 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRONG-VLA: Decoupled Robustness Learning for Vision-Language-Action Models under Multimodal Perturbations
Apr 14, 2026Despite their strong performance in embodied tasks, recent Vision-Language-Action (VLA) models remain highly fragile under multimodal perturbations, where visual corruption and linguistic noise jointly induce distribution shifts that degrade task-level execution. Existing robustness approaches typically rely on joint training with perturbed data, treating robustness as a static objective, which leads to conflicting optimization between robustness and task fidelity. In this work, we propose STRONG-VLA, a decoupled fine-tuning framework that explicitly separates robustness acquisition from task-aligned refinement. In Stage I, the model is exposed to a curriculum of multimodal perturbations with increasing difficulty, enabling progressive robustness learning under controlled distribution shifts. In Stage II, the model is re-aligned with clean task distributions to recover execution fidelity while preserving robustness. We further establish a comprehensive benchmark with 28 perturbation types spanning both textual and visual modalities, grounded in realistic sources of sensor noise, occlusion, and instruction corruption. Extensive experiments on the LIBERO benchmark show that STRONG-VLA consistently improves task success rates across multiple VLA architectures. On OpenVLA, our method achieves gains of up to 12.60% under seen perturbations and 7.77% under unseen perturbations. Notably, similar or larger improvements are observed on OpenVLA-OFT (+14.48% / +13.81%) and pi0 (+16.49% / +5.58%), demonstrating strong cross-architecture generalization. Real-world experiments on an AIRBOT robotic platform further validate its practical effectiveness. These results highlight the importance of decoupled optimization for multimodal robustness and establish STRONG-VLA as a simple yet principled framework for robust embodied control.
DynamicTrack: Advancing Gigapixel Tracking in Crowded Scenes
Jul 26, 2024



Tracking in gigapixel scenarios holds numerous potential applications in video surveillance and pedestrian analysis. Existing algorithms attempt to perform tracking in crowded scenes by utilizing multiple cameras or group relationships. However, their performance significantly degrades when confronted with complex interaction and occlusion inherent in gigapixel images. In this paper, we introduce DynamicTrack, a dynamic tracking framework designed to address gigapixel tracking challenges in crowded scenes. In particular, we propose a dynamic detector that utilizes contrastive learning to jointly detect the head and body of pedestrians. Building upon this, we design a dynamic association algorithm that effectively utilizes head and body information for matching purposes. Extensive experiments show that our tracker achieves state-of-the-art performance on widely used tracking benchmarks specifically designed for gigapixel crowded scenes.
On Multi-Agent Learning in Team Sports Games
Jun 25, 2019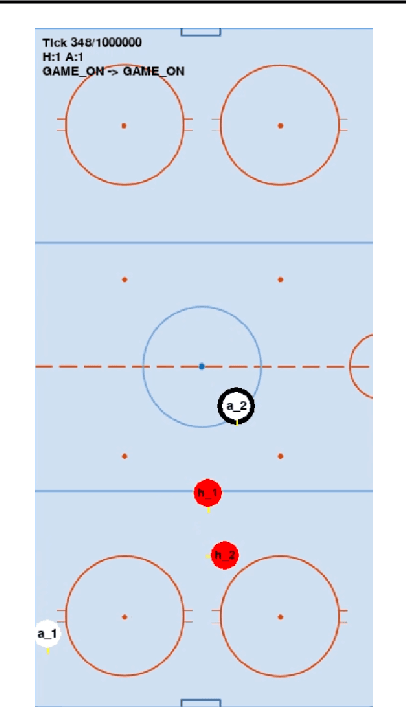
In recent years, reinforcement learning has been successful in solving video games from Atari to Star Craft II. However, the end-to-end model-free reinforcement learning (RL) is not sample efficient and requires a significant amount of computational resources to achieve superhuman level performance. Model-free RL is also unlikely to produce human-like agents for playtesting and gameplaying AI in the development cycle of complex video games. In this paper, we present a hierarchical approach to training agents with the goal of achieving human-like style and high skill level in team sports games. While this is still work in progress, our preliminary results show that the presented approach holds promise for solving the posed multi-agent learning problem.
Winning Isn't Everything: Training Human-Like Agents for Playtesting and Game AI
Mar 25, 2019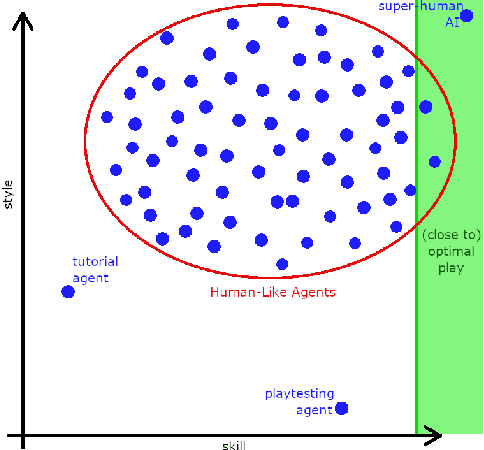
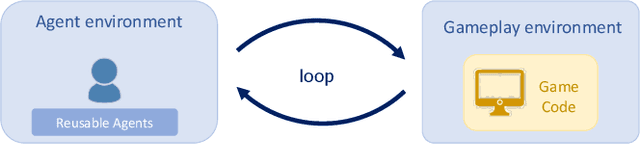
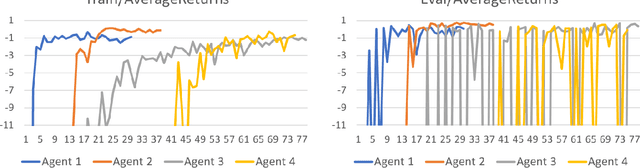
Recently, there have been several high-profile achievements of agents learning to play games against humans and beat them. We consider an alternative approach that instead addresses game design for a better player experience by training human-like game agents. Specifically, we study the problem of training game agents in service of the development processes of the game developers that design, build, and operate modern games. We highlight some of the ways in which we think intelligent agents can assist game developers to understand their games, and even to build them. Our early results using the proposed agent framework mark a few steps toward addressing the unique challenges that game developers face.