 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFADO: Feedback-Aware Double COntrolling Network for Emotional Support Conversation
Nov 01, 2022Emotional Support Conversation (ESConv) aims to reduce help-seekers'emotional distress with the supportive strategy and response. It is essential for the supporter to select an appropriate strategy with the feedback of the help-seeker (e.g., emotion change during dialog turns, etc) in ESConv. However, previous methods mainly focus on the dialog history to select the strategy and ignore the help-seeker's feedback, leading to the wrong and user-irrelevant strategy prediction. In addition, these approaches only model the context-to-strategy flow and pay less attention to the strategy-to-context flow that can focus on the strategy-related context for generating the strategy-constrain response. In this paper, we propose a Feedback-Aware Double COntrolling Network (FADO) to make a strategy schedule and generate the supportive response. The core module in FADO consists of a dual-level feedback strategy selector and a double control reader. Specifically, the dual-level feedback strategy selector leverages the turn-level and conversation-level feedback to encourage or penalize strategies. The double control reader constructs the novel strategy-to-context flow for generating the strategy-constrain response. Furthermore, a strategy dictionary is designed to enrich the semantic information of the strategy and improve the quality of strategy-constrain response. Experimental results on ESConv show that the proposed FADO has achieved the state-of-the-art performance in terms of both strategy selection and response generation. Our code is available at https://github/after/reviewing.
Psychology-guided Controllable Story Generation
Oct 14, 2022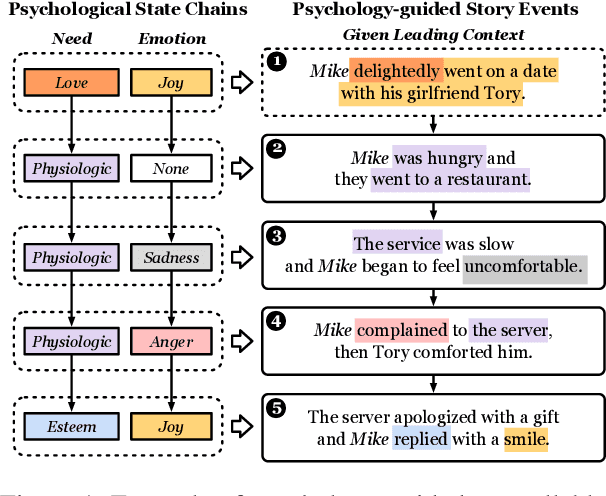

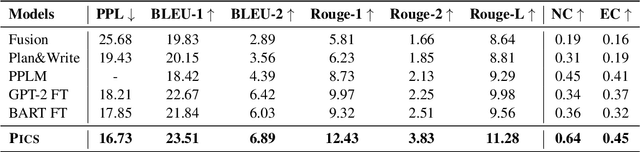
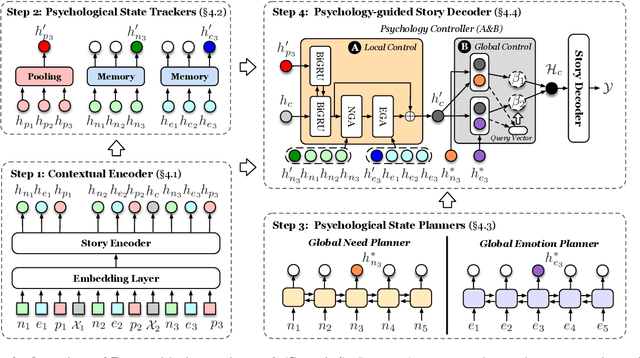
Controllable story generation is a challenging task in the field of NLP, which has attracted increasing research interest in recent years. However, most existing works generate a whole story conditioned on the appointed keywords or emotions, ignoring the psychological changes of the protagonist. Inspired by psychology theories, we introduce global psychological state chains, which include the needs and emotions of the protagonists, to help a story generation system create more controllable and well-planned stories. In this paper, we propose a Psychology-guIded Controllable Story Generation System (PICS) to generate stories that adhere to the given leading context and desired psychological state chains for the protagonist. Specifically, psychological state trackers are employed to memorize the protagonist's local psychological states to capture their inner temporal relationships. In addition, psychological state planners are adopted to gain the protagonist's global psychological states for story planning. Eventually, a psychology controller is designed to integrate the local and global psychological states into the story context representation for composing psychology-guided stories. Automatic and manual evaluations demonstrate that PICS outperforms baselines, and each part of PICS shows effectiveness for writing stories with more consistent psychological changes.
