 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting semi-supervised training objectives for differentiable particle filters
May 02, 2024

Differentiable particle filters combine the flexibility of neural networks with the probabilistic nature of sequential Monte Carlo methods. However, traditional approaches rely on the availability of labelled data, i.e., the ground truth latent state information, which is often difficult to obtain in real-world applications. This paper compares the effectiveness of two semi-supervised training objectives for differentiable particle filters. We present results in two simulated environments where labelled data are scarce.
Normalising Flow-based Differentiable Particle Filters
Mar 03, 2024



Recently, there has been a surge of interest in incorporating neural networks into particle filters, e.g. differentiable particle filters, to perform joint sequential state estimation and model learning for non-linear non-Gaussian state-space models in complex environments. Existing differentiable particle filters are mostly constructed with vanilla neural networks that do not allow density estimation. As a result, they are either restricted to a bootstrap particle filtering framework or employ predefined distribution families (e.g. Gaussian distributions), limiting their performance in more complex real-world scenarios. In this paper we present a differentiable particle filtering framework that uses (conditional) normalising flows to build its dynamic model, proposal distribution, and measurement model. This not only enables valid probability densities but also allows the proposed method to adaptively learn these modules in a flexible way, without being restricted to predefined distribution families. We derive the theoretical properties of the proposed filters and evaluate the proposed normalising flow-based differentiable particle filters' performance through a series of numerical experiments.
StreamVC: Real-Time Low-Latency Voice Conversion
Jan 05, 2024We present StreamVC, a streaming voice conversion solution that preserves the content and prosody of any source speech while matching the voice timbre from any target speech. Unlike previous approaches, StreamVC produces the resulting waveform at low latency from the input signal even on a mobile platform, making it applicable to real-time communication scenarios like calls and video conferencing, and addressing use cases such as voice anonymization in these scenarios. Our design leverages the architecture and training strategy of the SoundStream neural audio codec for lightweight high-quality speech synthesis. We demonstrate the feasibility of learning soft speech units causally, as well as the effectiveness of supplying whitened fundamental frequency information to improve pitch stability without leaking the source timbre information.
Learning Differentiable Particle Filter on the Fly
Dec 16, 2023


Differentiable particle filters are an emerging class of sequential Bayesian inference techniques that use neural networks to construct components in state space models. Existing approaches are mostly based on offline supervised training strategies. This leads to the delay of the model deployment and the obtained filters are susceptible to distribution shift of test-time data. In this paper, we propose an online learning framework for differentiable particle filters so that model parameters can be updated as data arrive. The technical constraint is that there is no known ground truth state information in the online inference setting. We address this by adopting an unsupervised loss to construct the online model updating procedure, which involves a sequence of filtering operations for online maximum likelihood-based parameter estimation. We empirically evaluate the effectiveness of the proposed method, and compare it with supervised learning methods in simulation settings including a multivariate linear Gaussian state-space model and a simulated object tracking experiment.
Guided Speech Enhancement Network
Mar 13, 2023High quality speech capture has been widely studied for both voice communication and human computer interface reasons. To improve the capture performance, we can often find multi-microphone speech enhancement techniques deployed on various devices. Multi-microphone speech enhancement problem is often decomposed into two decoupled steps: a beamformer that provides spatial filtering and a single-channel speech enhancement model that cleans up the beamformer output. In this work, we propose a speech enhancement solution that takes both the raw microphone and beamformer outputs as the input for an ML model. We devise a simple yet effective training scheme that allows the model to learn from the cues of the beamformer by contrasting the two inputs and greatly boost its capability in spatial rejection, while conducting the general tasks of denoising and dereverberation. The proposed solution takes advantage of classical spatial filtering algorithms instead of competing with them. By design, the beamformer module then could be selected separately and does not require a large amount of data to be optimized for a given form factor, and the network model can be considered as a standalone module which is highly transferable independently from the microphone array. We name the ML module in our solution as GSENet, short for Guided Speech Enhancement Network. We demonstrate its effectiveness on real world data collected on multi-microphone devices in terms of the suppression of noise and interfering speech.
Differentiable Bootstrap Particle Filters for Regime-Switching Models
Feb 20, 2023



Differentiable particle filters are an emerging class of particle filtering methods that use neural networks to construct and learn parametric state-space models. In real-world applications, both the state dynamics and measurements can switch between a set of candidate models. For instance, in target tracking, vehicles can idle, move through traffic, or cruise on motorways, and measurements are collected in different geographical or weather conditions. This paper proposes a new differentiable particle filter for regime-switching state-space models. The method can learn a set of unknown candidate dynamic and measurement models and track the state posteriors. We evaluate the performance of the novel algorithm in relevant models, showing its great performance compared to other competitive algorithms.
An overview of differentiable particle filters for data-adaptive sequential Bayesian inference
Feb 19, 2023By approximating posterior distributions with weighted samples, particle filters (PFs) provide an efficient mechanism for solving non-linear sequential state estimation problems. While the effectiveness of particle filters has been recognised in various applications, the performance of particle filters relies on the knowledge of dynamic models and measurement models, and the construction of effective proposal distributions. An emerging trend in designing particle filters is the differentiable particle filters (DPFs). By constructing particle filters' components through neural networks and optimising them by gradient descent, differentiable particle filters are a promising computational tool to perform inference for sequence data in complex high-dimensional tasks such as vision-based robot localisation. In this paper, we provide a review of recent advances in differentiable particle filters and their applications. We place special emphasis on different design choices of key components of differentiable particle filters, including dynamic models, measurement models, proposal distributions, optimisation objectives, and differentiable resampling techniques.
Particle Flow Gaussian Sum Particle Filter
Nov 09, 2022



