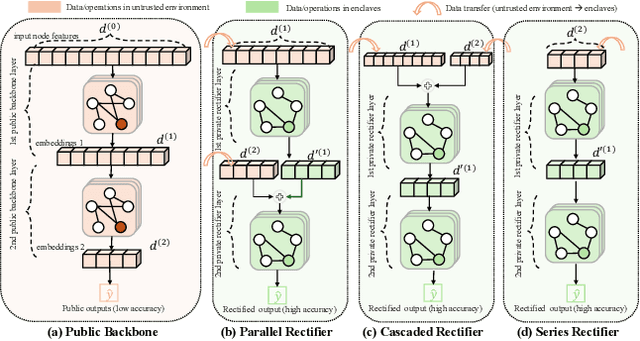
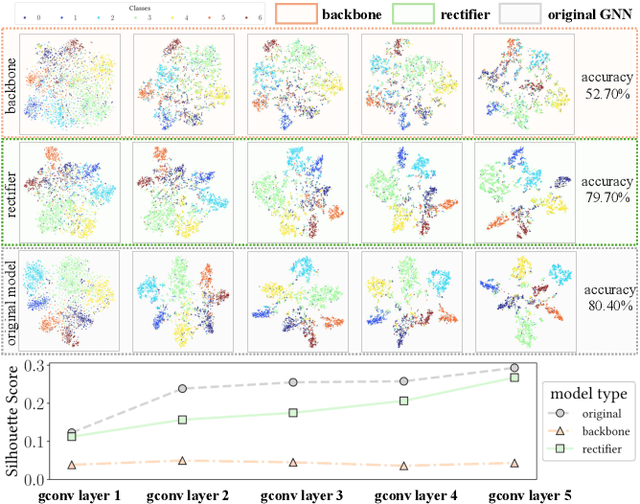
Wide deployment of machine learning models on edge devices has rendered the model intellectual property (IP) and data privacy vulnerable. We propose GNNVault, the first secure Graph Neural Network (GNN) deployment strategy based on Trusted Execution Environment (TEE). GNNVault follows the design of 'partition-before-training' and includes a private GNN rectifier to complement with a public backbone model. This way, both critical GNN model parameters and the private graph used during inference are protected within secure TEE compartments. Real-world implementations with Intel SGX demonstrate that GNNVault safeguards GNN inference against state-of-the-art link stealing attacks with negligible accuracy degradation (<2%).