Particle Flow Gaussian Particle Filter
Jul 04, 2022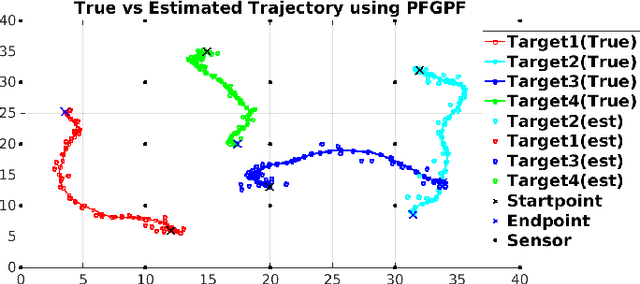
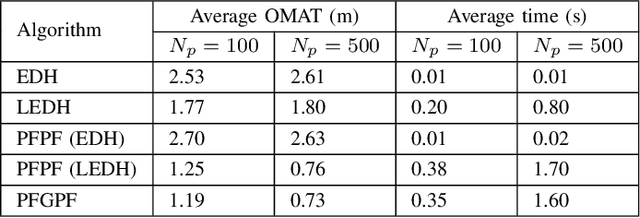
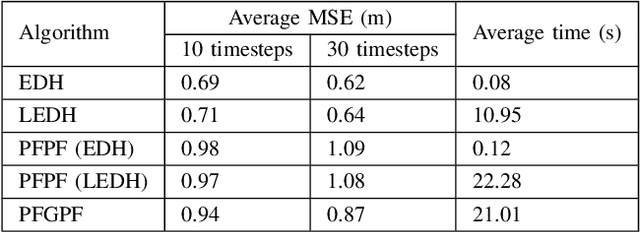
State estimation in non-linear models is performed by tracking the posterior distribution recursively. A plethora of algorithms have been proposed for this task. Among them, the Gaussian particle filter uses a weighted set of particles to construct a Gaussian approximation to the posterior. In this paper, we propose to use invertible particle flow methods, derived under the Gaussian boundary conditions for a flow equation, to generate a proposal distribution close to the posterior. The resultant particle flow Gaussian particle filter (PFGPF) algorithm retains the asymptotic properties of Gaussian particle filters, with the potential for improved state estimation performance in high dimensional spaces. We compare the performance of PFGPF with the particle flow filters and particle flow particle filters in two challenging numerical simulation examples.
Batch-Ensemble Stochastic Neural Networks for Out-of-Distribution Detection
Jun 26, 2022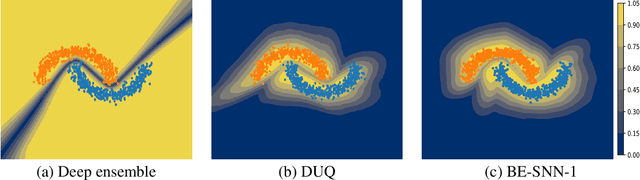
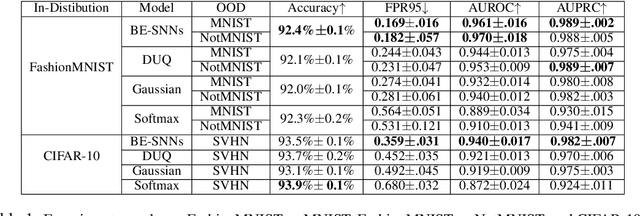
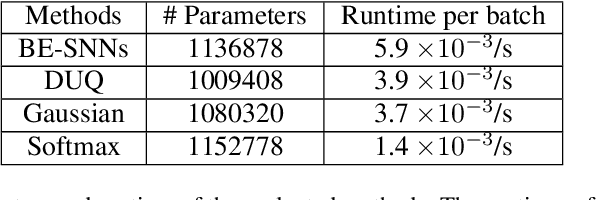
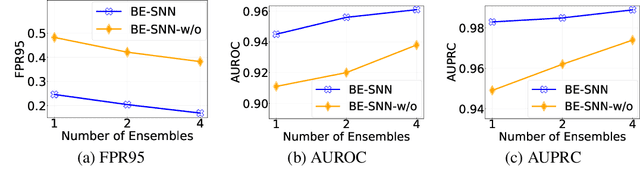
Out-of-distribution (OOD) detection has recently received much attention from the machine learning community due to its importance in deploying machine learning models in real-world applications. In this paper we propose an uncertainty quantification approach by modelling the distribution of features. We further incorporate an efficient ensemble mechanism, namely batch-ensemble, to construct the batch-ensemble stochastic neural networks (BE-SNNs) and overcome the feature collapse problem. We compare the performance of the proposed BE-SNNs with the other state-of-the-art approaches and show that BE-SNNs yield superior performance on several OOD benchmarks, such as the Two-Moons dataset, the FashionMNIST vs MNIST dataset, FashionMNIST vs NotMNIST dataset, and the CIFAR10 vs SVHN dataset.