Particle flow Gaussian particle flow (PFGPF) uses an invertible particle flow to generate a proposal density. It approximates the predictive and posterior distributions as Gaussian densities. In this paper, we use bank of PFGPF filters to construct a Particle flow Gaussian sum particle filter (PFGSPF), which approximates the predictive and posterior as Gaussian mixture model. This approximation is useful in complex estimation problems where a single Gaussian approximation is not sufficient. We compare the performance of this proposed filter with PFGPF and others in challenging numerical simulations.
FADO: Feedback-Aware Double COntrolling Network for Emotional Support Conversation
Nov 01, 2022Emotional Support Conversation (ESConv) aims to reduce help-seekers'emotional distress with the supportive strategy and response. It is essential for the supporter to select an appropriate strategy with the feedback of the help-seeker (e.g., emotion change during dialog turns, etc) in ESConv. However, previous methods mainly focus on the dialog history to select the strategy and ignore the help-seeker's feedback, leading to the wrong and user-irrelevant strategy prediction. In addition, these approaches only model the context-to-strategy flow and pay less attention to the strategy-to-context flow that can focus on the strategy-related context for generating the strategy-constrain response. In this paper, we propose a Feedback-Aware Double COntrolling Network (FADO) to make a strategy schedule and generate the supportive response. The core module in FADO consists of a dual-level feedback strategy selector and a double control reader. Specifically, the dual-level feedback strategy selector leverages the turn-level and conversation-level feedback to encourage or penalize strategies. The double control reader constructs the novel strategy-to-context flow for generating the strategy-constrain response. Furthermore, a strategy dictionary is designed to enrich the semantic information of the strategy and improve the quality of strategy-constrain response. Experimental results on ESConv show that the proposed FADO has achieved the state-of-the-art performance in terms of both strategy selection and response generation. Our code is available at https://github/after/reviewing.
Psychology-guided Controllable Story Generation
Oct 14, 2022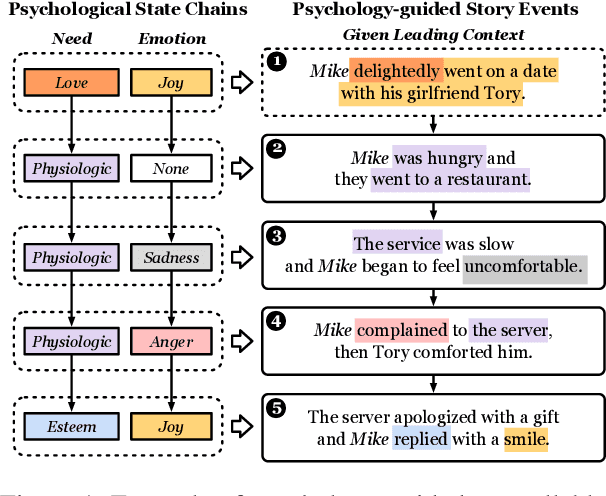

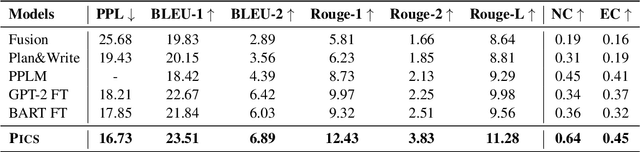
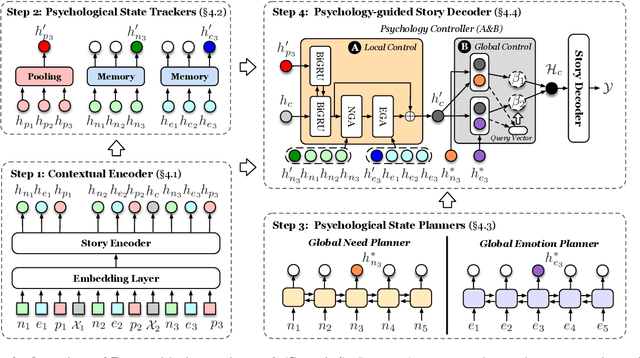
Controllable story generation is a challenging task in the field of NLP, which has attracted increasing research interest in recent years. However, most existing works generate a whole story conditioned on the appointed keywords or emotions, ignoring the psychological changes of the protagonist. Inspired by psychology theories, we introduce global psychological state chains, which include the needs and emotions of the protagonists, to help a story generation system create more controllable and well-planned stories. In this paper, we propose a Psychology-guIded Controllable Story Generation System (PICS) to generate stories that adhere to the given leading context and desired psychological state chains for the protagonist. Specifically, psychological state trackers are employed to memorize the protagonist's local psychological states to capture their inner temporal relationships. In addition, psychological state planners are adopted to gain the protagonist's global psychological states for story planning. Eventually, a psychology controller is designed to integrate the local and global psychological states into the story context representation for composing psychology-guided stories. Automatic and manual evaluations demonstrate that PICS outperforms baselines, and each part of PICS shows effectiveness for writing stories with more consistent psychological changes.