 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art of Tool Interface Design
Mar 26, 2025We present an agentic framework, Thinker, which achieves state of art performance in challenging reasoning tasks for realistic customer service scenarios that involve complex business logic and human interactions via long horizons. On the $\tau$-bench retail dataset, Thinker achieves 82.6\% success rate with GPT-4o (version 2024-06-01) (baseline: 68.3\%), and 81.9\% success rate with Llama-3.1 405B (baseline: 49.6\%), without any fine-tuning. Thinker effectively closes the gap in reasoning capabilities between the base models by introducing proper structure. The key features of the Thinker framework are: (1) State-Machine Augmented Generation (SMAG), which represents business logic as state machines and the LLM uses state machines as tools. (2) Delegation of tasks from the main reasoning loop to LLM-powered tools. (3) Adaptive context management. Our prompting-only solution achieves signficant gains, while still maintaining a standard agentic architecture with a ReAct style reasoning loop. The key is to innovate on the tool interface design, as exemplified by SMAG and the LLM-powered tools.
RN-SDEs: Limited-Angle CT Reconstruction with Residual Null-Space Diffusion Stochastic Differential Equations
Sep 20, 2024Computed tomography is a widely used imaging modality with applications ranging from medical imaging to material analysis. One major challenge arises from the lack of scanning information at certain angles, leading to distorted CT images with artifacts. This results in an ill-posed problem known as the Limited Angle Computed Tomography (LACT) reconstruction problem. To address this problem, we propose Residual Null-Space Diffusion Stochastic Differential Equations (RN-SDEs), which are a variant of diffusion models that characterize the diffusion process with mean-reverting (MR) stochastic differential equations. To demonstrate the generalizability of RN-SDEs, our experiments are conducted on two different LACT datasets, i.e., ChromSTEM and C4KC-KiTS. Through extensive experiments, we show that by leveraging learned Mean-Reverting SDEs as a prior and emphasizing data consistency using Range-Null Space Decomposition (RNSD) based rectification, RN-SDEs can restore high-quality images from severe degradation and achieve state-of-the-art performance in most LACT tasks. Additionally, we present a quantitative comparison of computational complexity and runtime efficiency, highlighting the superior effectiveness of our proposed approach.
Scaling User Modeling: Large-scale Online User Representations for Ads Personalization in Meta
Nov 16, 2023



Effective user representations are pivotal in personalized advertising. However, stringent constraints on training throughput, serving latency, and memory, often limit the complexity and input feature set of online ads ranking models. This challenge is magnified in extensive systems like Meta's, which encompass hundreds of models with diverse specifications, rendering the tailoring of user representation learning for each model impractical. To address these challenges, we present Scaling User Modeling (SUM), a framework widely deployed in Meta's ads ranking system, designed to facilitate efficient and scalable sharing of online user representation across hundreds of ads models. SUM leverages a few designated upstream user models to synthesize user embeddings from massive amounts of user features with advanced modeling techniques. These embeddings then serve as inputs to downstream online ads ranking models, promoting efficient representation sharing. To adapt to the dynamic nature of user features and ensure embedding freshness, we designed SUM Online Asynchronous Platform (SOAP), a latency free online serving system complemented with model freshness and embedding stabilization, which enables frequent user model updates and online inference of user embeddings upon each user request. We share our hands-on deployment experiences for the SUM framework and validate its superiority through comprehensive experiments. To date, SUM has been launched to hundreds of ads ranking models in Meta, processing hundreds of billions of user requests daily, yielding significant online metric gains and infrastructure cost savings.
$AIR^2$ for Interaction Prediction
Nov 16, 2021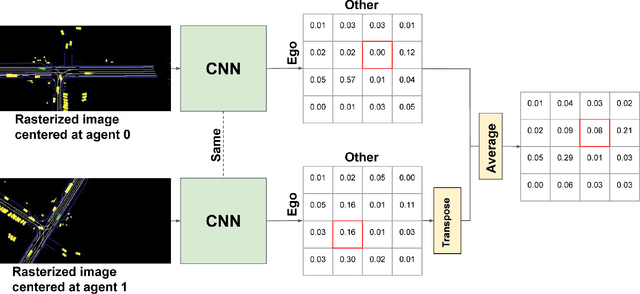

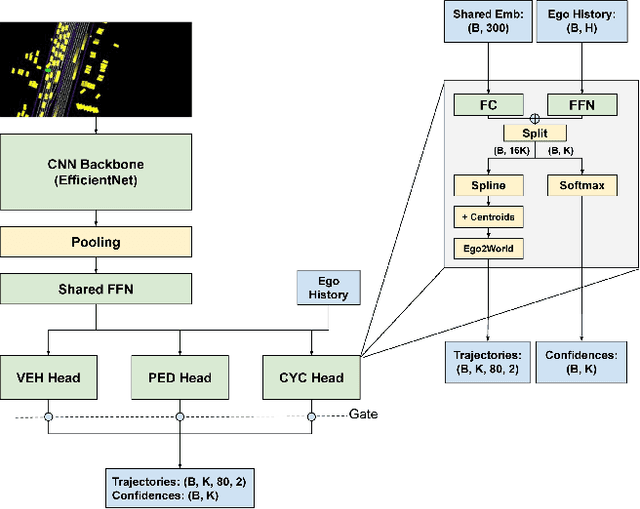
The 2021 Waymo Interaction Prediction Challenge introduced a problem of predicting the future trajectories and confidences of two interacting agents jointly. We developed a solution that takes an anchored marginal motion prediction model with rasterization and augments it to model agent interaction. We do this by predicting the joint confidences using a rasterized image that highlights the ego agent and the interacting agent. Our solution operates on the cartesian product space of the anchors; hence the $"^2"$ in $AIR^2$. Our model achieved the highest mAP (the primary metric) on the leaderboard.