Control Globally, Understand Locally: A Global-to-Local Hierarchical Graph Network for Emotional Support Conversation
Apr 27, 2022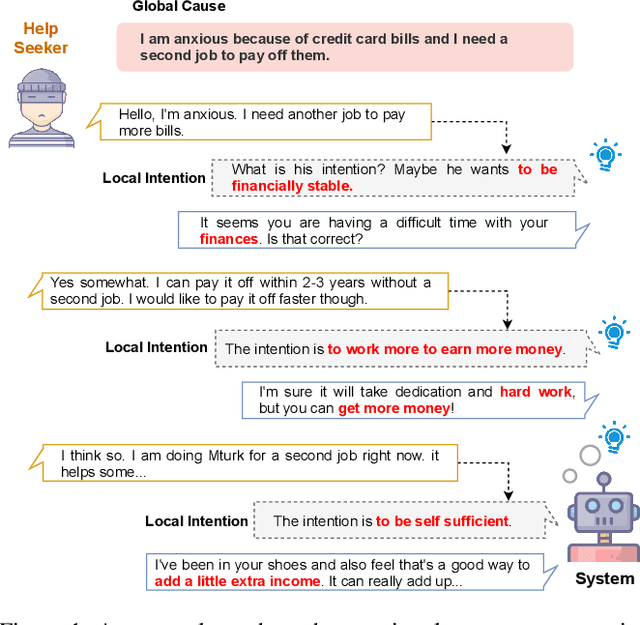
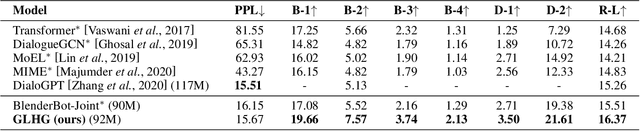
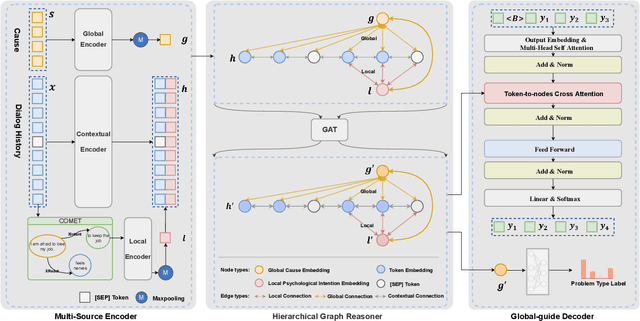
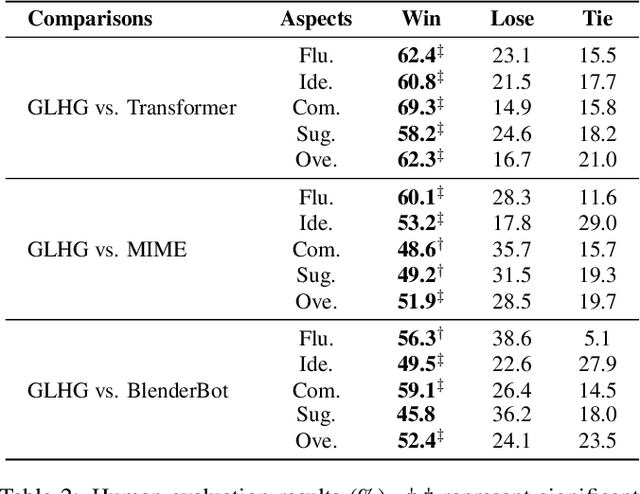
Emotional support conversation aims at reducing the emotional distress of the help-seeker, which is a new and challenging task. It requires the system to explore the cause of help-seeker's emotional distress and understand their psychological intention to provide supportive responses. However, existing methods mainly focus on the sequential contextual information, ignoring the hierarchical relationships with the global cause and local psychological intention behind conversations, thus leads to a weak ability of emotional support. In this paper, we propose a Global-to-Local Hierarchical Graph Network to capture the multi-source information (global cause, local intentions and dialog history) and model hierarchical relationships between them, which consists of a multi-source encoder, a hierarchical graph reasoner, and a global-guide decoder. Furthermore, a novel training objective is designed to monitor semantic information of the global cause. Experimental results on the emotional support conversation dataset, ESConv, confirm that the proposed GLHG has achieved the state-of-the-art performance on the automatic and human evaluations.
Conditional Measurement Density Estimation in Sequential Monte Carlo via Normalizing Flow
Mar 16, 2022
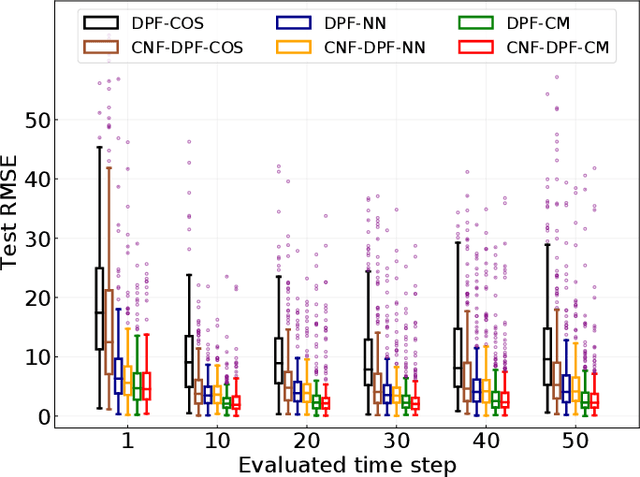
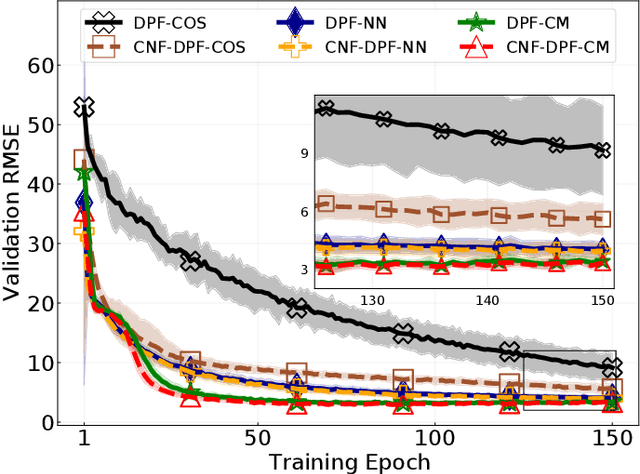
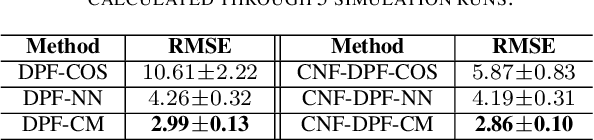
Tuning of measurement models is challenging in real-world applications of sequential Monte Carlo methods. Recent advances in differentiable particle filters have led to various efforts to learn measurement models through neural networks. But existing approaches in the differentiable particle filter framework do not admit valid probability densities in constructing measurement models, leading to incorrect quantification of the measurement uncertainty given state information. We propose to learn expressive and valid probability densities in measurement models through conditional normalizing flows, to capture the complex likelihood of measurements given states. We show that the proposed approach leads to improved estimation performance and faster training convergence in a visual tracking experiment.