QK Iteration: A Self-Supervised Representation Learning Algorithm for Image Similarity
Nov 15, 2021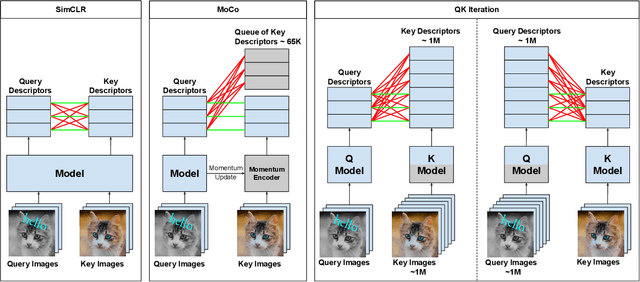
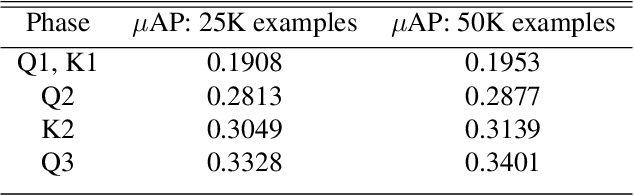
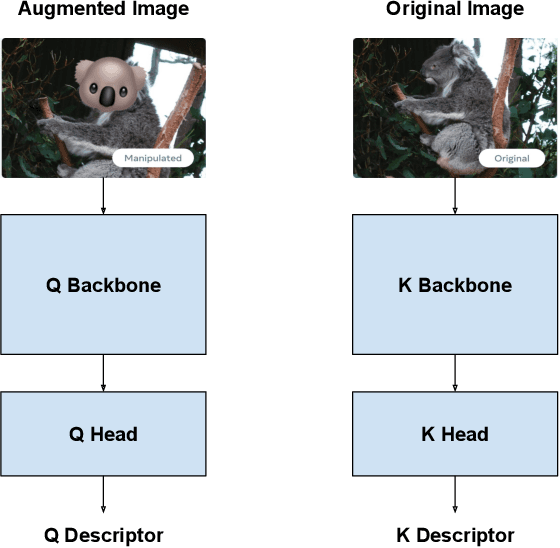
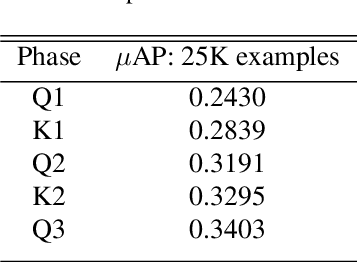
Self-supervised representation learning is a fundamental problem in computer vision with many useful applications (e.g., image search, instance level recognition, copy detection). In this paper we present a new contrastive self-supervised representation learning algorithm in the context of Copy Detection in the 2021 Image Similarity Challenge hosted by Facebook AI Research. Previous work in contrastive self-supervised learning has identified the importance of being able to optimize representations while ``pushing'' against a large number of negative examples. Representative previous solutions either use large batches enabled by modern distributed training systems or maintain queues or memory banks holding recently evaluated representations while relaxing some consistency properties. We approach this problem from a new angle: We directly learn a query model and a key model jointly and push representations against a very large number (e.g., 1 million) of negative representations in each SGD step. We achieve this by freezing the backbone on one side and by alternating between a Q-optimization step and a K-optimization step. During the competition timeframe, our algorithms achieved a micro-AP score of 0.3401 on the Phase 1 leaderboard, significantly improving over the baseline $\mu$AP of 0.1556. On the final Phase 2 leaderboard, our model scored 0.1919, while the baseline scored 0.0526. Continued training yielded further improvement. We conducted an empirical study to compare the proposed approach with a SimCLR style strategy where the negative examples are taken from the batch only. We found that our method ($\mu$AP of 0.3403) significantly outperforms this SimCLR-style baseline ($\mu$AP of 0.2001).