Real time spectrogram inversion on mobile phone
Mar 10, 2022
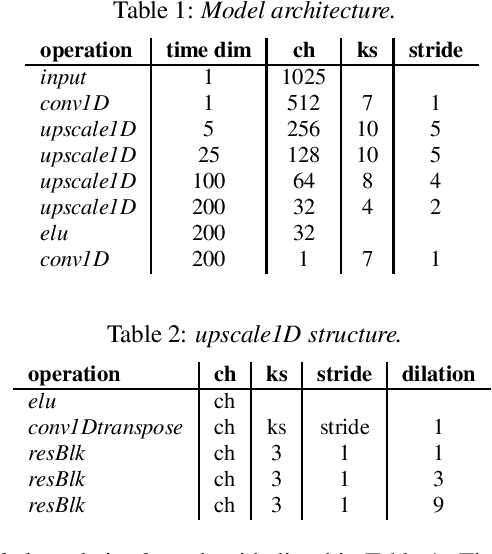
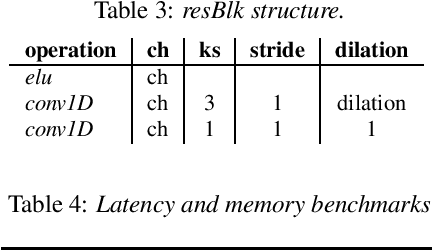

With the growth of computing power on mobile phones and privacy concerns over user's data, on-device real time speech processing has become an important research topic. In this paper, we focus on methods for real time spectrogram inversion, where an algorithm receives a portion of the input signal (e.g., one frame) and processes it incrementally, i.e., operating in streaming mode. We present a real time Griffin Lim(GL) algorithm using a sliding window approach in STFT domain. The proposed algorithm is 2.4x faster than real time on the ARM CPU of a Pixel4. In addition we explore a neural vocoder operating in streaming mode and demonstrate the impact of looking ahead on perceptual quality. As little as one hop size (12.5ms) of lookahead is able to significantly improve perceptual quality in comparison to a causal model. We compare GL with the neural vocoder and show different trade-offs in terms of perceptual quality, on-device latency, algorithmic delay, memory footprint and noise sensitivity. For fair quality assessment of the GL approach, we use input log magnitude spectrogram without mel transformation. We evaluate presented real time spectrogram inversion approaches on clean, noisy and atypical speech.
CLSEG: Contrastive Learning of Story Ending Generation
Feb 18, 2022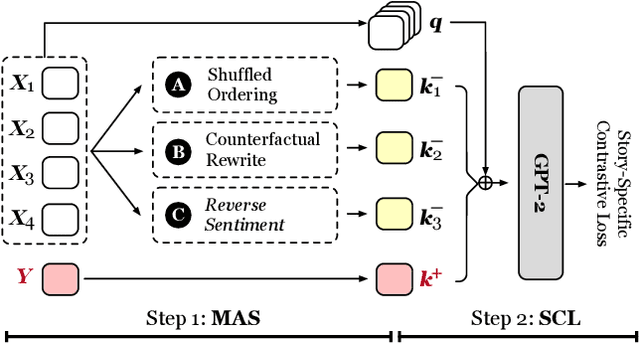

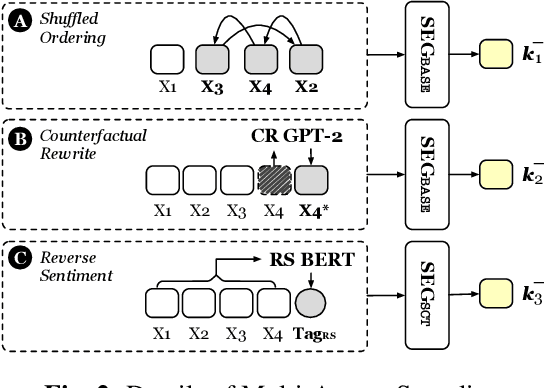
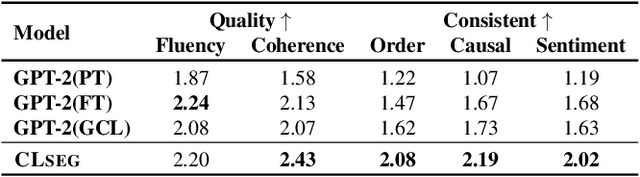
Story Ending Generation (SEG) is a challenging task in natural language generation. Recently, methods based on Pre-trained Language Models (PLM) have achieved great prosperity, which can produce fluent and coherent story endings. However, the pre-training objective of PLM-based methods is unable to model the consistency between story context and ending. The goal of this paper is to adopt contrastive learning to generate endings more consistent with story context, while there are two main challenges in contrastive learning of SEG. First is the negative sampling of wrong endings inconsistent with story contexts. The second challenge is the adaptation of contrastive learning for SEG. To address these two issues, we propose a novel Contrastive Learning framework for Story Ending Generation (CLSEG), which has two steps: multi-aspect sampling and story-specific contrastive learning. Particularly, for the first issue, we utilize novel multi-aspect sampling mechanisms to obtain wrong endings considering the consistency of order, causality, and sentiment. To solve the second issue, we well-design a story-specific contrastive training strategy that is adapted for SEG. Experiments show that CLSEG outperforms baselines and can produce story endings with stronger consistency and rationality.
Boosting Independent Component Analysis
Dec 18, 2021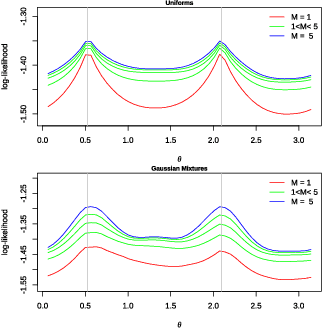

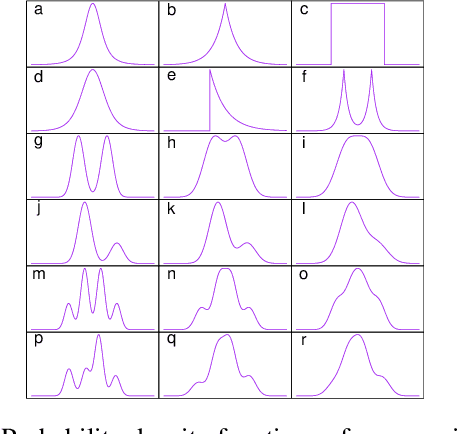
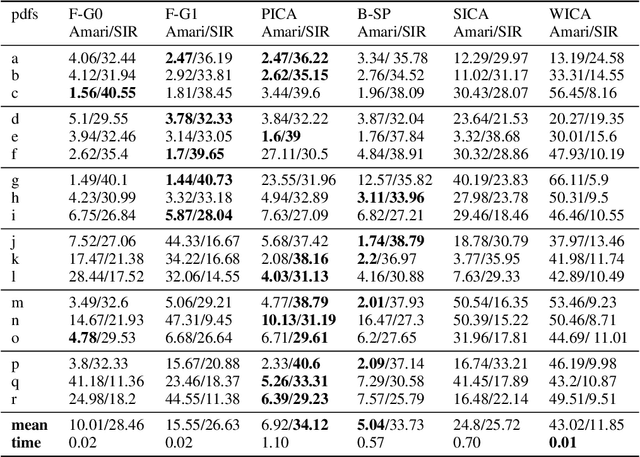
Independent component analysis is intended to recover the unknown components as independent as possible from their linear mixtures. This technique has been widely used in many fields, such as data analysis, signal processing, and machine learning. In this paper, we present a novel boosting-based algorithm for independent component analysis. Our algorithm fills the gap in the nonparametric independent component analysis by introducing boosting to maximum likelihood estimation. A variety of experiments validate its performance compared with many of the presently known algorithms.
HumBugDB: A Large-scale Acoustic Mosquito Dataset
Oct 14, 2021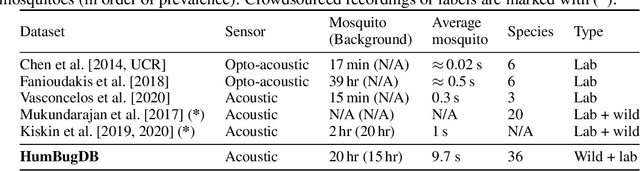
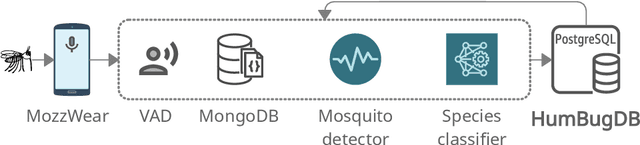
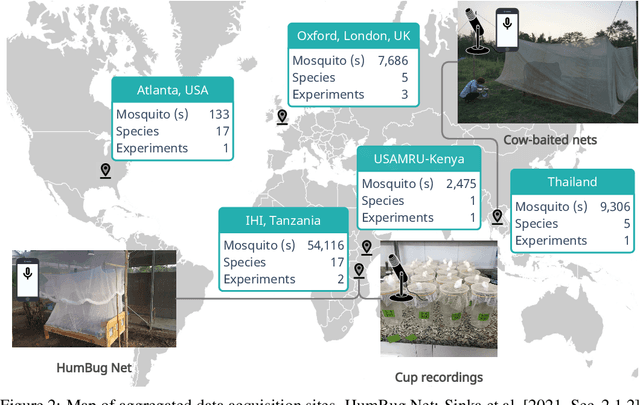
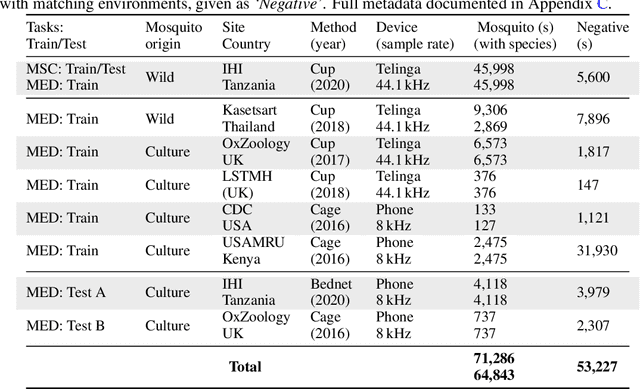
This paper presents the first large-scale multi-species dataset of acoustic recordings of mosquitoes tracked continuously in free flight. We present 20 hours of audio recordings that we have expertly labelled and tagged precisely in time. Significantly, 18 hours of recordings contain annotations from 36 different species. Mosquitoes are well-known carriers of diseases such as malaria, dengue and yellow fever. Collecting this dataset is motivated by the need to assist applications which utilise mosquito acoustics to conduct surveys to help predict outbreaks and inform intervention policy. The task of detecting mosquitoes from the sound of their wingbeats is challenging due to the difficulty in collecting recordings from realistic scenarios. To address this, as part of the HumBug project, we conducted global experiments to record mosquitoes ranging from those bred in culture cages to mosquitoes captured in the wild. Consequently, the audio recordings vary in signal-to-noise ratio and contain a broad range of indoor and outdoor background environments from Tanzania, Thailand, Kenya, the USA and the UK. In this paper we describe in detail how we collected, labelled and curated the data. The data is provided from a PostgreSQL database, which contains important metadata such as the capture method, age, feeding status and gender of the mosquitoes. Additionally, we provide code to extract features and train Bayesian convolutional neural networks for two key tasks: the identification of mosquitoes from their corresponding background environments, and the classification of detected mosquitoes into species. Our extensive dataset is both challenging to machine learning researchers focusing on acoustic identification, and critical to entomologists, geo-spatial modellers and other domain experts to understand mosquito behaviour, model their distribution, and manage the threat they pose to humans.